tesseract专题

Java使用Tesseract-OCR实战教程
《Java使用Tesseract-OCR实战教程》本文介绍了如何在Java中使用Tesseract-OCR进行文本提取,包括Tesseract-OCR的安装、中文训练库的配置、依赖库的引入以及具体的代... 目录Java使用Tesseract-OCRTesseract-OCR安装配置中文训练库引入依赖代码实

基于tesseract实现文档OCR识别
导入环境 导入必要的库 numpy: 用于处理数值计算。 argparse: 用于处理命令行参数。 cv2: OpenCV库,用于图像处理。 import numpy as npimport argparseimport cv2 设置命令行参数 ap = argparse.ArgumentParser()ap.add_argument("-i", "--image", defaul

Win10 + vs2017 编译并配置tesseract-5.0.0-alpha 遇到的问题
使用的cppan安装的依赖 问题1:最大的问题是Leptonica 1.79 cppan出了问题 ,cppan.yml中是空的,导致Leptonica 1.79的依赖没有安装全。 解决方法:这个我是手动下载源码编译的Leptonica ,然后在tesseract 执行后会自动修改 CMakelist.txt 文件加入一下文件的依赖 set(Leptonica_LIBRARIES lepton

java实现ocr功能(Tesseract OCR)
1、pom文件中引入依赖 <dependency><groupId>net.sourceforge.tess4j</groupId><artifactId>tess4j</artifactId><version>4.5.4</version></dependency> 2、下载语言库文件(不要放到resources下,可以放到项目所在目录下,在博主的主页资源菜单下可下载,也可自行在网上找资源
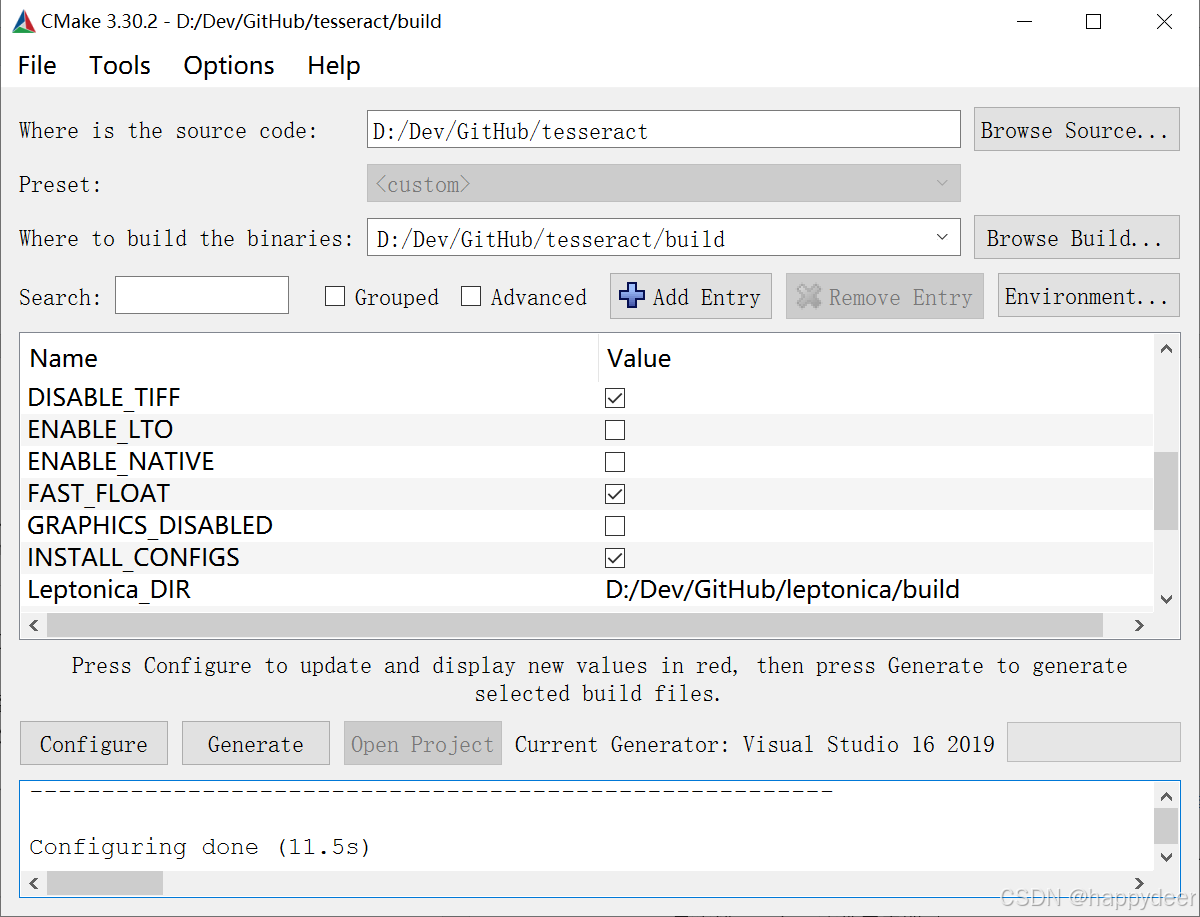
在Windows上用Visual Studio编译Tesseract
Tesseract是著名的OCR(文字识别)开源项目。我想自己编译它的源代码。然而总体而言,大型开源项目在Windows上编译多少都会有些磕磕绊绊,如果有幸最后成功了,都值得写一篇文章来纪念一下。这便是本文的由来。 编译环境:Windows 10(版本1809),Visual Studio 2019(版本16.11.34), CMake 3.30.2 Tesseract依赖于其他开源项目,比如

【深度学习】OCR, 如何使用 Tesseract 进行 OCR 识别
以下是一篇关于如何使用 Tesseract OCR 的中文博客,涵盖了基本的命令行使用方法和一些常见的选项。 如何使用 Tesseract 进行 OCR 识别 介绍 Tesseract 是一个强大的开源 OCR(光学字符识别)引擎,支持多种语言和字符集。它的命令行工具可以将图像中的文本提取为文本文件,广泛应用于文档数字化、数据提取等场景。 安装 Tesseract 在使用 Tessera
msys2 |arch pacman:tesseract ocr 安装 - 思源笔记自动调用
安装之后,思源笔记能自动调用,ocr识别图片中的文字,可被搜索到。 思源笔记 > 使用指南 > 资源文件 中有一些说明。 msys2安装的话:pacman -S ***tesseract***, 包括:软件本体&语言支持包 pacman -S mingw-w64-ucrt-x86_64-tesseract-ocr\mingw-w64-ucrt-x86_64-tesseract-data-c
<tesseract><opencv><Python>基于python和opencv,使用ocr识别图片中的文本并进行替换
前言 本文是在python中,利用opencv处理图片,利用tesseractOCR来识别图片中的文本并进行替换的一种实现方法。 环境配置 系统:windows 平台:visual studio code 语言:python 库:pyqt5、opencv、tesseractOCR 代码介绍 本文程序功能实现,主要依赖于tesseractOCR这个库,它能够识别图片的文字并返回。当然,其识别是

win7 selenium python 验证码识别 pytesser使用 安装Pillow、pytesser、tesseract-ocr
1. win7 Python 2.7.13 安装Pillow Pillow‑4.2.1‑cp27‑cp27m‑win_amd64.whl下载地址 2. 安装Pillow 切换到下载目录pip install Pillow-4.2.1-cp27-cp27m-win_amd64.whl 导入模块没有报错>>> from PIL import Image 3. pytesser

android中tesseract-ocr自定义字库的介绍
看到网上有很多人转载,但是都不太全,自己了点时间研究了下,测试成功!分享出来,大家一起进步。 在网上搜索的一番后发现目前开源的OCR中tesseract-ocr算是比较强大的了,它由HP于1985年到1995年间开发,后来由google直接负责,经过谷歌进一步开发后,目前的tesseract-ocr有了显著的改进。 tesseract-ocr和L
Tesseract-OCR笔记
1、环境配置帖 http://blog.csdn.net/zfdxx369/article/details/9899347/ 其中引用的两个链接比较好,可以用vs2010直接运行。

Tesseract related
知名的开源OCR引擎Tesseract 3.0版本日前发布,可以在项目网站下载:http://code.google.com/p/tesseract-ocr, 新版本支持中文,中文语言包定义http://code.google.com/p/tesseract-ocr/downloads/detail?name=chi_sim.traineddata.gz。 Tesseract是Ray Smith

tesseract文字识别训练记录
1.下载tesseract,并安装 https://digi.bib.uni-mannheim.de/tesseract/,识别汉字的话把汉字库选上additional中找 2.将tesseract,安装的文件夹, 添加到环境变量 3. 安装pytesseract库 pip install pytesseract 4.一段python 小程序识别 #!/usr/bin/e
macos如何安装Tesseract软件and常规应用及问题处理
问题在线过程: 今天在mac系统上安装tesseract持续失败,整了很久终于把这个问题解决了,所以希望通过这篇文章分享给大家: 首先,我在用 brew install tesseract 或 brew install --build-from-source tesseract 一直报错,报错内容如下: Warning: You are using macOS 13.We
macos如何安装Tesseract软件
问题在线过程: 今天在mac系统上安装tesseract持续失败,整了很久终于把这个问题解决了,所以希望通过这篇文章分享给大家: 首先,我在用 brew install tesseract 或 brew install --build-from-source tesseract 一直报错,报错内容如下: Warning: You are using macOS 13.We
centos7安装tesseract
yum-config-manager --add-repo https://download.opensuse.org/repositories/home:/Alexander_Pozdnyakov/CentOS_7/yum updateyum install tesseract yum install tesseract-langpack-deu
OpenCV从入门到精通实战(二)——文档OCR识别(tesseract)
导入环境 导入必要的库 numpy: 用于处理数值计算。 argparse: 用于处理命令行参数。 cv2: OpenCV库,用于图像处理。 import numpy as npimport argparseimport cv2 设置命令行参数 ap = argparse.ArgumentParser()ap.add_argument("-i", "--image", defaul

Ubuntu16.04 源码安装tesseract
必要包安装: sudo apt-get install autoconf automake libtool autoconf-archive pkg-config libpng12-dev libjpeg8-dev libtiff5-dev zlib1g-dev -y 如果要用tesseract自己训练,就需要安装training,那下面这些依赖也要安装: sudo apt-get ins

《OpenCV编译》十五、Tesseract-OCR安装
1、下载地址:https://digi.bib.uni-mannheim.de/tesseract/ github地址:https://github.com/tesseract-ocr/tesseract/releases Tesseract-OCR引擎简介 OCR(Optical Character Recognition):光学字符识别,是指对图片文件中的文字进行分析识别,获取的过程。

tesseract-ocr安装
1.下载地址:https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-w64-setup-v5.0.0-alpha.20210506.exe 其他版本:https://digi.bib.uni-mannheim.de/tesseract/ 2.安装 先不要勾选下面这两个 参考:https://blog.csdn.net/qq_41
图片识别——Tesseract
Tesseract是开源的OCR引擎。Tesseract最初设计用于英文识别,经过改进引擎和训练系统,它能够处理其它语言和UTF-8字符。Tesseract 3.0能够处理任何Unicode字符,但并非在所有语言上都工作得很好。Tesseract在庞大字符集语言(比如中文)上较慢,但是工作良好。 识别: 二值化、灰度、倾斜校正和图片(文字)切割 遍历所有像素点,然后二值化【比如判断RGB值小
使用 Golang 和 Tesseract 库识别验证码
随着网络数据的增长和网络爬虫的普及,网站为了防止恶意爬取数据,经常会采用验证码来进行验证。验证码的出现给爬虫带来了一定的挑战,特别是当验证码的形式越来越复杂时。 在这篇文章中,我们将介绍如何使用 Golang 和 Tesseract 库来识别网站上的验证码。我们会先下载验证码图片,然后使用 Tesseract 库对其进行识别,最后输出识别结果。 准备工作 在开始之前,确保你已经安装了 Gola
tesseract-ocr一站式安装与使用
目录 前言 安装tesseract-ocr 添加环境变量 1、在path中添加 2、在系統變量中添加 3、验证是否添加成功 添加语言包 更多语言包下载 示例程序 前言 如果你遇到了:make sure the TESSDATA_PREFIX Failed loading language \‘chi_sim 那么就是语言包缺少这个!chi_sim!!!请看下面内容 首先,
tesseract OCR引擎怎样安装?
要安装Tesseract OCR引擎,可以按照以下步骤进行操作: 在计算机上安装Tesseract OCR的依赖项。这些依赖项包括Tesseract库、Leptonica图像处理库和语言数据文件。可以使用包管理器(如apt-get、brew或choco)来安装这些依赖项。 下载Tesseract OCR引擎的最新版本。可以从Tesseract OCR的官方GitHub存储库(https://
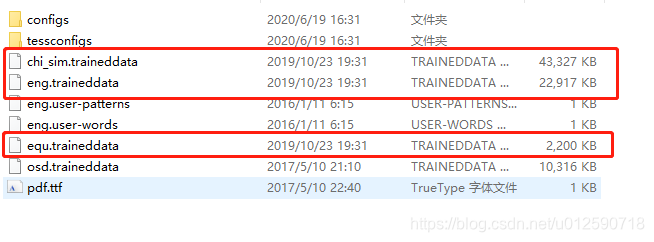
windows安装Tesseract-OCR
windows安装tesseract-ocr 一、安装前准备 1.不同版本 本次使用的是tesseract-ocr-setup-4.00.00dev.exe 2.tesseract-ocr-setup-4.00.00dev.exe 提取码: yd95 3.chi_sim.traineddata 提取码: 34u7 4.eng.traineddata 提取码: 8x7x 5.equ.tra
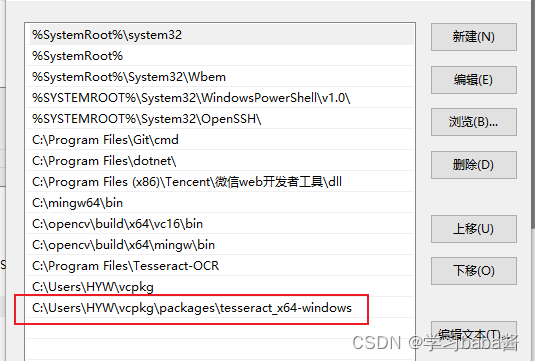
一键部署Tesseract-OCR环境C++版本(Windows)
环境:Windows 10 工具:git vcpkg vscode cmake 库:Tesseract 一键部署Tesseract-OCR环境C++版本(Windows) 分享这篇文章的原因很简单,就是为了让后续的朋友少走弯路。自己在搜索相关C++版本的tesseract部署时,资料实在是少得可怜,基本上都是python版本的,哎,看的真的是难受。希望学习tesseract的朋友不要因为配置环