本文主要是介绍从GAN到WGAN及WGAN-GP,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
20200910 -
0. 引言
最近看了PassGAN的代码,他是使用了WGAN-GP的代码作为GAN的框架,来进行密码生成,由此引出了对GAN的学习。在GAN的研究中,有一个方向就是研究如何使GAN更加稳定的训练。在此之中,WGAN和WGAN-GP算是比较好的解决方案。
为了弄明白这些东西,也是花费了很长时间,主要是因为这部分都是数学公式的内容,而我这种半吊子也不是搞数学的,也不是专门搞人工智能的,就顺着他们的思路弄明白是怎么回事就好了,对于数学原理还是看看就好了。
本篇文章主要是参考了几篇文章,然后结合PassGAN的代码部分来理解就好了。
1. 整体的学习脉络
正好这几天的学习过程中,也对GAN有了新的认识,或者说更深层次的认识。这里就记录一下,如果是把这部分内容给忘记了,怎么重新捡起来。
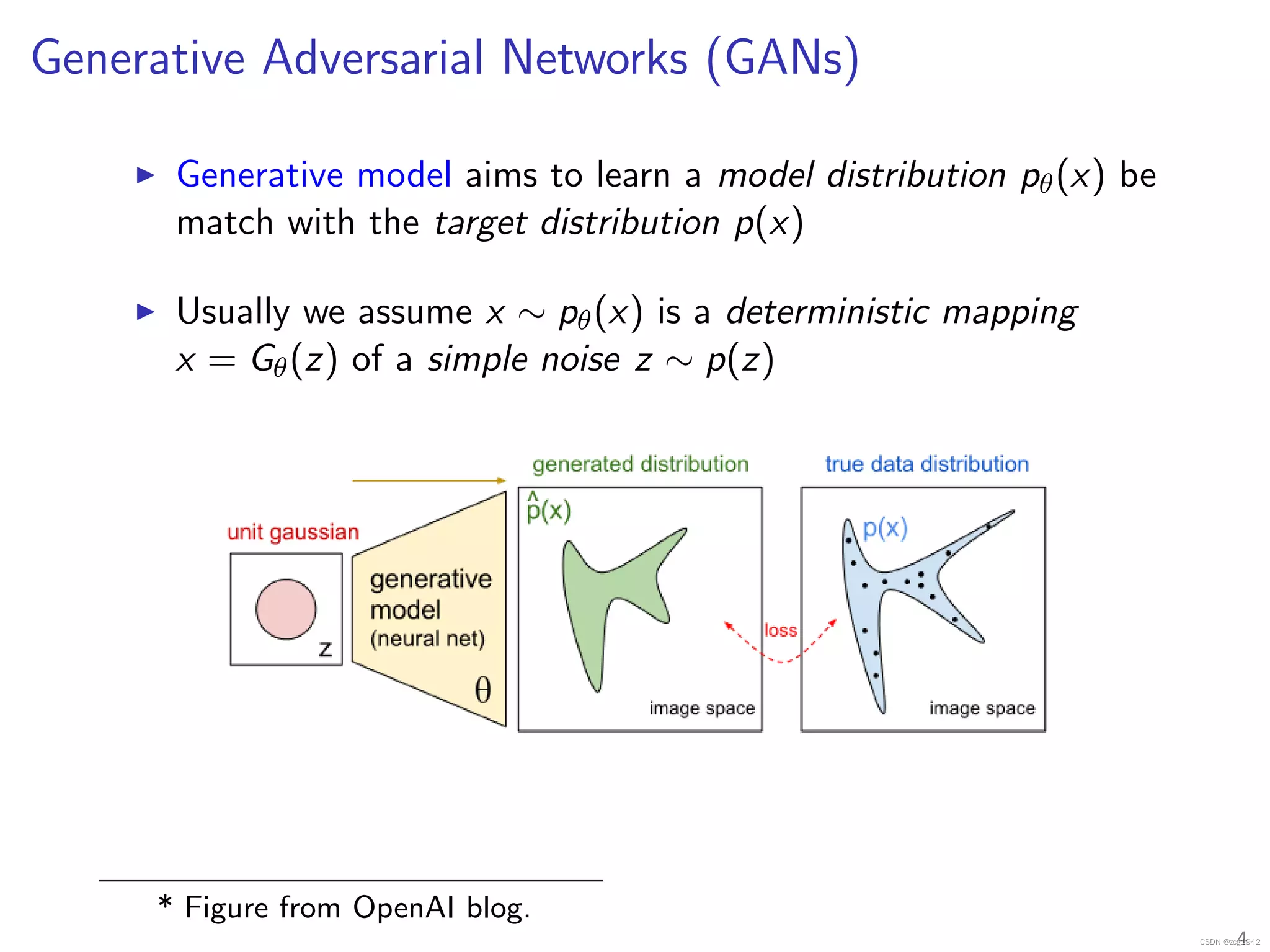
1.1 GAN基本原理
在该部分要明白,GAN的对抗过程是什么意思,明白两个网络的损失函数分别是怎么作用的。
这里可以参看之前的文章《GAN的编写 - tensorflow形式(tensorflow与GAN同学习,重点分析训练过程)》,写的不是很好,但是重点是思考的过程。
1.2 GAN的编写过程
编写过程分为两部分,一个是keras框架,一个是tensorflow框架。
- keras框架可以查看《GAN的学习 - 训练过程(冻结判别器)》,这部分重点关注冻结判别器的过程。
- tensorflow查看《Generative Adversarial Nets in TensorFlow》,内容相对来说比较简单,而前面的文章《GAN的编写 - tensorflow形式(tensorflow与GAN同学习,重点分析训练过程)》正是分析了其中的一些一开始不理解的地方。
keras和tensorflow的编程方式差别很大,tensorflow可以直接操作损失函数,且通过不同的输入来控制判别器的冻结。这里多提一嘴,那就是log(D_fake)的问题,这种方式在GAN的原始论文中也提出了,同时也能从逻辑上推理成功,所以不用质疑这个东西的正确性,重点多重复他这个对抗性的思考。
后面就开始记录最近看的内容,其实,仔细阅读他们文章中使用的伪代码图片(论文中),是能大致明白主要的思路的。
1.3 WGAN的学习
WGAN是学习优化GAN训练过程的第一步,在这个学习过程中,并没有去参考原始论文,而是直接学习了文章中的说法,但是实际上如果想深入理解这部分内容,必然是应该通过阅读论文的方式来进行学习。其中主要参考了文章《From GAN to WGAN》[1],这篇文章的内容要我说,我是理解不了,虽然顺着思路能够明白是这么一个道理,但是在后面流式学习的部分,就已经不明白了。配合着另外一篇文章
《GAN — Wasserstein GAN & WGAN-GP》[2],基本上算是理解了。然后结合《Wasserstein GAN implementation in TensorFlow and Pytorch》中的代码,可以同代码的角度来理解这部分内容。
1.4 WGAN-GP的学习
这部分还是参考了文章[2]的内容,同时结合学习了[4]的代码,算是简单明白了。但深层次的数学原理还是理解不了,没办法哦。好了,下面就开始学习具体的内容。
2. WGAN的学习
在学习WGAN之前,不管是[1],还是[2]都先说明了两个相似度度量公式:KL散度,JS散度;而WGAN正是将利用JS散度的GAN转化到了EM距离。这里还是要解释一下,我在文章[1]中的分析得出的结论是,GAN利用JS散度只是在判别器达到最优的时候是能够用JS来进行解释的,所以,是不是其他的地方也可以利用JS散度来解释,我不是很明白。(这部分是需要后续研究的过程)。
在原始的损失函数中,如果判别器达到了最优,其可以写成为下面的公式。

当然,最后的时候,如果是生成器也是最优的,那么损失函数就是-2log2。
原始GAN的主要问题,梯度消失的问题,此时对生成器的部分就很难训练,特别是当判别器的性能比较好的时候。所以为了更好的训练GAN,WGAN被提出来。
WGAN,以Wasserstein距离作为损失函数的GAN。文章[1-2]在讲解EM距离的距离的时候,都是通过一个离散的移动变量的方式来展示的,当然连续状态下也是可行的,最终的表现形式如下。

该公式定义了两个概率曲线之间的最小值下界。而Wasserstein距离效果能够比JS或者KL散度效果好的原因,就是他能持续提供一个平滑的梯度曲线。后面来讲一下到底WGAN是怎么应用起来的。
上面这个公式需要遍历所有的频率分布来计算最小值,显然是不可行的,WGAN的论文作者提出了另外一种方案,通过Kantorovich-Rubinstein二元性进行转换:

这种方式定义了一个上限来作为距离函数,而上式中,需要满足
即:

而此时原始的GAN中的判别器就换了一个身份,其不再是原始的进行分类的神经网络,而是为了学习上述f函数的一个神经网络,而改名为critic,其输出可以认为是生成图片的真实性大小。也就是说,critic变成了一个学习具备K -Lipschitz continuous性质的函数,所以损失函数就变成了Wasserstein距离。在训练过程中,为了保持K -Lipschitz continuous属性,在每次进行梯度更新后,都将权值w(critic的参数全定在了一个窗口内,例如[-0.01,0.01];同时为了更好的梯度更新,作者推荐使用RMSProp优化器。

下面来总结一下WGAN与原始GAN的不同:
1)在每次梯度更新权值时,将critic圈定在[-c,c]中
2)训练次数,多训练判别器几次,才训练生成器一次
3)使用新的损失函数,该损失函数没有了log,那么在critic输出部分,也就没有了sigmoid函数。
4)更换优化器为RMSProp
注:在一开始学习的过程中,一直没有注意到其将学习f的过程,变换为了critic的权值,也就导致了即使看了代码也不是很明白。现在大致知道了他的具体思路,所以再看[3]代码的时候,就更容易明白了。例如[3]中的代码,关于权值的部分:
# theta_D is list of D's params
clip_D = [p.assign(tf.clip_by_value(p, -0.01, 0.01)) for p in theta_D]
(上述代码在WGAN-GP中是另一种表现形式)
关于这部分,基本上算是顺着该部分思路走了下来,明白了代码各个部分都是干什么,但具体的数学原理不清楚,这个也没有办法。
3. WGAN-GP的学习
对于WGAN-GP的学习就集中在文章[2]上,这部分具体的内容就不展开了,最大的变化就是在损失函数上增加了一个惩罚项,这部分我在代码中也能看到相应的改变。

当时对着伪代码学习算法的时候,发现了一个不对的地方,实际代码[4]如下:
differences = fake_data - real_data
interpolates = real_data + (alpha*differences)
但代码好像是
differences = real_data - fake_data
interpolates = fake_data + (alpha*differences)
这个在[5]中有解答,这是因为两者都是一致的,因为都是随机产生的随机数。
4. 总结
关于GAN的学习就是这些,其中比较关键的是两个优化的内容,通过转换损失函数,使其具备平滑的梯度。但因为数学功底不好,特别是WGAN-GP的内容就更不用提了。但是还是建议,如果想深入理解,就把文章[1][2]好好读一读,即使没有办法彻底从数学上理解原理,也能够在代码上对应上关系。
参考
[1]From GAN to WGAN
[2]GAN — Wasserstein GAN & WGAN-GP
[3]Wasserstein GAN implementation in TensorFlow and Pytorch
[4]improved_wgan_training/gan_language.py
[5]Mismatch between code and paper in the gradient penalty algorithm #84
这篇关于从GAN到WGAN及WGAN-GP的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!