本文主要是介绍GAN:WGAN-GP-带有梯度惩罚的WGAN,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文:https://arxiv.org/pdf/1704.00028.pdf
代码:GitHub - igul222/improved_wgan_training: Code for reproducing experiments in "Improved Training of Wasserstein GANs"
发表:2017

WGAN三部曲的终章-WGAN-GP
摘要
WGAN在稳定训练GANs方面有一定的进展,但依然存在生成样本质量低、难以收敛等问题。主要原因是:采用了weight clipping。本文作者提出了gradient penalty (GP)来替代 w-c,有效的解决了WGAN存在的缺陷。同时本文也是第一个在很深的网络上(res101)成功训练GANS.

weight clipping缺陷:模型建模能力弱化,以及梯度爆炸或消失。

权重约束的难点
作者发现WGAN中的权重裁剪会导致优化困难,即使优化成功,也可能导致判别器具有病态的值表面。作者尝试了其他的权重约束方案:L2 norm clipping、weight normlization、以及L1和L2 权重衰减,都存在相似的问题,并不能解决问题。
作者同时发现在WGAN中:判别器中增加BN可以一定程度上缓解上述问题,但随着网络的加深,WGAN依然会面临难以收敛的困境。
权重分布问题
WGAN在训练过程中保证判别器的所有参数处于[-c, +c]的范围内,约束了判别器对相似样本有相似的结果。实际训练需求是希望判别器尽可能拉开真假样本的分数差,而weight-clipping限制了网络的参数范围,使得最优的策略是尽可能让所有参数拉开,要么取最大值c,要么取最小值-c。而g-p 的权重数值分布就比较正常。
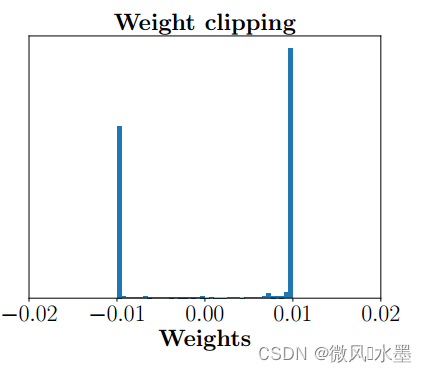
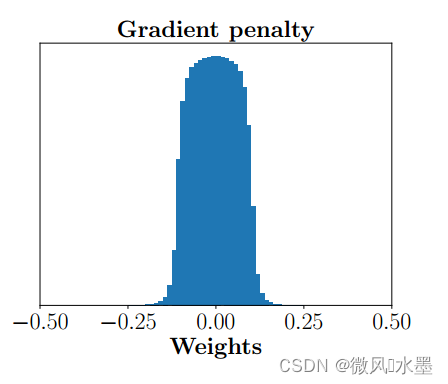

梯度回传问题
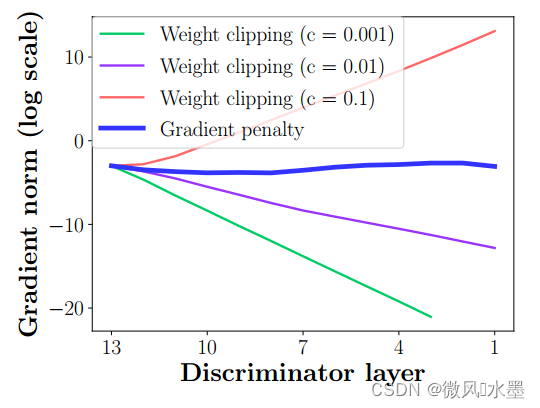
c-p另一个问题就是会导致梯度消失或者爆炸,如下图。判别器通常是一个多层网络,设想一下:
如果weight clipping 阈值设置的很小(比如下图中的c=0.001),每经过一层网络,保留的梯度就变小一点,多层之后,可能就会出现梯度消失的问题。
如果weight clipping 阈值设置的很大(比如下图中的c=0.1),每经过一层网络,保留的梯度就变大一点,多层之后,可能就会出现梯度爆炸的问题。
所以只有设置的不大不小,比如c=0.01(wgan作者推荐的数值),下图中的紫色线,梯度保持相对合理,才能让生成器获得不错的回传梯度。所以这个参数在实际应用中调试不容易把握。
本文提出的 g-p(图中蓝色线),不论判别器深度如何,梯度范数,都保持相对稳定,有效解决梯度消失和梯度爆炸的问题。

梯度惩罚
在原始判别器的损失上增加了一项惩罚,惩罚系数设置为10。经过验证,可以在各个框架和数据集上表现不错。
公式在下面, 里面表达的是它在WGAN的loss上加了一个惩罚项,如果判别器的 gradient 的 norm,离 1 越远,那么 loss 的惩罚力度越高。

算法流程

- 训练 n_critic=5 次判别器,训练1次生成器
- 训练判别器:
- 采样一次真实数据
和生成数据
,
- 将真实数据
比例叠加混合,得到
- 将
输入判别器,得到混合图片数据的梯度,对梯度计算 norm,看看这个 norm 离单位距离 1 有多远(离1越近,惩罚越小)
- 采样一次真实数据
对于上面第2点,为什么要用真假数据进行一个插值处理?这篇文章的解释: 要求 ‖T‖L ≤ 1 在每一处都成立,所以数据应该是全空间的均匀分布才行, 显然这很难做到。所以作者采用了一个非常机智(也有点流氓)的做法: 在真假样本之间随机插值来惩罚,这样保证真假样本之间的过渡区域满足 1-Lipschitz 约束。
移除判别器中BN
大多数GANs中在生成器和判别器中均使用BN,目的是稳住训练过程。但WGAN-GP中移除了判别器中的BN操作: 因为WGAN-gp的惩罚项计算中,惩罚的是单个数据的gradient norm,如果使用 batchNorm,就会扰乱这种惩罚,让这种特别的惩罚失效。作者发现移除后效果很好。除了移除BN外,也可以使用Layer normalization 来替代 batch normalization。

实验部分
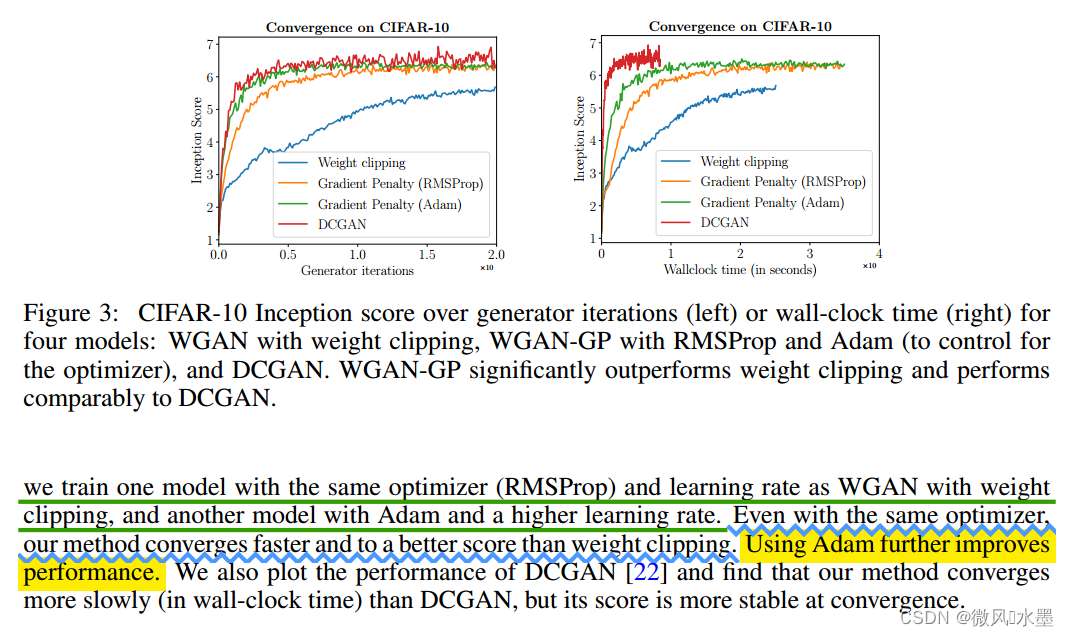
1:wgan-gp在各种架构和条件下都可以成功训练:有无BN,网络深度等


2:优化器选择:作者重新对比了Adam、RMSProp。发现基于wgan-gp架构,Adam表现的更好一些(这与wgan中是完全相反的)
代码学习
wgan:https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/wgan/wgan.py
wgan-gp:https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/wgan_gp/wgan_gp.py
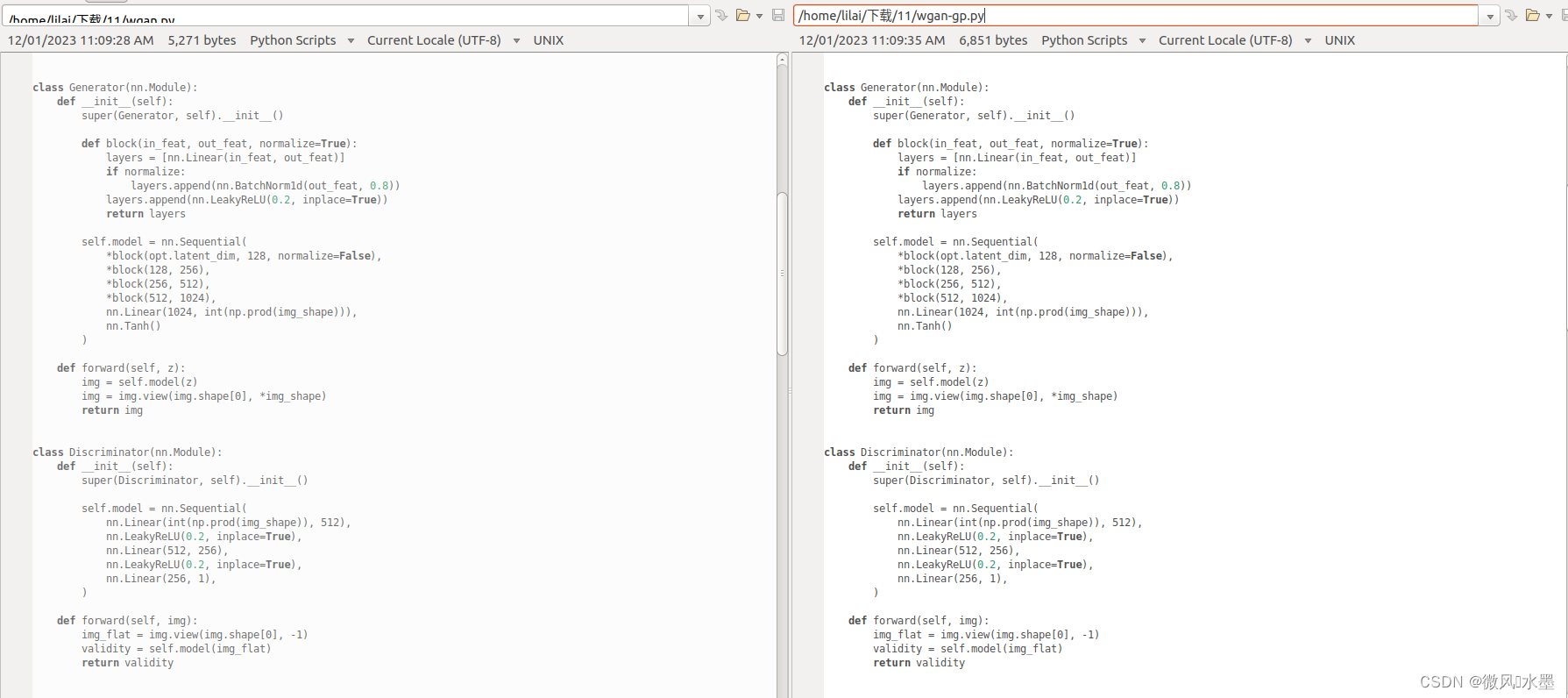
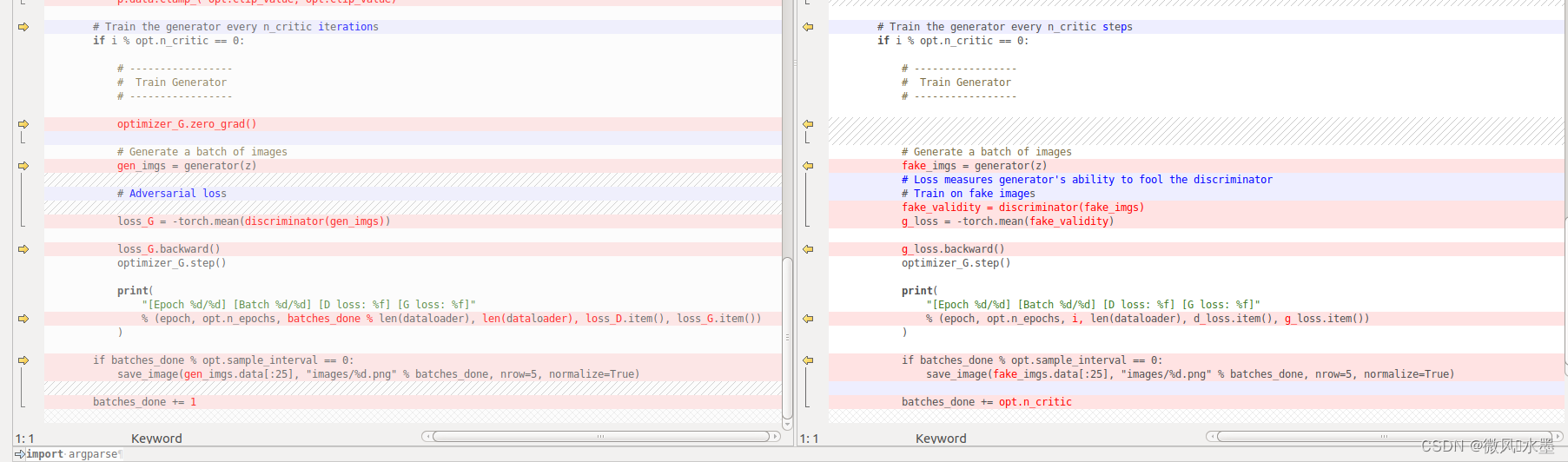
1:生成器和判别器没有变化 。这个代码里面是没有BN操作的。如果判别器有,最好是移除。
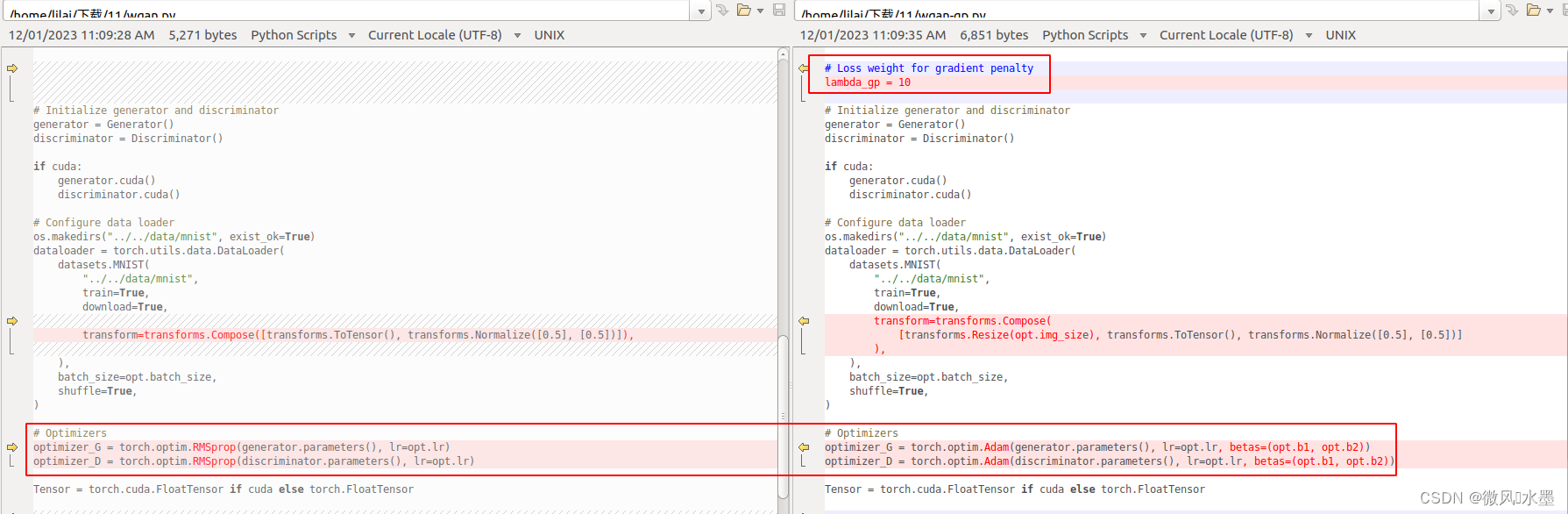
2:lambda_gp = 10 的参数。同时优化器换回了Adam,作者验证发现Adam还是比RMSprop优化器效果好一些。
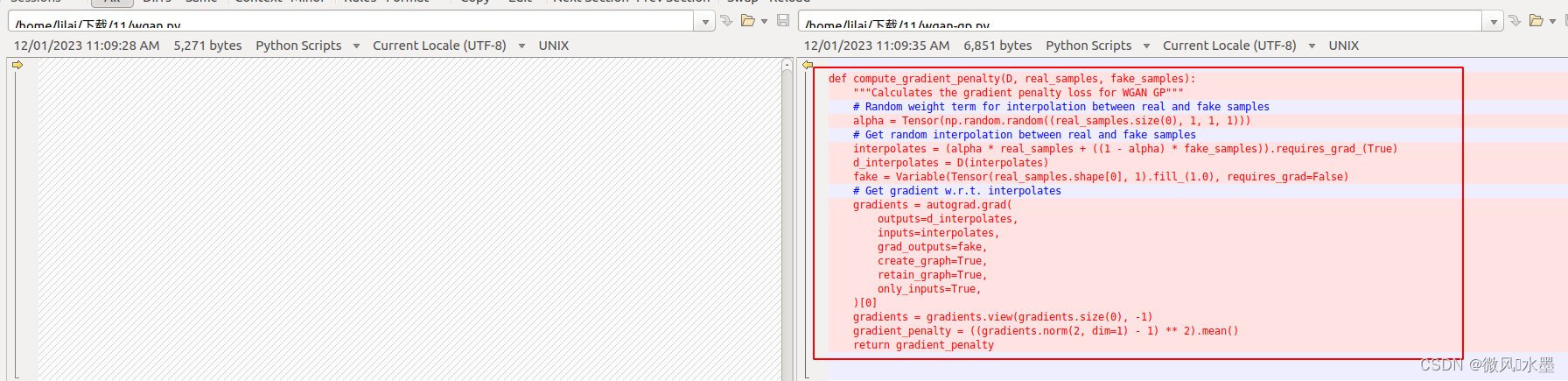
3:梯度惩罚的实现
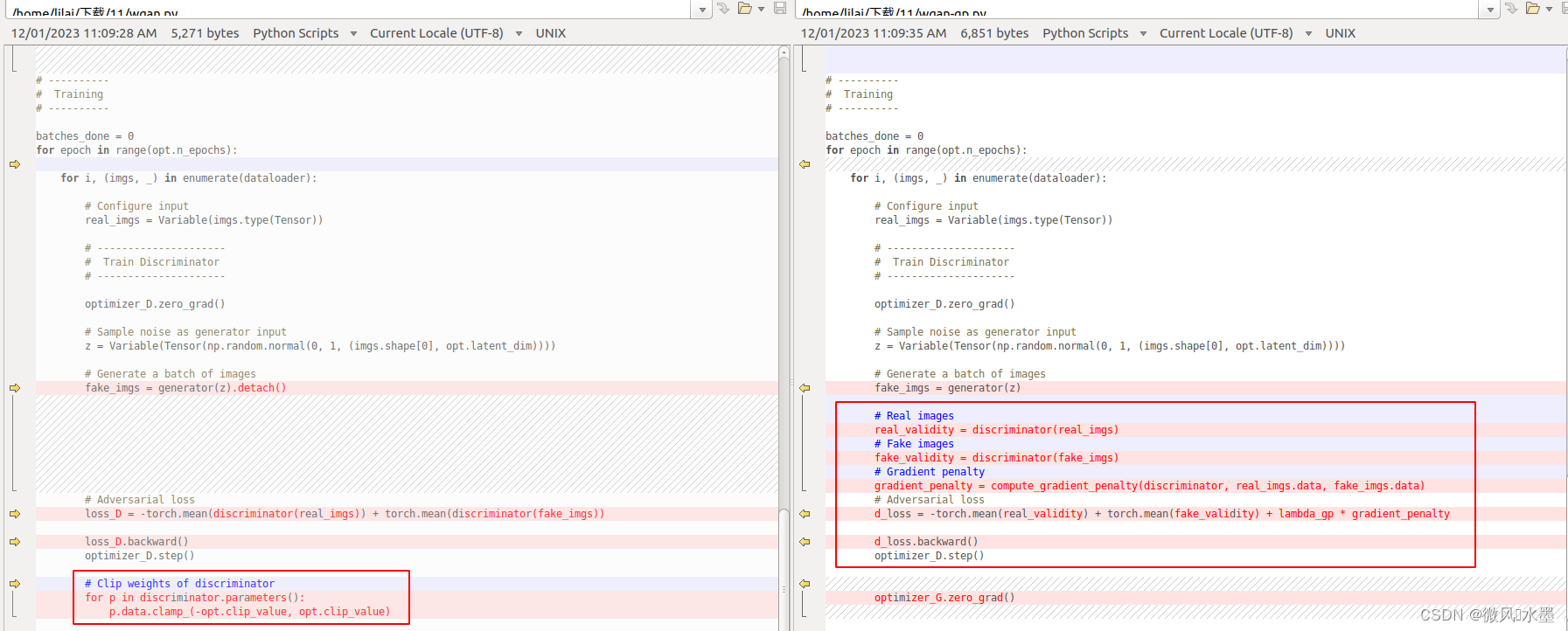
4:c-p和g-p的判别器实现
5:生成器实现,没有区别
参考
1:wgan笔记
2:wgan-gp
这篇关于GAN:WGAN-GP-带有梯度惩罚的WGAN的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







