本文主要是介绍YOLOv7数据标注、环境配置、训练、预测、trt加速,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
YOLOv7数据标注、环境配置、训练、预测、trt加速
本文的训练教程使用的是2023-07-20从github仓库拉取的代码以及模型,tag是0.1版本,其他版本的训练可能会有所改动
本文主要是教工作室同学使用yolov7,欢迎大佬指出错误
1、下载代码和模型
1.1 下载代码
1.1.1使用git拉取
直接在终端执行,拉取的项目文件会存放在当前的目录里面,拉取之前注意需要先进入自己存放项目的目录
使用这种方法需要提前安装好git
git clone https://github.com/WongKinYiu/yolov7.git
1.1.2下载zip压缩包
打开仓库下载,仓库链接WongKinYiu/yolov7: Implementation of paper - YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors (github.com)

下载之后解压到自己的目录即可
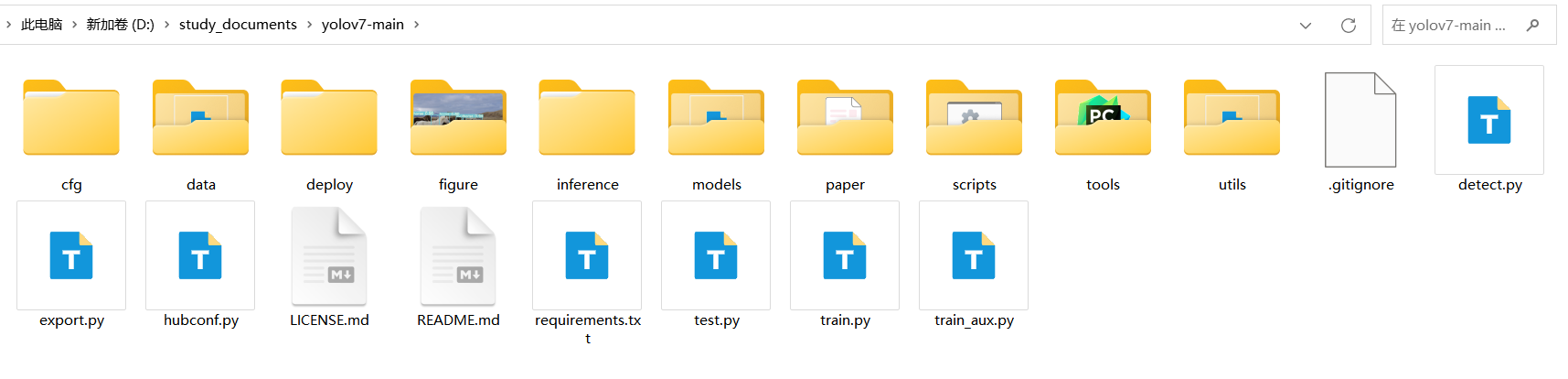
使用zip的方式下载和使用git clone的方式下载得到的文件夹里面的内容是一样的,如下
1.2 下载预训练模型
在下载下来的文件夹里面创建一个weights的文件夹,用于存放下载下来的模型文件,也可以直接存放在项目根目录下面,看个人喜好
在github仓库里面向下拉找到Performance,如下

两个位置下载的模型都是一样的,一般使用的是第一个模型,直接下载到刚才创建的文件夹即可

2、环境准备
2.1 、python环境准备
已经有python环境的可以直接跳过
2.1.1、使用anaconda安装python环境
下载地址 Free Download | Anaconda
下载之后直接安装即可,选择仅为个人用户安装,然后后面需要勾选的全部勾选上,如果没勾可能需要单独配置环境变量
单独配置环境变量
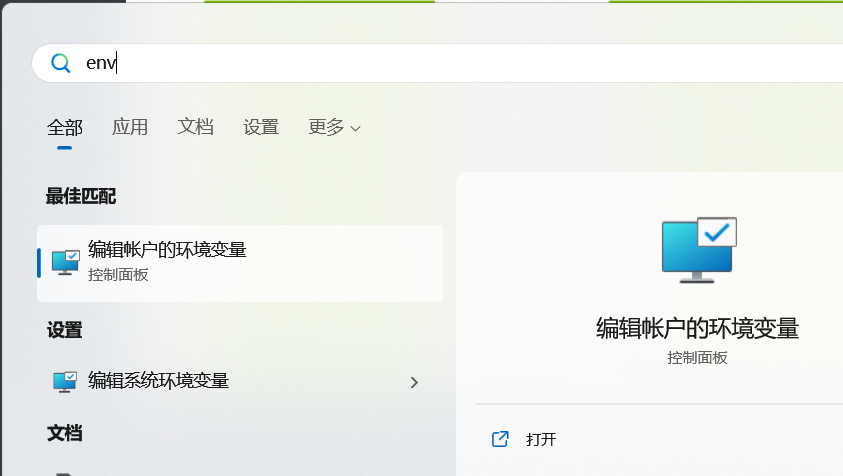
使用windows搜索env,进入编辑账户环境变量,如下
添加如下环境变量
在系统环境变量path里面添加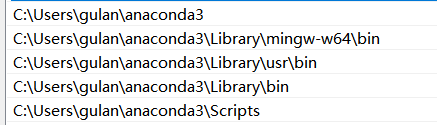
添加到用户path也可以
安装完成之后打开命令提示符
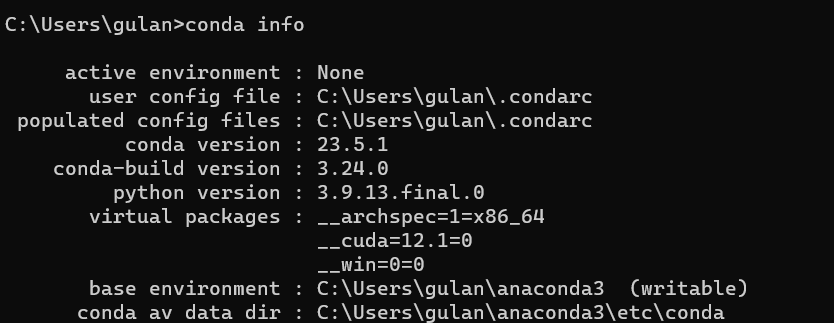
使用conda info查看conda的环境变量是否配置完成,如下
2.1.2、使用miniconda配置python环境
下载地址 Miniconda — conda documentation
这个的安装和anaconda一样,对照使用
2.2、使用GPU训练
目前只有Nvidia显卡支持使用GPU训练,需要安装cuda和cudnn,使用AMD和intel的显卡的电脑目前只能用CPU训练(可能有大佬能使用这两家的显卡进行训练,我只是小白,大佬勿喷)
2.2.1、 安装cuda和cudnn
- cuda
下载地址:
CUDA Toolkit 12.2 Downloads | NVIDIA Developer
下载地址进去默认是最新版,可以拉大最后选择自己需要的版本
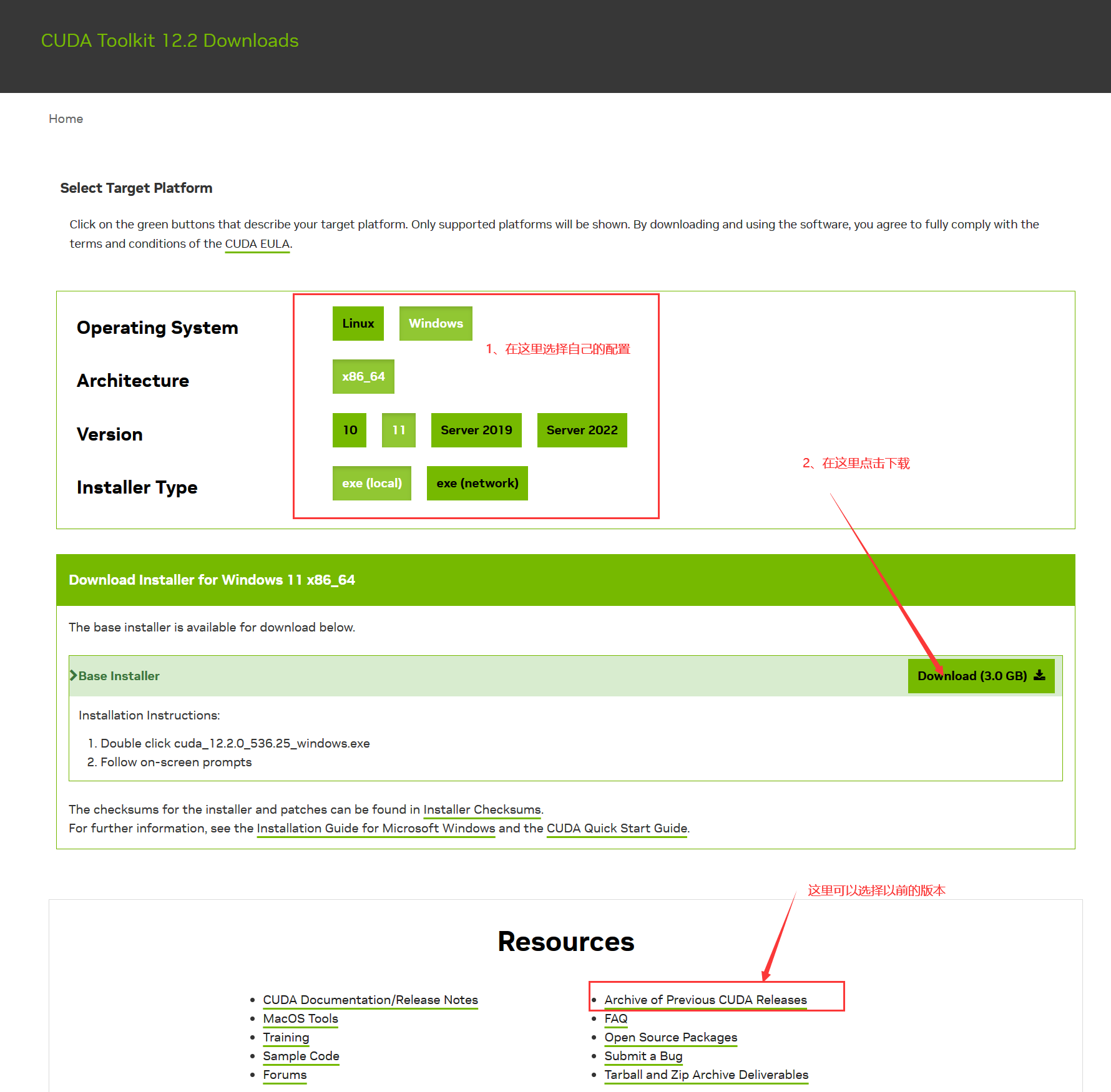
版本选择界面是下面这样的

下载下来的cuda安装包是一个.exe文件,直接双击运行,安装过程中可以选择一下安装的位置,其他有需要勾选的地方全部勾选上
默认安装位置是(我使用的是11.3的版本)
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.3
配置环境变量
使用windows搜索env,进入编辑账户环境变量,如下
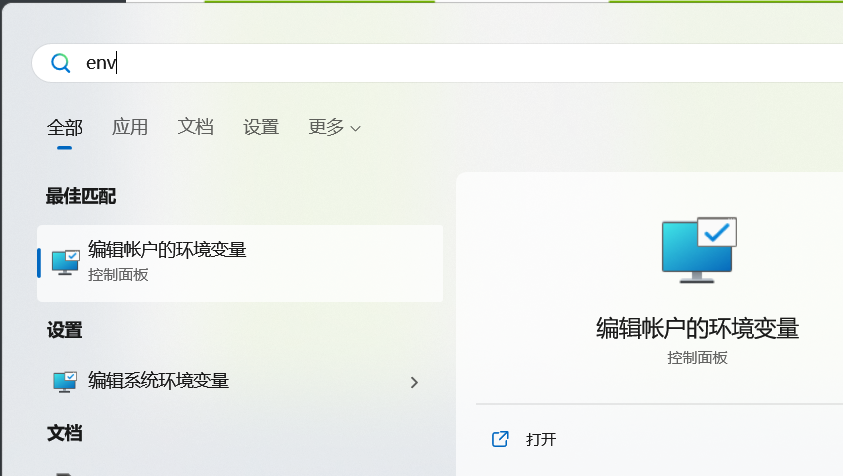
添加如下环境变量
在系统环境变量path里面添加

注意将这两个路径换成自己的安装路径
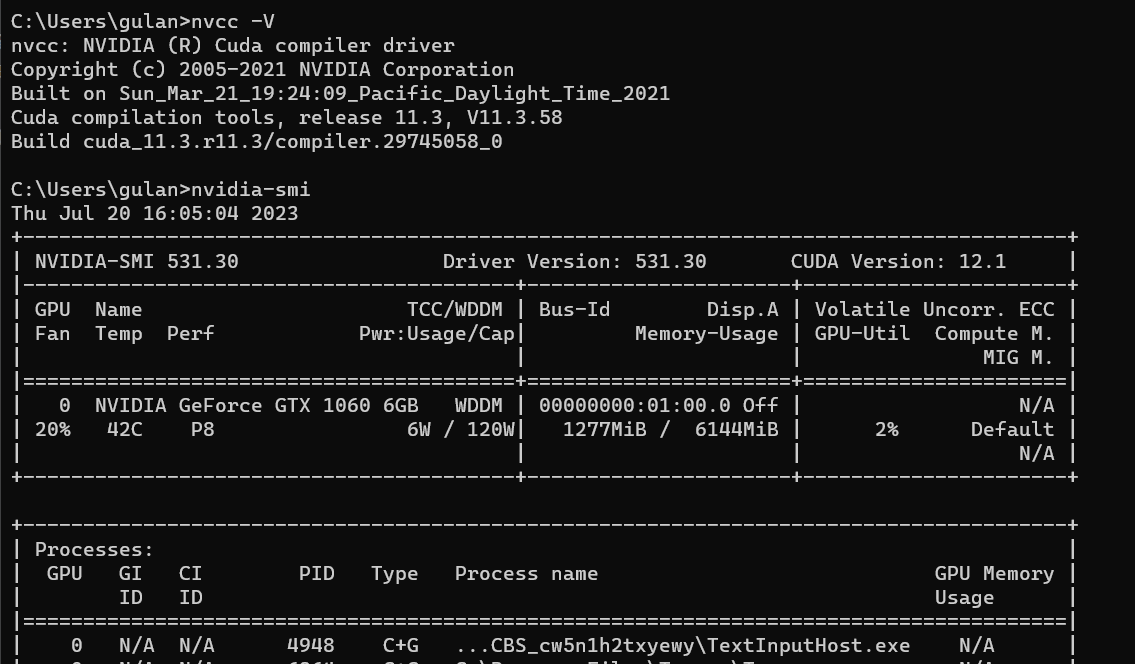
然后打开cmd命令框,使用nvcc -V和nvidia-smi分别查看,得到类似下图的即可
-
cudnn
下载地址
cuDNN Download | NVIDIA Developer

cudnn下载下来之后解压到cuda的安装路径即可
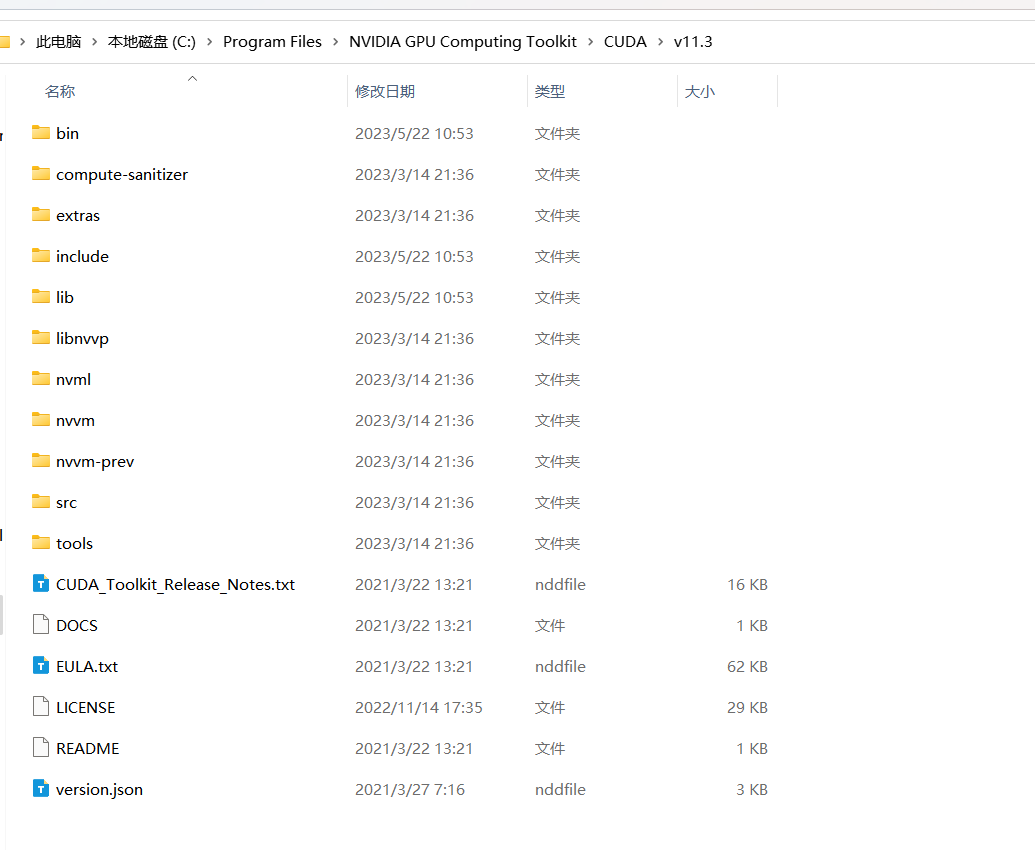
解压到这个目录下面即可,如果提示有重复文件选择覆盖
2.2.2使用conda配置yolo环境
创建一个conda环境
直接在终端运行conda create -n yolo python=3.10 在创建环境的同时安装python3.10,如下
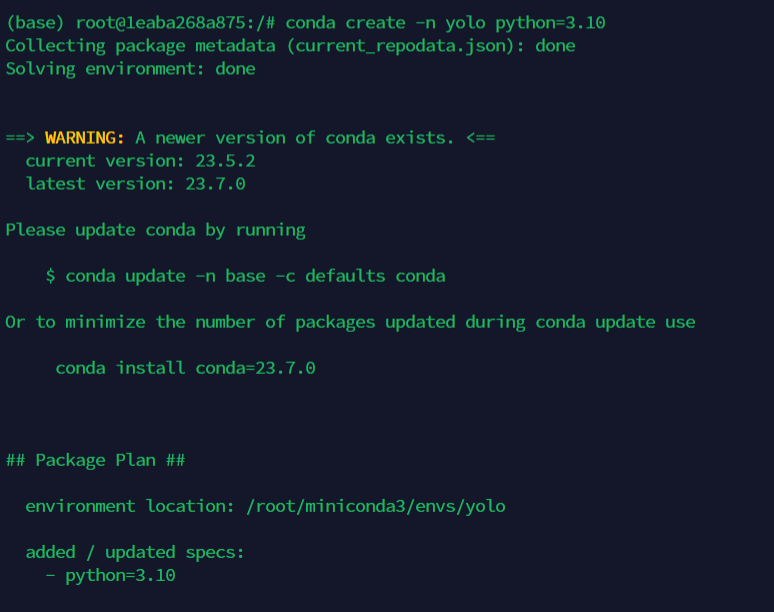
创建完成会有如下输出

使用conda activate yolo 进入创建好的环境

切换到yolov7文件存放的位置

注意里面的文件必须有 requirements.txt
然后配置yolo需要的python环境包,运行pip install -i https://pypi.mirrors.ustc.edu.cn/simple/ -r requirements.txt等待所有包安装完成即可
检测torch能不能调用cuda
在终端进入python环境然后运行
import torch
torch.cuda.is_available()

返回true即可,如果返回的是其他值则需要重新安装torch
需要先卸载之后再安装
卸载指令:pip uninstall torch
进入pytorch官网,链接:PyTorch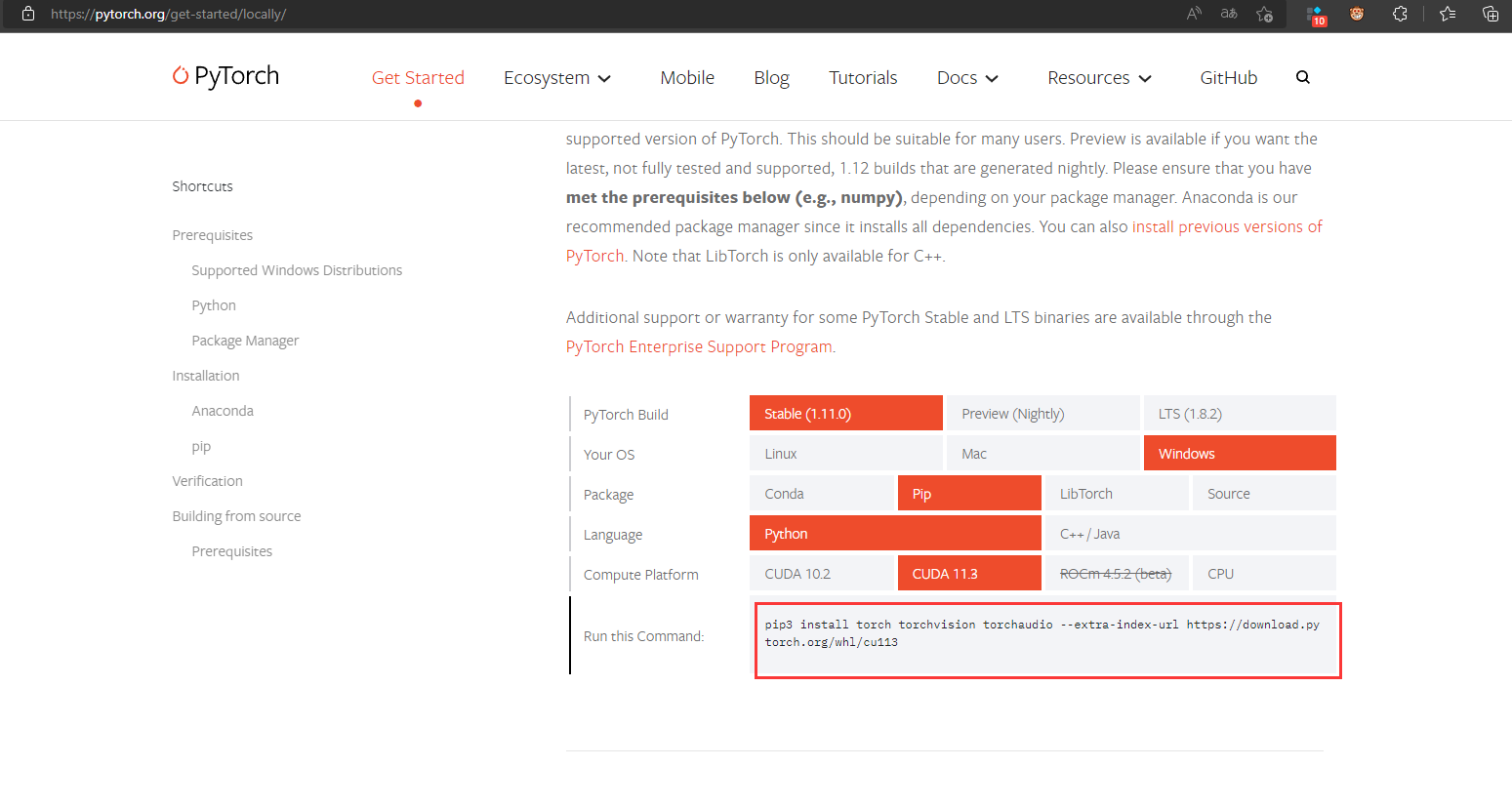
按照自己的环境配置选择,并复制下方指令,在其后面加入清华源链接安装
安装完成之后再次测试,结果如下即可

到此,环境配置完成
2.3、使用cpu训练
使用cpu训练不需要配置cuda和cudnn,只需配置python环境即可
2.3.1、使用conda配置yolo环境(cpu)
创建一个conda环境
直接在终端运行conda create -n yolo python=3.10 在创建环境的同时安装python3.10,如下
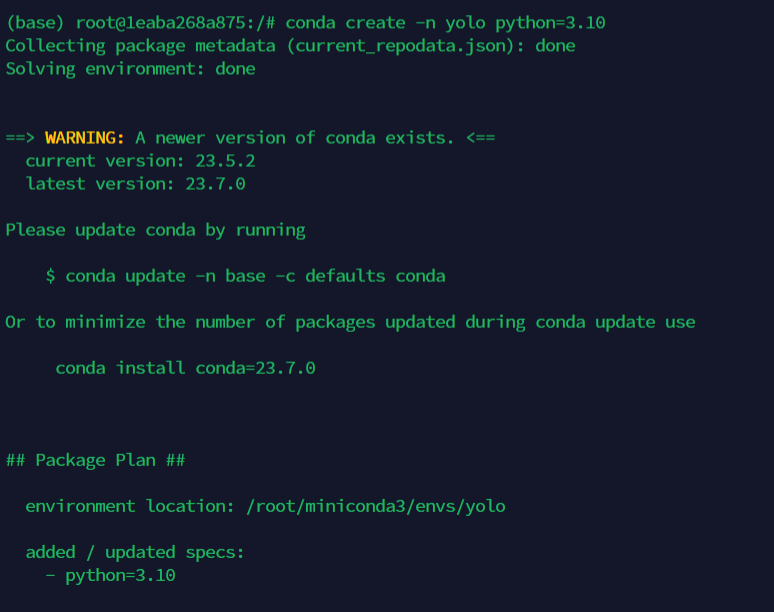
创建完成会有如下输出

使用conda activate yolo 进入创建好的环境

切换到yolov7文件存放的位置
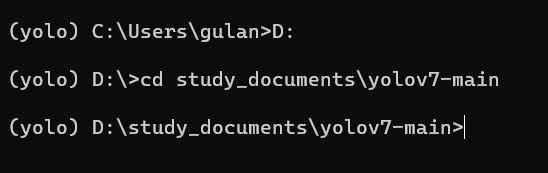
注意里面的文件必须有 requirements.txt
然后配置yolo需要的python环境包,运行pip install -i https://pypi.mirrors.ustc.edu.cn/simple/ -r requirements.txt等待所有包安装完成即可
3、训练
3.1、数据集标注
使用labelimg,这个组件可以使用pip安装,安装指令
pip install -i https://pypi.mirrors.ustc.edu.cn/simple/ labelimg
安装之后直接使用labelimg运行即可

标记完成之后会生成对应文件的.txt文件,这个保存的是标签数据
还有一个classes.txt,这里保存的是每个标签的顺序,这个顺序在多人标注的时候不能乱,在训练的时候需要用到这个顺序
3.2、调整数据集及配置训练参数
标注完成之后将图片和标注数据分别存放在两个文件夹里面,如下

将这个数据集存放于yolov7文件夹里面的data里面,类似于

3.2.1、划分数据集
将数据集划分为train、test、val三部分,分别用于训练、测试和验证三部分,在数据集较小的时候可以不用测试部分
使用下面代码进行划分,这个代码只划分了训练和验证,没有测试,注意修改35和36行代码,还有21、26行(生成txt文件的路径)
# 划分数据集
import os
import randomdef split_files(folder_path, ratio):# 获取文件夹中的文件列表file_list = os.listdir(folder_path)# 计算划分的文件数量total_files = len(file_list)num_files_part1 = int(total_files * ratio)num_files_part2 = total_files - num_files_part1# 随机划分文件random.shuffle(file_list)part1_files = file_list[:num_files_part1]part2_files = file_list[num_files_part1:]# 将划分结果写入 txt 文件with open("./data/coffee/train_list.txt", "w") as f:for filename in part1_files:abs_path = os.path.join(folder_path, filename)f.write(abs_path + "\n")with open("./data/coffee/val_list.txt", "w") as f:for filename in part2_files:abs_path = os.path.join(folder_path, filename)f.write(abs_path + "\n")print("Splitting files completed.")if __name__ == "__main__":folder_path = r"D:\study_documents\test_file\yolov7\data\coffee\images" # 替换为实际的文件夹路径ratio = 0.9 # 指定训练部分的文件数量比例split_files(folder_path, ratio)
这个代码划分之后会生成两个txt文件,里面的内容如下

3.2.2、修改参数并训练
将data里面的coco.yaml文件修改为如下格式
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: D:\study_documents\test_file\yolov7\data\coffee\train_list.txt
val: D:\study_documents\test_file\yolov7\data\coffee\val_list.txt
# number of classes
nc: 1# class names
names: ['impurity']其中nc是标注数据集时候的种类
names是标注时候的类别名字,这个需要和上面提到的classes.txt顺序一样
第二行和第三行按照自己的路径修改即可
修改train.py文件
找到配置参数,我拉取的版本在527行开始,我将需要注意的参数标注出来,可以参考一下

这些参数修改之后直接运行即可,显存小的或者使用cpu训练的注意将**–batch-size**改小一点
3.2.3、对参数的部分理解(个人理解,仅供参考)
-
--weights(类型:字符串,默认值:‘yolov7.pt’):- 作用:指定训练或测试时的初始模型权重路径。
- 修改:将默认值更改为您所需的初始模型权重路径。
-
--cfg(类型:字符串,默认值:‘cfg/training/yolov7.yaml’):- 作用:指定模型配置文件(model.yaml)的路径,其中定义了YOLOv7模型的架构。
- 修改:如果您有自定义的模型配置文件,请将默认值更改为其路径。
-
--data(类型:字符串,默认值:‘data/coco.yaml’):- 作用:指定数据配置文件(data.yaml)的路径,其中包含关于数据集的信息,如类别数目、训练和测试图像目录等。
- 修改:如果您有自定义的数据配置文件,请将默认值更改为其路径。
-
--hyp(类型:字符串,默认值:‘data/hyp.scratch.p5.yaml’):- 作用:指定超参数配置文件(hyp.scratch.p5.yaml)的路径,其中包含了训练的各种超参数。
- 修改:如果您有自定义的超参数配置文件,请将默认值更改为其路径。
-
--epochs(类型:整数,默认值:300):- 作用:指定训练的总轮数(epochs)。
- 修改:将默认值更改为所需的训练轮数。
-
--batch-size(类型:整数,默认值:8):- 作用:指定每个GPU上的批次大小。
- 修改:根据可用的GPU内存,将默认值更改为所需的批次大小。
-
--img-size(nargs=‘+’, 类型:整数列表,默认值:[640, 640]):- 作用:指定训练和测试时的图像大小。
- 修改:将默认值更改为两个整数的列表,表示所需的图像大小(宽度,高度)。
-
--rect(action=‘store_true’):- 作用:如果提供该参数,则启用矩形训练。矩形训练不会将图像调整为正方形,而是保持原始的长宽比。
-
--resume(nargs=‘?’, const=True, 默认值:False):- 作用:如果提供该参数,则允许从最近的检查点继续训练。
- 修改:要恢复训练,请将检查点文件的路径作为参数传递。例如:
--resume checkpoints/last.pt。
-
--nosave(action=‘store_true’):- 作用:如果提供该参数,则只保存最终的检查点,而不保存训练过程中的中间检查点。
-
--notest(action=‘store_true’):- 作用:如果提供该参数,则只在训练结束后进行一次测试,而不会在每个训练轮次后进行测试。
-
--noautoanchor(action=‘store_true’):- 作用:如果提供该参数,则禁用自动锚框检测,不会根据数据集自动调整锚框的尺寸。
-
--evolve(action=‘store_true’):- 作用:如果提供该参数,则启用超参数进化,它会在训练过程中自动搜索更好的超参数。
-
--bucket(类型:字符串,默认值:‘’):- 作用:如果使用Google Cloud Storage,指定用于存储日志和检查点的gsutil存储桶。
-
--cache-images(action=‘store_true’):- 作用:如果提供该参数,则在内存中缓存图像以加快训练速度。
-
--image-weights(action=‘store_true’):- 作用:如果提供该参数,则使用加权图像选择进行训练。
-
--device(默认值=‘0’):- 作用:指定用于训练的CUDA设备(例如,'0’表示使用GPU 0,'0,1’表示使用多个GPU)。
- 修改:将默认值更改为所需的CUDA设备或如果要使用CPU进行训练,则设置为’cpu’。
-
--multi-scale(action=‘store_true’):- 作用:如果提供该参数,则在训练过程中随机变化图像大小,范围为+/- 50%。
-
--single-cls(action=‘store_true’):- 作用:如果提供该参数,则将多类数据视为单类数据进行训练。
- 修改:如果有多类数据集,请保留此参数或从代码中删除它。只有在将多类数据视为单类数据时使用此选项。
-
--adam(action=‘store_true’):- 作用:如果提供该参数,则使用Adam优化器进行训练。
- 修改:如果想要使用其他优化器,请从代码中删除此参数,并根据需要设置优化器。
-
--sync-bn(action=‘store_true’):- 作用:如果提供该参数,则使用SyncBatchNorm,这仅在DDP(Distributed Data Parallel)模式下可用。
-
--local_rank(类型:整数,默认值:-1):- 作用:DDP参数,除非使用分布式数据并行训练,否则不要修改。
-
--workers(类型:整数,默认值:1):- 作用:指定用于加载数据的最大数据加载器(dataloader)工作进程数。
-
--project(默认值=‘runs/train’):- 作用:指定使用Weights & Biases(W&B)库保存训练日志和检查点的路径。
3.3、预测与测试
训练得到的模型保存在runs/train/exp/weights里面,使用best.pt模型,其余模型可以删除,
修改detect.py,修改以下参数

只需修改对应的参数即可
3.3.1、对测试参数的部分理解
-
--weights:该参数用于指定模型权重(model.pt)文件的路径。可以接受多个路径,用于使用集成模型。修改成自己的模型路径。 -
--source:该参数用于指定推理的输入数据来源。可以是文件/文件夹路径,也可以是0,表示使用摄像头作为输入源。 -
--img-size:该参数设置推理时输入图像的尺寸,以像素为单位。默认值为640。 -
--conf-thres:该参数设置对象置信度阈值,低于该阈值的任何检测到的对象将被丢弃。默认值为0.25。 -
--iou-thres:该参数设置非最大抑制(NMS)的交并比(IOU)阈值。用于抑制重复的检测结果。默认值为0.45。 -
--device:该参数用于指定推理所使用的设备,可以选择’cuda’加上GPU设备编号(例如,‘0’或’0,1,2,3’)或’cpu’。 -
--view-img:这是一个标志参数。如果出现,则会显示推理结果,允许可视化检测到的对象,添加一个default=Ture/Faulse来指定这个参数是否生效。 -
--save-txt:这是一个标志参数。如果出现,则会将推理结果保存为.txt文件,添加一个default=Ture/Faulse来指定这个参数是否生效。 -
--save-conf:这是一个标志参数。如果出现,则会将检测到的对象的置信度与.txt结果一起保存,添加一个default=Ture/Faulse来指定这个参数是否生效。 -
--nosave:这是一个标志参数。如果出现,则会禁止保存带有绘制边界框的图像或视频,用于检测到的对象,添加一个default=Ture/Faulse来指定这个参数是否生效。 -
--classes:该参数允许您基于特定类别过滤检测到的对象。您可以指定类别ID,只在检测结果中包括这些类别。 -
--agnostic-nms:这是一个标志参数。如果出现,则会启用无类别非最大抑制,意味着在NMS过程中不考虑类别信息。 -
--augment:这是一个标志参数。如果出现,则会启用增强推理,即在推理过程中应用数据增强,以提高检测准确性。 -
--update:这是一个标志参数。如果出现,则会更新--weights参数指定的所有模型。 -
--project:该参数用于指定保存结果的项目目录。默认值为’runs/detect’。 -
--name:该参数用于指定实验的名称。默认值为’exp’。 -
--exist-ok:这是一个标志参数。如果出现,则允许在不递增的情况下使用具有相同名称的现有项目。 -
--no-trace:这是一个标志参数。如果出现,则会阻止在推理过程中对模型进行追踪。追踪是一种用于优化模型以实现更快推理的技术。
4、TensorRT部署
4.1、TensorRT安装
下载路径
NVIDIA TensorRT 8.x Download | NVIDIA Developer
注意版本

4.1.1、linux配置
下载之后先解压
tar -zxvf TensorRT-8.6.1.6.Linux.x86_64-gnu.cuda-11.8.tar.gz
配置环境变量
# 修改单个用户的环境变量文件
vim ~/.bashrc
# 添加下面两条变量,注意修改成自己的路径
export LD_LIBRARY_PATH=/home/bigdata/mmd/file/TensorRT-8.6.1.6/lib:$LD_LIBRARY_PATH
export LIBRARY_PATH=/home/bigdata/mmd/file/TensorRT-8.6.1.6/lib::$LIBRARY_PATH# 重新加载环境变量
source ~/.bashrc
然后安装对应的python包

需要安装的python包分别在python、uuf、onnx_graphsurgeon里面,python里面需要安装的有三个,选择对应的python版本安装就行
安装指令
pip install *.whl
4.1.2、windows配置
与linux一样的下载之后先解压
将解压目录添加到环境变量的path里面,如下
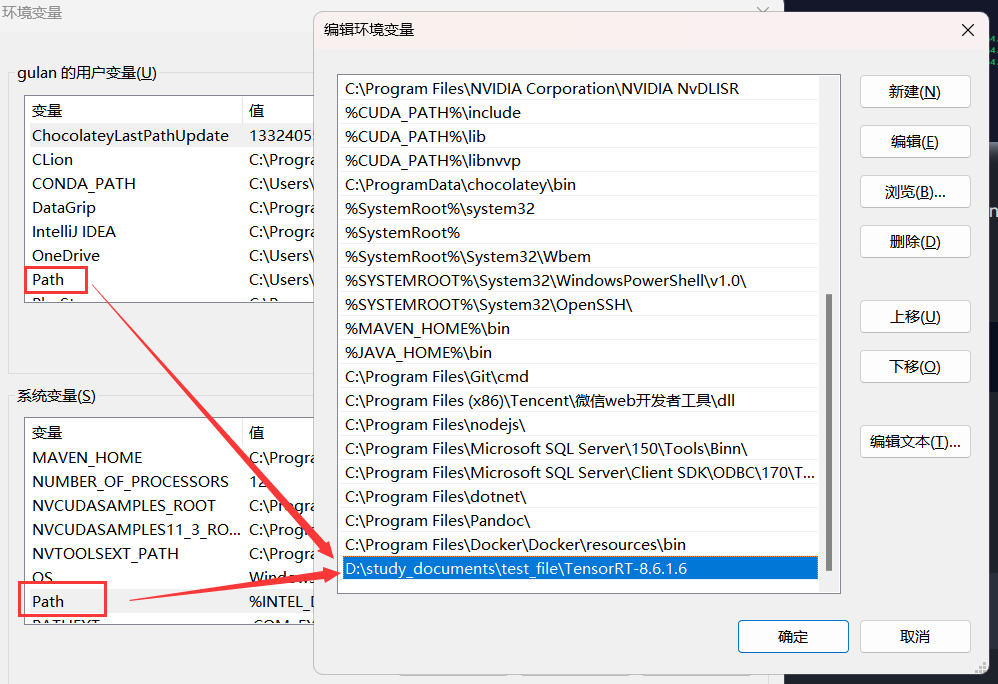
只需在系统变量和用户变量选一个添加即可。
接下来复制文件
-
将 TensorRT-8.6.1.6\include中头文件复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.3\include
-
将TensorRT-8.6.1.6\lib 中所有lib文件复制 到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.3\lib\x64
-
将TensorRT-8.6.1.6\lib 中所有dll文件复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.3\bin
注意将上面的路径改成自己的安装路径
然后安装相应的python包
这一步与Linux版本的一样,需要安装的python包分别在python、uuf、onnx_graphsurgeon里面,python里面需要安装的有三个,选择对应的python版本安装就行
安装指令
pip install *.whl
至此TensotRT已经配置完成。
4.2、模型转换
4.2.1、原生方法转engine
- .pt转**.onnx**
修改export.py,如下
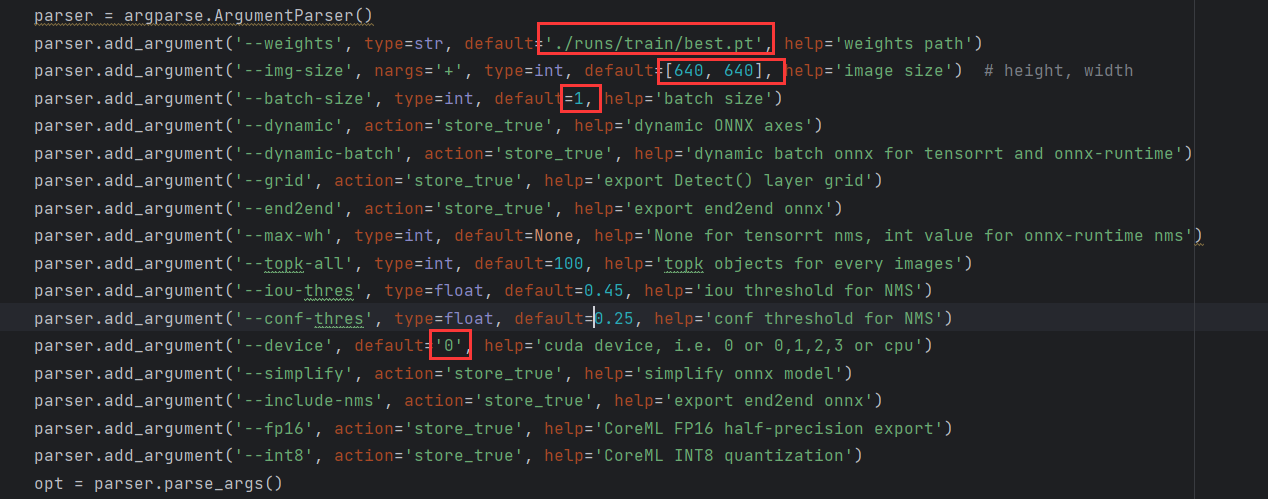
修改自己需要转的模型路径之后直接运行即可,会在对应的位置生成**.mlmodel**、.onnx、.torchscript.pt、torcscript.ptl结尾的四个类型的文件,我们只需要注意**.onnx**结尾的这个文件即可
将**.onnx结尾的文件复制到下载解压的TensorRT-8.6.1.6\bin**里面,如下
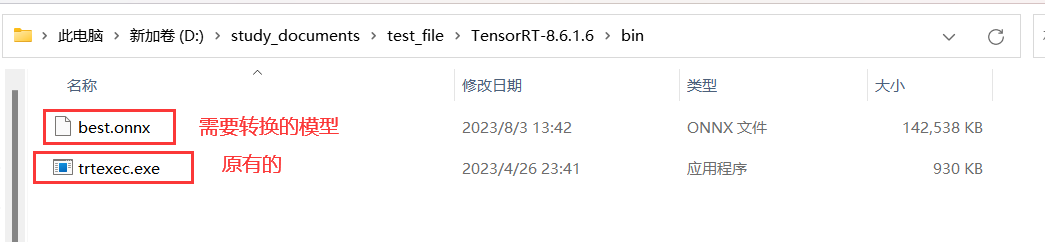
在这个目录进入终端然后进入运行yolo的环境,如下

使用TensorRT自带的trtexec.exe将**.onnx转成.engine**,转换指令如下
trtexec --onnx=./best.onnx --saveEngine=./best_fp16.engine --fp16 --workspace=200
#Linux同样可以使用这种方法转换,下面是命令
./trtexec --onnx=./best.onnx --saveEngine=./best_fp16.engine --fp16 --workspace=200
转换完成之后会在刚才的目录下面生成一个**.engine**结尾的文件,如下

这个就是我们最终需要的模型,将这个模型复制到yolov7里面和export.py同级的目录下
4.3、模型推理
在yolov7目录下创建一个infer.py的文件,文件内容如下
import cv2
import tensorrt as trt
import torch
import numpy as np
from collections import OrderedDict, namedtupleclass TRT_engine():def __init__(self, weight) -> None:self.imgsz = [640, 640]self.weight = weightself.device = torch.device('cuda:0')self.init_engine()def init_engine(self):# Infer TensorRT Engineself.Binding = namedtuple('Binding', ('name', 'dtype', 'shape', 'data', 'ptr'))self.logger = trt.Logger(trt.Logger.INFO)trt.init_libnvinfer_plugins(self.logger, namespace="")with open(self.weight, 'rb') as self.f, trt.Runtime(self.logger) as self.runtime:self.model = self.runtime.deserialize_cuda_engine(self.f.read())self.bindings = OrderedDict()self.fp16 = Falsefor index in range(self.model.num_bindings):self.name = self.model.get_binding_name(index)self.dtype = trt.nptype(self.model.get_binding_dtype(index))self.shape = tuple(self.model.get_binding_shape(index))self.data = torch.from_numpy(np.empty(self.shape, dtype=np.dtype(self.dtype))).to(self.device)self.bindings[self.name] = self.Binding(self.name, self.dtype, self.shape, self.data,int(self.data.data_ptr()))if self.model.binding_is_input(index) and self.dtype == np.float16:self.fp16 = Trueself.binding_addrs = OrderedDict((n, d.ptr) for n, d in self.bindings.items())self.context = self.model.create_execution_context()def letterbox(self, im, color=(114, 114, 114), auto=False, scaleup=True, stride=32):# Resize and pad image while meeting stride-multiple constraintsshape = im.shape[:2] # current shape [height, width]new_shape = self.imgszif isinstance(new_shape, int):new_shape = (new_shape, new_shape)# Scale ratio (new / old)self.r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])if not scaleup: # only scale down, do not scale up (for better val mAP)self.r = min(self.r, 1.0)# Compute paddingnew_unpad = int(round(shape[1] * self.r)), int(round(shape[0] * self.r))self.dw, self.dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh paddingif auto: # minimum rectangleself.dw, self.dh = np.mod(self.dw, stride), np.mod(self.dh, stride) # wh paddingself.dw /= 2 # divide padding into 2 sidesself.dh /= 2if shape[::-1] != new_unpad: # resizeim = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)top, bottom = int(round(self.dh - 0.1)), int(round(self.dh + 0.1))left, right = int(round(self.dw - 0.1)), int(round(self.dw + 0.1))self.img = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add borderreturn self.img, self.r, self.dw, self.dhdef preprocess(self, image):self.img, self.r, self.dw, self.dh = self.letterbox(image)self.img = self.img.transpose((2, 0, 1))self.img = np.expand_dims(self.img, 0)self.img = np.ascontiguousarray(self.img)self.img = torch.from_numpy(self.img).to(self.device)self.img = self.img.float()return self.imgdef predict(self, img, threshold):img = self.preprocess(img)self.binding_addrs['images'] = int(img.data_ptr())self.context.execute_v2(list(self.binding_addrs.values()))nums = self.bindings['num_dets'].data[0].tolist()boxes = self.bindings['det_boxes'].data[0].tolist()scores = self.bindings['det_scores'].data[0].tolist()classes = self.bindings['det_classes'].data[0].tolist()num = int(nums[0])new_bboxes = []for i in range(num):if (scores[i] < threshold):continuexmin = (boxes[i][0] - self.dw) / self.rymin = (boxes[i][1] - self.dh) / self.rxmax = (boxes[i][2] - self.dw) / self.rymax = (boxes[i][3] - self.dh) / self.rnew_bboxes.append([classes[i], scores[i], xmin, ymin, xmax, ymax])return new_bboxesdef visualize(img, bbox_array):for temp in bbox_array:xmin = int(temp[2])ymin = int(temp[3])xmax = int(temp[4])ymax = int(temp[5])clas = int(temp[0])score = temp[1]cv2.rectangle(img, (xmin, ymin), (xmax, ymax), (105, 237, 249), 2)img = cv2.putText(img, "class:" + str(clas) + " " + str(round(score, 2)), (xmin, int(ymin) - 5),cv2.FONT_HERSHEY_SIMPLEX, 0.5, (105, 237, 249), 1)return imgtrt_engine = TRT_engine("./best_fp16.engine")
# 使用摄像头进行实时预测
cap = cv2.VideoCapture(0) # 0表示默认摄像头,如果有多个摄像头可以选择其他索引号
while True:ret, frame = cap.read() # 读取一帧图像if not ret:breakresults = trt_engine.predict(frame, threshold=0.5)frame = visualize(frame, results)cv2.imshow("Camera", frame)if cv2.waitKey(1) & 0xFF == ord('q'): # 按下 'q' 键退出循环breakcap.release() # 释放摄像头
cv2.destroyAllWindows()# 预测单张图片
# img = cv2.imread("./data/coffee/images/1.jpg")
# results = trt_engine.predict(img, threshold=0.5)
# img = visualize(img, results)
# cv2.imshow("img", img)
# cv2.waitKey(0)
修改**.engine**路径之后直接运行即可,使用摄像头预测和单张图片预测只能开一个,另一个在运行的时候需要注释掉
这篇关于YOLOv7数据标注、环境配置、训练、预测、trt加速的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



