tvm专题

【TVM 教程】在 Relay 中使用外部库
Apache TVM 是一个端到端的深度学习编译框架,适用于 CPU、GPU 和各种机器学习加速芯片。更多 TVM 中文文档可访问 → https://tvm.hyper.ai/ 作者:Masahiro Masuda,Truman Tian 本文介绍如何将 cuDNN 或 cuBLAS 等外部库与 Relay 一起使用。 Relay 内部用 TVM 来生成 target-specific 的

int8量化和tvm实现
量化主要有两种方案 直接训练量化模型如Deepcompression,Binary-Net,Tenary-Net,Dorefa-Net对训练好的float模型(以float32为例)直接进行量化(以int8为例),这边博客主要讲这个 参考NIVIDIA 量化官方文档 int8量化原理 将已有的float32型的数据改成A = scale_A * QA + bias_A,B类似,NVIDI
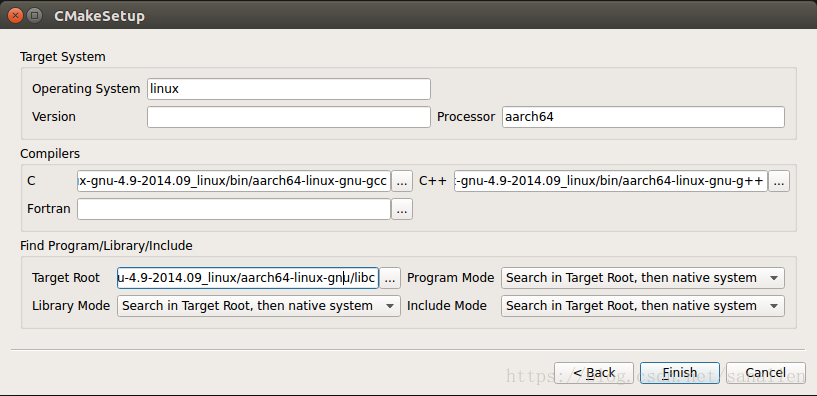
Insightface 之部署,TVM基础
参考文档 mxnet官方install手册TVM 0.4.0官方安装指导手册LLVM下载地址Debian/Ubuntu Linux下安装LLVM/Clang编译器 开发环境介绍 操作系统版本:Ubuntu16.04 LTS 64-bit,编译TVM的host、target版本;目标器件为Firefly-RK3399,采用双核Cortex-A72和四核Cortex-A53的大小核架构。MXNe
TVM insightface
https://github.com/markson14/Face-Recognition-Cpp 结合这个来看,初步看来后续可以做为公司的人脸开发base。 自从AI被炒作以来,各个深度学习框架层出不穷。我们通常来讲,作为AI从业者,我们通常经历着标注-训练-部署的过程。其中部署是较为痛苦的工作,尤其是在跨平台如(移动端需要native对接的时候。)当然用于inference框架同样也是层出不

TVM LLVM 加速AI
下面为记录人工智能推理加速过程,基于TVM 总体脉络: 1. TVM 安装 2. TVM 测试及使用 3. Auto TVM 使用 4. 编译导出 so/dll 5.在C++中调用生成的so/dll 零、什么是TVM TVM是apache基金会开放的人工智能模型编译框架,由华人 陈天琦博士 初始开发。陈博士本科毕业于上海交大ACM班,有极深的计算
TVM Object类型系统
在TVM Object类型系统中最重要的是三个类:Object、ObjectPtr、ObjectRef 为什么需要这三个类? 设计目的:为了能够在不更改python前端的情况下扩展c++中的语言对象,且能够对任何语言对象序列化。 Object:编译器中所有的语言对象(命名一般以Node结尾)都是Object的子类,Object的子类保存了一般保存了数据成员变量ObjectPtr:Object

[笔记]TVM部署AirFace
使用TVM在Tx2 Arm上部署AirFace c++ 目录前言自动优化终端测试 目录 前言 不要问为什么Tx2要用Arm核,它只是开发方便,习惯把它作工业母机罢了。 自动优化 TVM一个设计亮点在于他可以在PC端通过RPC优化网络,这个大大加快了优化速度。 虽说PC端加速优化过程,但是在实际使用中发现优化速度还是很慢的,也是一个炼丹过程。而且极端依赖CPU性能,在TVM
关于TVM模型的Relay IR的Node遍历
TVM Relay Node类型与遍历方法 目的二、步骤1.遍历方法2.关于节点类型 总结 目的 关于TVM模型的Relay IR的Node遍历 二、步骤 1.遍历方法 代码如下(示例): import tvmfrom tvm import relayfrom tvm.contrib.debugger import debug_executorimport nu

tvm android_rpc_test.py执行报错解决
执行 python3 tests/android_rpc_test.py 报错: Run CPU test ... Traceback (most recent call last): File "tests/android_rpc_test.py", line 129, in <module> test_rpc_module() File "tests/android_r

活动预告 | 2023 Meet TVM · 北京站定档,5 场 Talk 你最期待哪一场?
内容一览:2023 Meet TVM 线下聚会第二站定档 6 月 17 日!这次我们设定了 5 个 Talk,期待和大家在北京中关村相聚! 关键词:编译器 线下活动 2023MeetTVM 3 月 4 日, 2023 Meet TVM 首场线下活动在上海成功举办,百余位从事 AI 编译器开发、关注 TVM 发展的工程师齐聚五角场,进行了充分热烈的讨论和交流。 时隔 3 个多月,备受期待、
tvm交叉编译android可执行参考资料整理
主要参考这个: TVM部署神经网络模型到android端_tvm android-CSDN博客 其他相关链接: TVM部署神经网络模型到android端 - 代码先锋网 Ubuntu交叉编译 arm板子上的TVM_tvm arm-CSDN博客 TVM部署神经网络模型到android端 - 代码先锋网 tvm部署c++神经网络前向代码到android端_tvm安卓-CSDN博客

9.16 深圳腾讯大厦见!2023 Meet TVM 线下聚会定档
By 超神经 内容一览:2023 Meet TVM 线下聚会第 3 站将于 9 月 16 日在深圳腾讯大厦举办!本次 Meetup 包含 5 个关于 AI 编译器的精彩 talk,期待与大家在深圳相聚! 关键词:编译器 线下活动 2023MeetTVM 今年 3 月和 6 月,2023 Meet TVM 系列活动分别在上海和北京成功举办,300 余位来自各大厂商、科研院所的伙伴们齐聚一堂

【TVM系列教程一】深度学习编译器及TVM 介绍
0x0. 介绍 大家好呀,在过去的半年到一年时间里,我分享了一些算法解读,算法优化,模型转换相关的一些文章。这篇文章是自己开启学习深度学习编译器的第一篇文章,后续也会努力更新这个系列。这篇文章是开篇,所以我不会太深入讲解TVM的知识,更多的是介绍一下深度学习编译器和TVM是什么?以及为什么我要选择学习TVM,最后我也会给出一个让读者快速体验TVM效果的一个开发环境搭建的简要教程以及一个简单例子。

打破硬件壁垒:TVM 助力 AI技术跨平台部署
文章目录 《TVM编译器原理与实践》编辑推荐内容简介作者简介目录前言/序言获取方式 随着人工智能(Artificial Intelligence,AI)在全世界信息产业中的广泛应用,深度学习模型已经成为推动AI技术革命的关键。TensorFlow、PyTorch、MXNet、Caffe等深度学习模型已经在服务器级GPU上取得了显著的成果。然而,大多数现有的系统框架只针对小范围
tvm学习笔记(八):卷积操作
对于卷积神经网络中,卷积操作可能是最常见操作,具体原理可以去学习一下Andred NG的课程,建议搞计算机视觉方向的都去刷一波,具体过程如图1所示: 图1 'VALID'方式卷积操作过程 其实就是卷积核与图像待操作区域进行乘加操作,常见的卷积操作有两种形式,第一种是'VALID'的方式,如图1所示,第二种是'SAME'的方式,区别在于'SAME'方式会对输入进行填充,以保
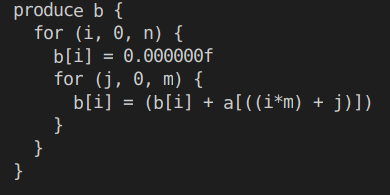
tvm学习笔记(七):简约操作
所谓Reduction(简约操作)其实就是说经过该操作之后,输入向量的维度会减小,例如,对输入向量沿着某个维度进行求和,先看一下python的代码: import numpy as npa = np.random.normal(size=(3, 4)).astype('float32')print(a)print(a.sum(axis=1)) 打印结果为: 这里就是沿着第二个维度进

tvm学习笔记(六):数据类型及形状
据说tvm会支持训练,然后沐神他们为了推广tvm,专门对tvm重写了文档d2l-tvm,具体详见资料[1],下面就是对着沐神他们写的文档做的学习记录: 1.tvm的数据类型 我们在声明placeholder的时候,可以显式的指定数据的类型,如:'float16', 'float64', 'int8','int16', 'int64'等 import tvmA = tvm.placehold
RK3588-TVM-GPU推理模型
1.前言 之前的博客已经在RK3588上安装了tvm的mali-gpu的版本,我们整理一下思路,本文将从模型的转换和调用两个方面进行讲解,tvm使用的是0.10版本,模型和代码也都是tvm官方的案例。 2.onnx模型转换 将ONNX格式的ResNet50-v2模型转换为TVM Runtime支持的形式,并将其编译为一个共享库文件。以下是对代码的解释: 1.

活动回顾 (上) | 2023 Meet TVM 系列活动完美收官
作者:xixi 编辑:三羊、李宝珠 2023 Meet TVM · 年终聚会于 12 月 16 日在上海圆满落幕,本次 meetup 不仅邀请到了 4 位 AI 编译器专家为大家带来了精彩的分享,还新增了圆桌讨论环节,以更多元的视角和各位共同讨论大模型时代机器学习系统的创新和挑战。 12 月 16 日 2023 Meet TVM · 年终聚会在上海创业者公共实训基地成功举办!尽管上海气温
AI编译器及TVM概述
AI编译器 AI编译器有许多不同的类型和品牌,以下是一些常见的AI编译器: TensorFlow:谷歌开发的深度学习框架,它包含了一个用于优化和编译TensorFlow模型的编译器。 PyTorch:一个基于Python的开源深度学习框架,也提供了一个编译器用于执行和优化PyTorch模型。 ONNX:开放神经网络交换的标准,它定义了一个中间表示格式,允许不同的深度学习框架之间交换和执行
RK3588安装TVM-CPU版本
1.背景 TVM是一个开源的机器学习编译器栈,用于优化和编译深度学习模型,以在各种硬件平台上实现高效性能。以下是关于TVM的详细介绍: TVM的目标是将深度学习模型的优化和编译过程自动化,以便开发人员可以轻松地将其模型部署到各种硬件平台上,包括CPU、GPU、FPGA等。TVM的核心功能包括自动优化、代码生成和硬件抽象。它可以根据硬件平台的特点自动调整模型的计算图,生成高效的代

Ubuntu20.04上编译安装TVM
本文主要讲述如何在ubuntu20.04平台上编译TVM代码并在python中import tvm成功。 源代码下载: git clone --recursive https://github.com/apache/tvm tvm 平台环境升级: 1) sudo apt-get update 2) sudo apt-get install -y python3 python3-d
初探TVM--使用Tensor Engine来编写算子
使用TE编写CPU算子 什么是TE第一个例子:用TE写一个CPU的向量加法描述一个向量计算给计算创造一个默认的优化调度编译并且评估默认的调度使用并行化优化调度(paralleism)使用向量化的优化调度对比几种优化调度 什么是TE 就像在题目中写的那样,TE就是Tensor Engine的简称,其实就是用这些接口来定义一个计算算子是干什么的。可以转到tvm的一个大体介绍里面再看

深度学习编译中间件之NNVM(五)TVM论文阅读
参考文档 https://mp.weixin.qq.com/s/irvBbPKENiZX9G_6wh5c-Q 陈天奇等人提出TVM:深度学习自动优化代码生成器https://arxiv.org/abs/1802.04799v1 TVM: End-to-End Optimization Stack for Deep Learning 摘要:现今,像Tensorflow,MXNet,Caffe和
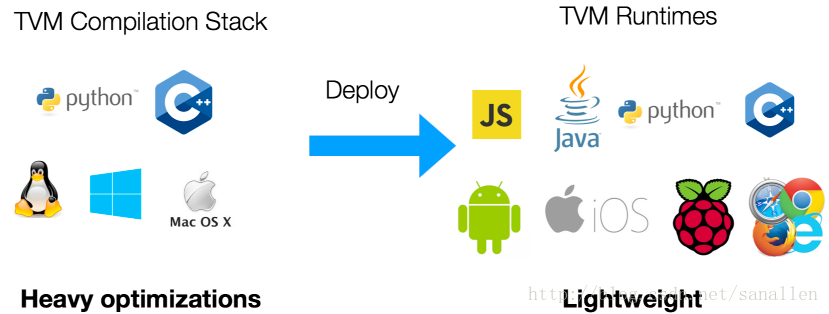
深度学习编译中间件之NNVM(四)TVM设计理念与开发者指南
参考文档 http://docs.tvmlang.org/dev/index.html TVM Design and Developer Guide 本文档为官方指导手册的中文翻译版本,主要涉及到TVM的设计理念和开发者指南,适用于计划深入掌握TVM深度定制开发技术的开发者。 TVM运行时系统 TVM支持多种编程语言下的编译器堆栈开发和部署,针对本文档我们主要会介绍TVM运行时的关键组件。