trt专题

修改ModelLink在RTX3090完成预训练、微调、推理、评估以及TRT-LLM转换、推理、性能测试
修改ModelLink在RTX3090完成预训练、微调、推理、评估以及TRT-LLM转换、推理、性能测试 1 参考文档2 测试环境3 创建容器4 安装AscendSpeed、ModelLink5 下载LLAMA2-7B预训练权重和词表6 huggingface模型的推理及性能测试7.1 修改torch,deepspeed规避缺失npu环境的问题7.2 修改点ModelLink规避缺失npu环
Yolov8将.pt文件转换为tensorRt的.trt文件(模型部署)
我的环境 确保自己已经有cuda和cudnn的环境基础上进行。 cuda:11.7cudnn:适合cuda的版本Anaconda3 [python 3.10]TensorRt-8.6.1 安装TensorRt环境 查看自己的cuda环境,去官网下载适合的win版本。 官网地址 下载后解压,将解压后lib目录添加到环境变量。 找到自己的cuda安装文件目录,将解压后lib文

PyTorch随笔 - 获取TensorRT(TRT)模型输入和输出
获取TensorRT(TRT)模型输入和输出,用于创建TRT的模型服务使用,具体参考脚本check_trt_script.py,如下: 脚本输入:TRT的模型路径和输入图像尺寸脚本输出:模型的输入和输出结点信息,同时验证TRT模型是否可用 #!/usr/bin/env python# -- coding: utf-8 --"""Copyright (c) 2021. All rights

ONNX转TRT问题
Could not locate zlibwapi.dll. Please make sure it is in your library path 从cuDNN website下载了 zlibwapi.dll 压缩文件。 将zlib123dllx64\dll_x64中的 zlibwapi.dll放到C:\Program Files\NVIDIA GPU Computing Toolkit\C
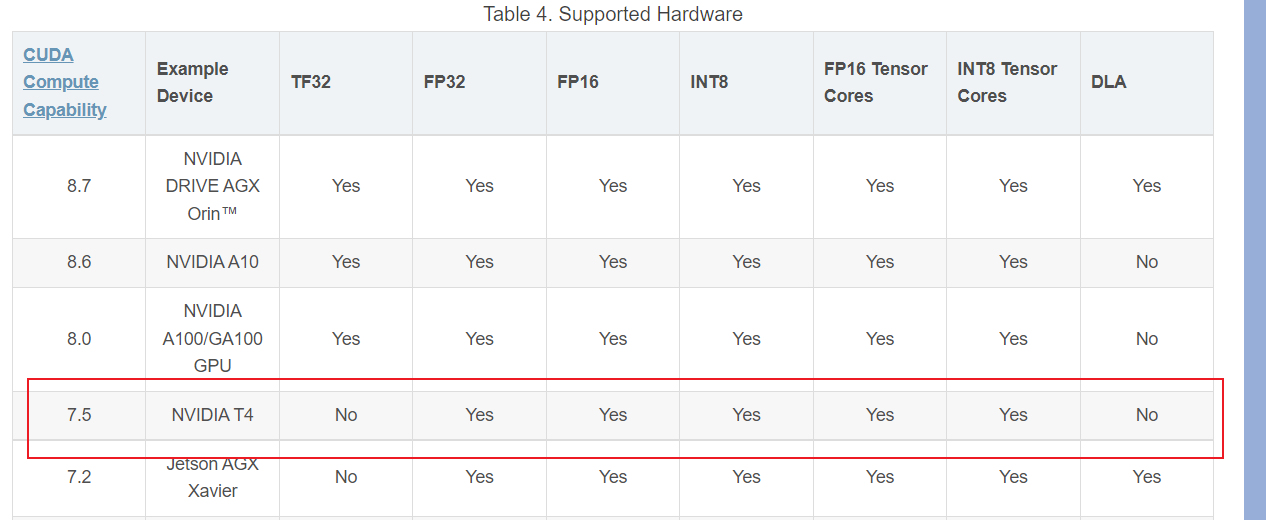
onnx 模型导出为 trt 模型
linux 环境类似,本篇针对 Windows 环境 按照这篇文章配置一下 TensorRT 的环境: TensorRT windows10 安装过程记录 方法一:代码转化 可以直接用TensorRT Python API 中的 onnx Parser 来读取然后序列化模型并保存 但是,在这个过程中,实际上已经进行了构建,或者直接说,就是 build 过程,所以要进行精度转换到TF32、F
Jetson学习笔记(四):pth(torch模型文件)转trt(tensorrt引擎文件)实操
文章目录 install torch2trt具体代码1运行结果 具体代码2运行结果 具体代码3运行结果 install torch2trt git clone https://github.com/NVIDIA-AI-IOT/torch2trtcd torch2trtsudo python setup.py install --plugins 具体代码1 from
onnx模型转trt模型报错TensorRT was linked against cuDNN 8.4.1 but loaded cuDNN 8.2.1
具体报错:Results saved to D:\todesk\yolov8model Predict: yolo predict task=detect model=yolov8s.onnx imgsz=640 Validate: yolo val task=detect model=yolov8s.onnx imgsz=640 data=coco.yaml Vis
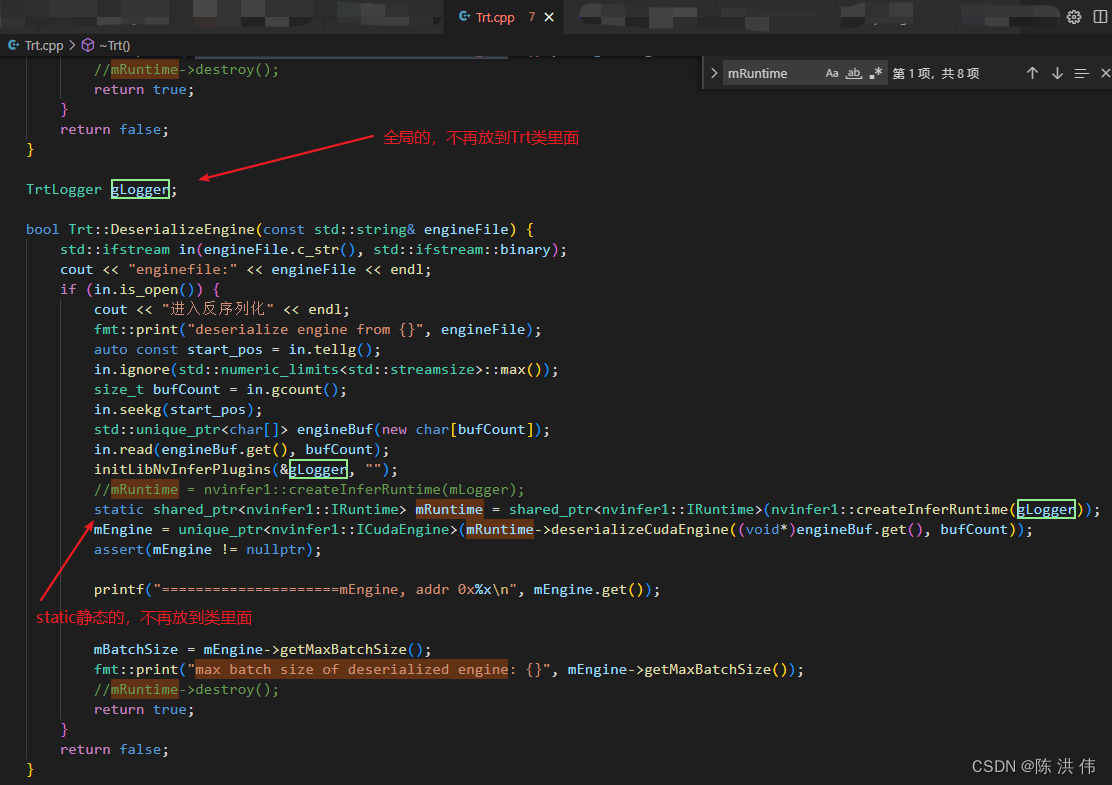
tensorRT推理yolov5.trt模型崩溃
在用 在jetson xavier上利用TensorRT C++部署yolov5_基于tiny-tensorrt_陈 洪 伟的博客-CSDN博客 代码推理yolov5的trt模型时,当我多线程推理模型时候(两个线程同时做初始化、推理、反初始化),程序老是在反初始化的时候崩溃, if(nullptr == mystream){cudaStreamDestroy(mystream);}i
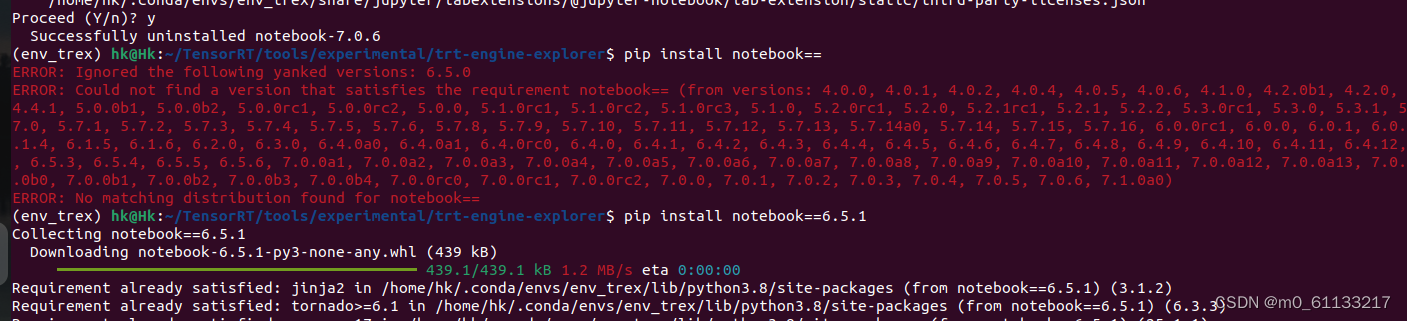
使用trt-engine-explorer踩坑记录,
1、问题 trt-engine-explorer时英伟达提供分析TensorRT优化后推理引擎的工具包:官方链接TensorRT 按照官网安装步骤,也可使用conda创建虚拟环境, 步骤3出现的问题:jupyter command jupyter nbextension not found 工具包安装连接可参考:安装步骤 解决办法:降低了,版本即可:然后可以正常运行步骤3。

Linux安装CUDA+CUDNN+TRT+DS教程
Linux安装CUDA+CUDNN+TRT+DS教程 一、系统部署及环境部署(CUDA,CUDNN,TRT,Deepstream) 在进行系统部署及环境部署时,要注意各组件的版本号是否对应,如下图: 1.1 安装CUDA (1)查看显卡驱动是否安装 nvidia-smi 可以看到显示出CUDA 的对应信息,表示驱动已经安装了,如果没有返回,可以安装时进行勾选。这一步一定要检查,

yolov4_trt
环境: tensorRT5.1.6-1xaviercuda10python2.7 tensorRT简介及原理: tensorRT是由Nvidia推出的一款GPU推理引擎(GIE: GPU Inference Engine)。由于训练好的神经网络权重已经确定,后续使用中无需后向传播以及高精度计算,因此在模型的部署过程中可以通过使用低精度如FP16(16位的float型)来对前向传播过程进行加速
【python】yolo目标检测模型转为onnx,及trt/engine模型的tensorrt轻量级模型部署
代码参考: Tianxiaomo/pytorch-YOLOv4: PyTorch ,ONNX and TensorRT implementation of YOLOv4 (github.com)https://github.com/Tianxiaomo/pytorch-YOLOv4这个大佬对于各种模型转化写的很全,然后我根据自己的需求修改了部分源码,稍微简化了一些效率,同时结合视频流,做了个基于
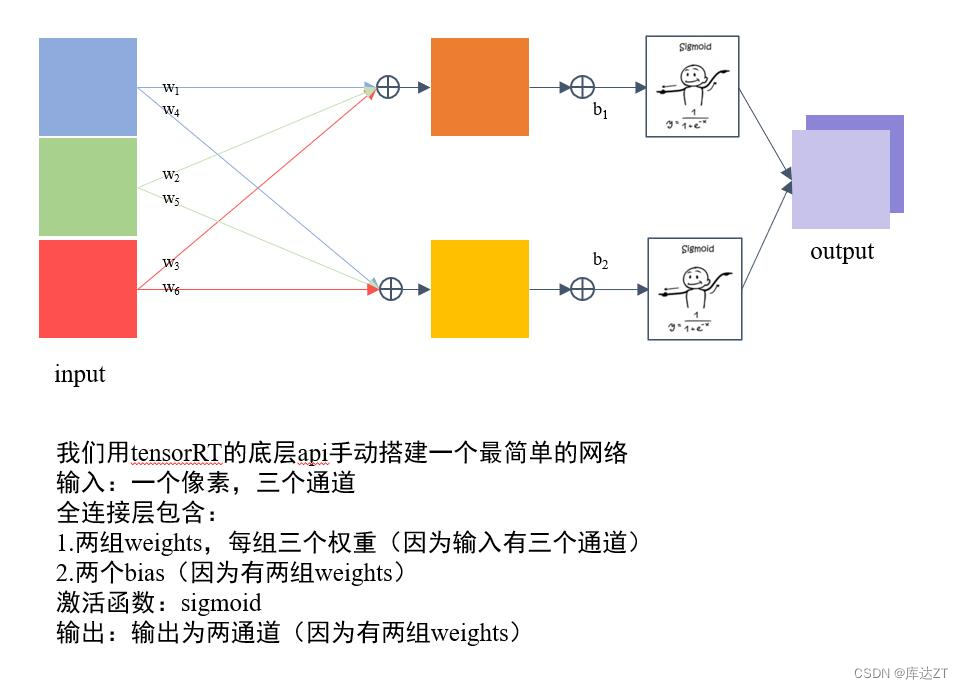
TRT3-trt-basic - 1 basic
前言: - tensorrt的工作流程如下图: - 首先定义网络- 优化builder参数- 通过builder生成engine,用于模型保存、推理等- engine可以通过序列化和逆序列化转化模型数据类型(转化为二进制byte文件,加快传输速率),再进一步推动模型由输入张量到输出张量的推理。
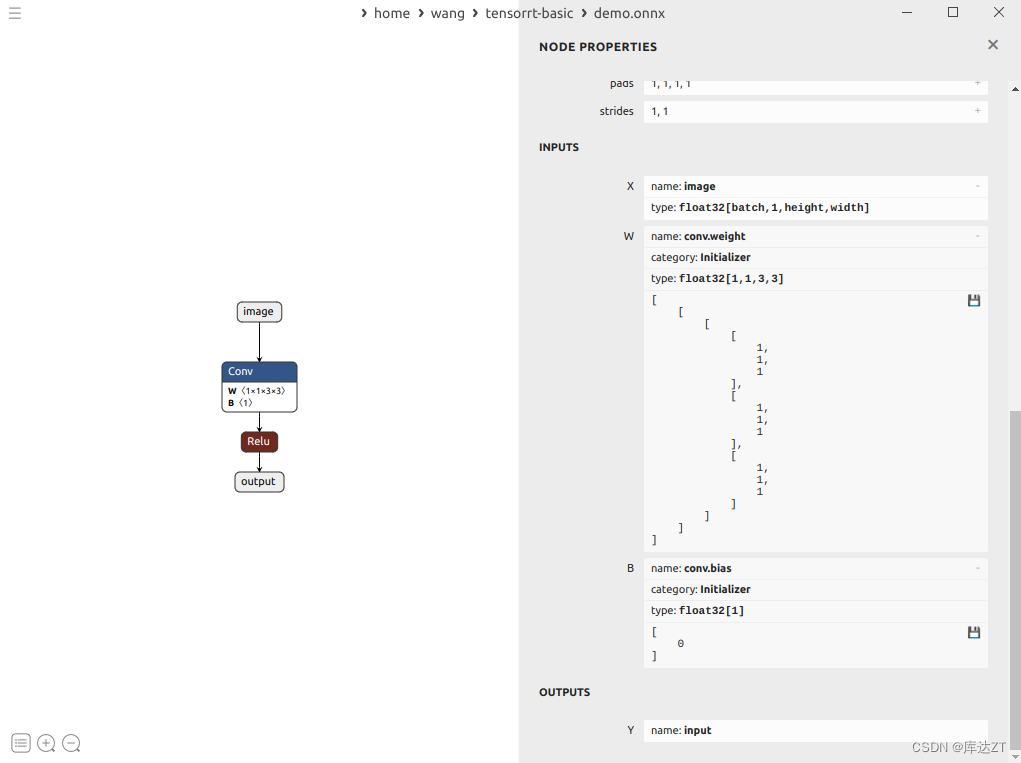
TRT3-trt-basic - 4 ONNX结构
1、前言: 1、ONNX的本质,是一种Protobuf格式文件 2、Protobuf则通过onnx-ml.proto编译得到onnx-ml.pb.h和onnx-ml.pb.cc或onnx_ml_pb2.py 3、然后用onnx-ml.pb.cc和代码来操作onnx模型文件,实现增删改 4、onnx-ml.proto则是描述onnx文件如何组成的,具有什么结构,他是操作onnx经常参照的东西

YOLOv7数据标注、环境配置、训练、预测、trt加速
YOLOv7数据标注、环境配置、训练、预测、trt加速 本文的训练教程使用的是2023-07-20从github仓库拉取的代码以及模型,tag是0.1版本,其他版本的训练可能会有所改动 本文主要是教工作室同学使用yolov7,欢迎大佬指出错误 1、下载代码和模型 1.1 下载代码 1.1.1使用git拉取 直接在终端执行,拉取的项目文件会存放在当前的目录里面,拉取之前注意需要先进