本文主要是介绍在Windows上用Visual Studio编译Tesseract,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Tesseract是著名的OCR(文字识别)开源项目。我想自己编译它的源代码。然而总体而言,大型开源项目在Windows上编译多少都会有些磕磕绊绊,如果有幸最后成功了,都值得写一篇文章来纪念一下。这便是本文的由来。
编译环境:Windows 10(版本1809),Visual Studio 2019(版本16.11.34), CMake 3.30.2
Tesseract依赖于其他开源项目,比如leptonica——这个项目提供图像文件读写、多格式支持、图像处理等功能。在编译Tesseract之前须先编译leptonica。因为我们已经有了OpenCV来做图像处理,我会把leptonica的编译过程尽量简化(即不编译它的依赖项来支持tiff、png、jpeg等图像格式)。以下是详细步骤,分四步。
Step 1:下载CMake工具
从官网下载最新的zip包,本地解压即可使用。我选的是cmake-3.30.2-windows-x86_64.zip。CMake在开源项目中广为使用,可以将它的路径配置到系统环境变量的Path中,方便调用。
Step 2:编译leptonica
首先从GitHub获取源代码:
$ git clone https://github.com/DanBloomberg/leptonica.git
代码下载完成后,在项目目录下创建一个build文件夹。然后,运行CMake带UI的版本,即cmake-gui.exe,完成“Where is the source code”和“Where to build the binaries”两项配置,就继续点“Configure”按钮,在弹出的对话框里选择“Visual Studio 16 2019”(其他都保持默认设置即可),继续…… 会弹出一个出错提示框,关掉后继续修改配置选项:
- 去掉这些勾选:ENABLE_GIF、ENABLE_JPEG、ENABLE_OPENJPEG、ENABLE_PNG、ENABLE_TIFF、ENABLE_WEBP、ENABLE_ZLIB,因为我们不需要leptonica支持这些图像格式,使用leptonica原生支持的BMP格式足矣。
- 去掉SW_BUILD的勾选。SW是一个强大的包管理器,它会自动下载依赖项,但我们这里不需要它。
然后再次点击“Configure”按钮,不出意外的话就不会有错误弹窗了。截屏留念:
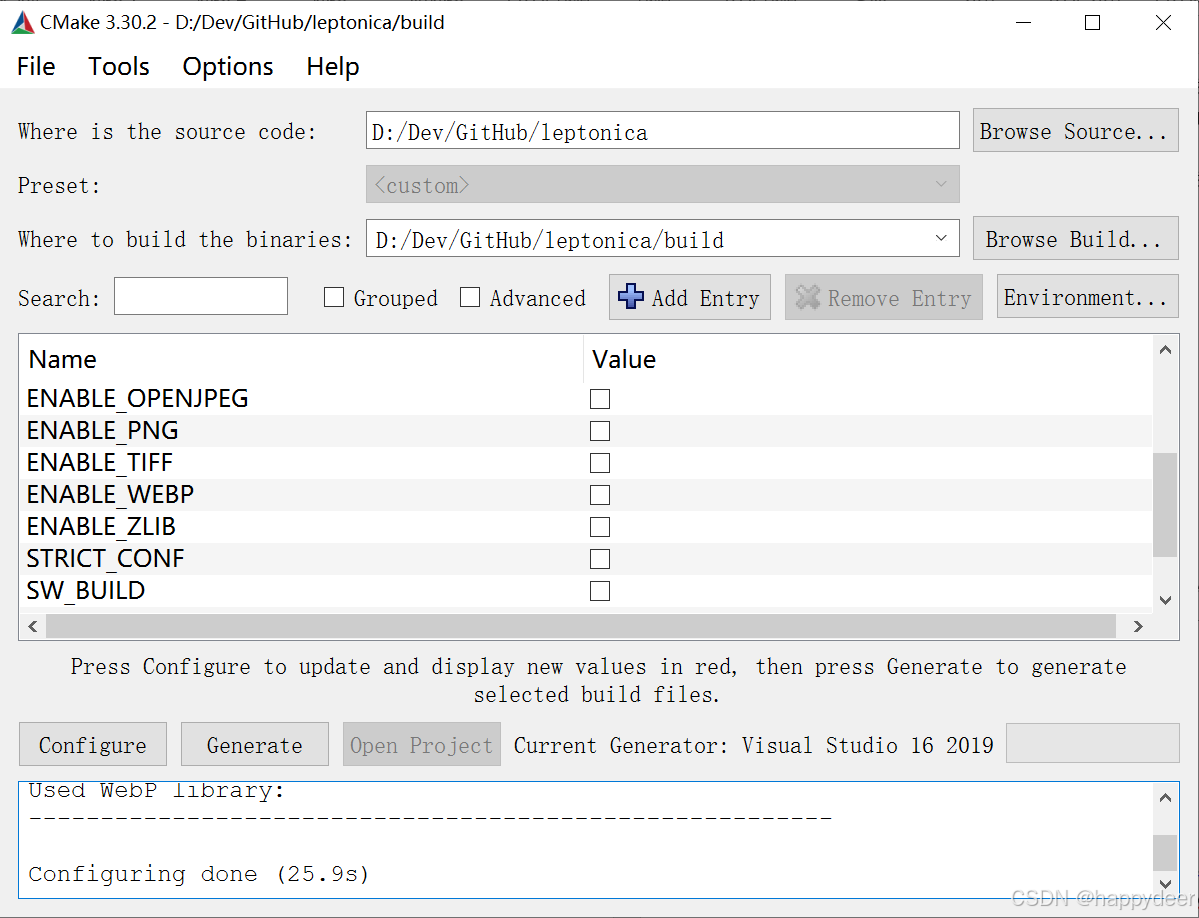
继续点“Generate”按钮生成Visual Studio的编译工程,然后点“Open Project”启动Visual Studio,然后就可以编译啦!遗憾的是,出了一大堆编译错误:
2>C:\Program Files (x86)\Windows Kits\10\Include\10.0.17763.0\um\oaidl.h(487,17): error C2059: 语法错误:“/” (编译源文件 ..\leptonica\src\leptwin.c)
这个问题折腾了比较久…… 解决方法倒也简单,在leptonica项目属性页中,将 “常规” | “C语言标准”改成“默认(旧MSVC)”即可:
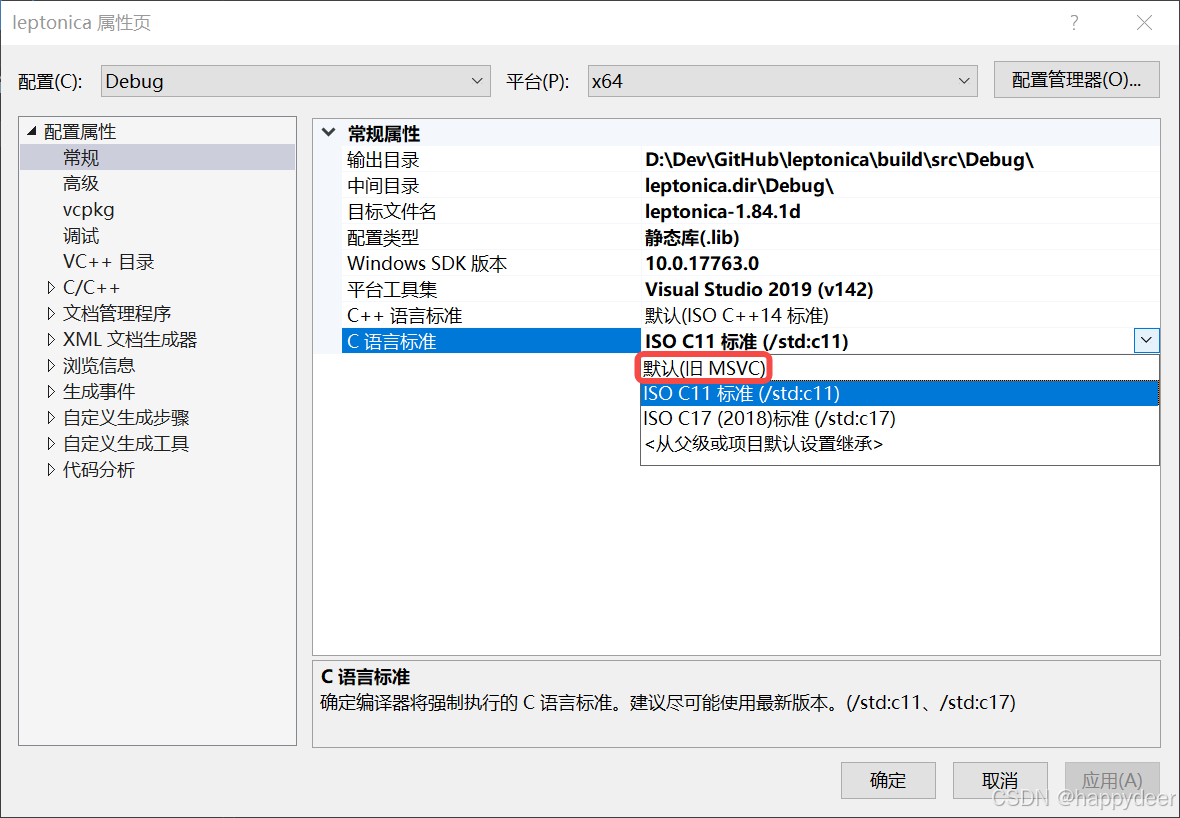
编译通过后,在leptonica\build\src目录下会生成两个库文件:leptonica-1.84.1.lib(Release版)和leptonica-1.84.1d.lib(Debug版)。
Step 3:编译Tesseract
先从GitHub获取源代码吧:
$ git clone https://github.com/tesseract-ocr/tesseract.git
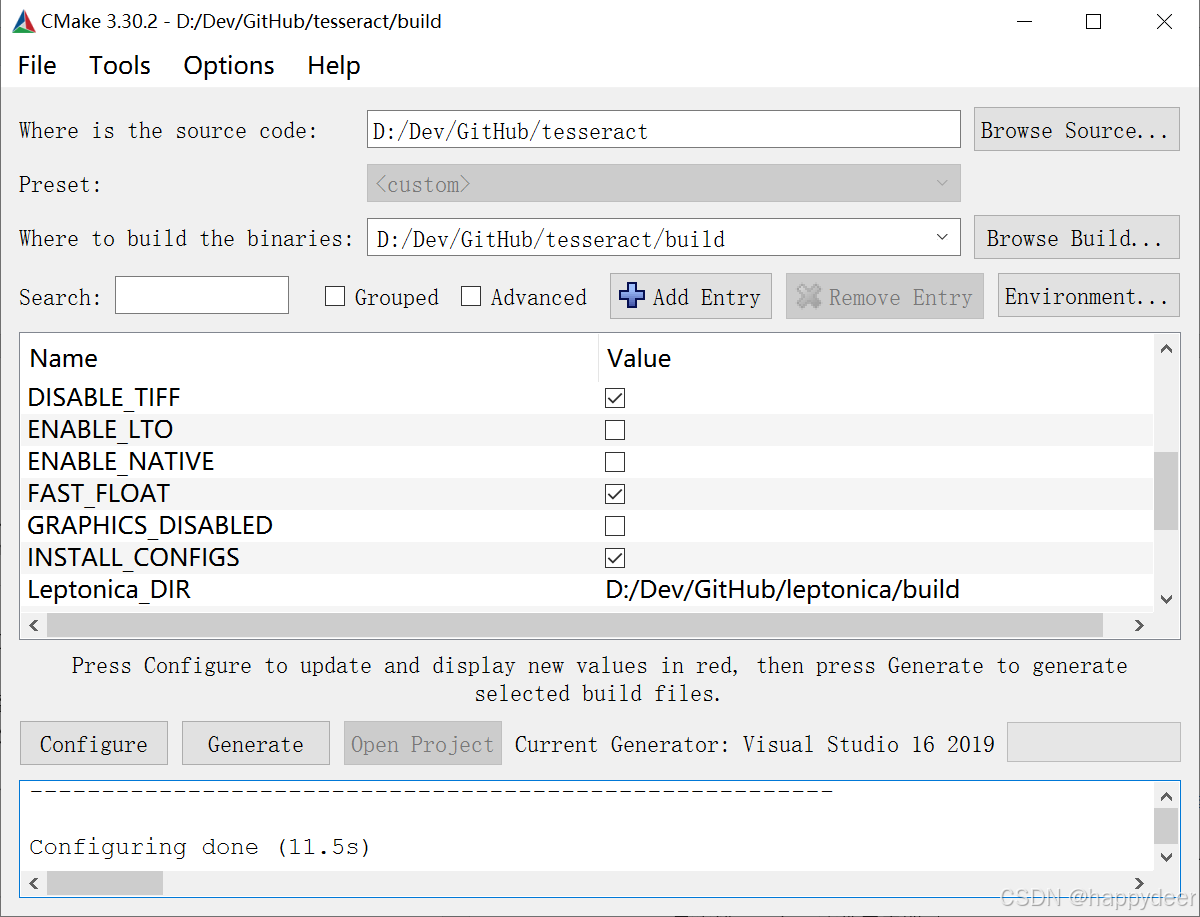
使用CMake的配置过程与leptonica项目有点相似,只是要多点几次“Configure”……
- 下载SW工具。从software-network.org下载 sw-master-windows_x86_64-client.zip,本地解压,并把它的路径加到系统环境变量的Path中。虽然我们实际上不用SW,但这一步配置也是需要的L
- 首次点击“Configure”按钮后,需要去掉SW_BUILD、BUILD_TRAINING_TOOLS的勾选,并勾上DISABLE_TIFF,再次点击“Configure”
- 此时有新的错误提示,需要为Leptonica_DIR指定一个路径。我本机leptonica项目的编译路径是D:\Dev\GitHub\leptonica\build,配置完后再次点击“Configure”
此时,不出意外的话就不会有错误弹窗了,然后“Generate”、“Open Project”一路点下去……截屏留念:
在Visual Studio中开始编译之前,需要修改一下libtesseract的项目配置,因为它对leptonica的包含路径默认是C:\Program Files (x86)\leptonica\include 和 C:\Program Files (x86)\leptonica\include\leptonica,这与实际情况不符,需要在项目属性页的 “C/C++” | “常规” | “附加包含目录” 改为我们在Step 2的真实路径,即:
D:\Dev\GitHub\leptonica\src
D:\Dev\GitHub\leptonica\build\src
我们需要的是Tesseract库(以做二次开发),所以只需要单独编译libtesseract。编译通过后,在tesseract\build目录下会生成两个库文件:tesseract54.lib(Release版)和tesseract54d.lib(Debug版)。
Step 4: 验证Tesseract库
Tesseract和leptonica两个库都编译好了,可喜可贺!严谨起见,我们还需要写一个测试程序来验证一下。用Visual Studio创建一个控制台程序。然后进行如下的项目配置:
属性页 | C/C++ | 常规 | 附加包含目录,添加以下四个目录:
..\leptonica\src; ..\leptonica\build\src; ..\tesseract\include\tesseract; ..\tesseract\build\include
属性页 | 链接器 | 常规 | 附加库目录,添加以下两个目录:
..\leptonica\build\src\$(Configuration)\; ..\tesseract\build\$(Configuration)\
注:我的测试项目tesseract_testapp与tesseract、leptonica两个项目是并级的,所以使用了上述相对路径。你需要根据你本机的实际情况做必要的调整。
属性页 | 链接器 | 输入 | 附加依赖项,添加以下两个.lib文件:
Debug版:leptonica-1.84.1d.lib; tesseract54d.lib
Release版:leptonica-1.84.1.lib; tesseract54.lib;
测试代码如下:
#include "baseapi.h"
#include "allheaders.h"
#include <iostream>int main()
{tesseract::TessBaseAPI* api = new tesseract::TessBaseAPI();// 初始化,加载语言包if (api->Init("tessdata", "eng")) {std::cout << "Could not initialize tesseract" << std::endl;return -1;}// 因为我们编译的leptonica库支持的格式有限,此处用原生支持的BMP来测试Pix* image = pixRead("numbers.bmp");if (image) {api->SetImage(image);char* outText = api->GetUTF8Text();std::cout << "OCR result: " << outText << std::endl;delete[] outText;pixDestroy(&image);}api->End();delete api;return 0;
}注:完整的代码工程可从https://github.com/luqiming666/tesseract_testapp 下载。
在编译运行之前,还需创建一个tessdata文件夹,并在其中放入一份英文版的训练数据。若需要支持更多语言,到https://github.com/tesseract-ocr/tessdata下载后缀名为.traineddata的语言包放到tessdata文件夹内即可。
P.S. 万一你折腾半天,还是没法把Tesseract库成功编译出来,抑或你只是想要一个现成的工具来看看文字识别效果,也可以到https://github.com/UB-Mannheim/tesseract/wiki 下载人家制作好的安装包。拿来即用。安装完成后,运行命令行:tesseract {图片文件路径} {输出结果文件名},给它一个图片文件,它就能把识别结果写入一个文本文件,在自己的项目里凑合着也能用哦——也算是一个万不得已的兜底方案。
这篇关于在Windows上用Visual Studio编译Tesseract的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







