本文主要是介绍tesseract-ocr一站式安装与使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
前言
安装tesseract-ocr
添加环境变量
1、在path中添加
2、在系統變量中添加
3、验证是否添加成功
添加语言包
更多语言包下载
示例程序
前言
如果你遇到了:make sure the TESSDATA_PREFIX Failed loading language \‘chi_sim
那么就是语言包缺少这个!chi_sim!!!请看下面内容
首先,你得找一篇文章了解tesseract-ocr
Tesseract-OCR 是一个开源的光学字符识别引擎,可以用于从图像中提取文本信息。它最初由惠普实验室开发,后来被谷歌收购并开源。Tesseract 可以识别多种语言,并且在处理复杂的文档布局时表现良好。
Tesseract 使用的是深度学习和模式识别算法来识别图像中的字符,并将其转换成计算机可处理的文本数据。它支持多种操作系统,包括 Windows、Linux 和 macOS,并提供了多种编程语言的接口,比如 Python、Java 和 C++,使得开发者可以方便地集成到各种应用程序中进行文字识别。
Tesseract-OCR 被广泛应用于文档处理、图像识别、自动化办公、数字化档案等领域,为用户提供了快速、准确地从图像中提取文本的能力。
今天给同学跑项目,他的项目用到了tesseract-ocr
结果搞半天,百度出来的CSDN链接,下载那些包,还全部要钱,大无语...
总结:
1、直接开着梯子去GitHub下载最新版的【tesseract-ocr】
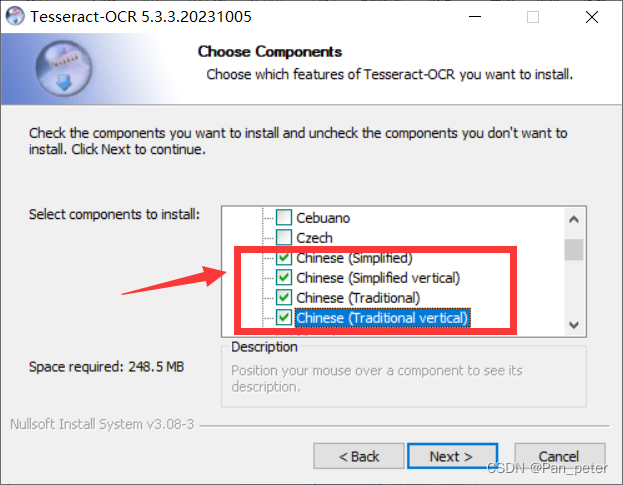
2、然后直接选择需要识别的语言类型(一般我们需要识别中文的,就选择一下中文就行了)
安装包+中文识别语言包,我都放在蓝奏云了,可以直接安装,然后跑demo
跟着下面教程内容走就行了
最后就可以直接跑demo了!
安装tesseract-ocr
Releases · UB-Mannheim/tesseract (github.com) 直接进去下载最新版即可
安装包——蓝奏云备份:
tesseract-ocr-w64-setup-5.3.3.20231005.zip - 蓝奏云文件大小:47.8 M|
https://wwm.lanzout.com/i8bPj1tzz21e

接下来一路ok就行了——就只有在语言下载那里,需要开梯子
需要开梯子
需要开梯子
需要开梯子
不然会下载语言包失败!!!
不然会下载语言包失败!!!
不然会下载语言包失败!!!
注意这里!!!
注意这里!!!
注意这里!!!
自己记着安装路径——以后要加环境变量
自己记着安装路径——以后要加环境变量
自己记着安装路径——以后要加环境变量



添加环境变量
1、在path中添加
tesseract-ocr ——【找到自己的安装路径】
我的:D:\Tesseract-OCR

2、在系統變量中添加
变量名:TESSDATA_PREFIX
变量值:D:\Tesseract-OCR\tessdata

3、验证是否添加成功
打开cmd ->输入命令
tesseract -v

添加语言包
语言包下载
如果你没有梯子,在这里下载失败了,就可以单独下载语言包
如果你没有梯子,在这里下载失败了,就可以单独下载语言包
如果你没有梯子,在这里下载失败了,就可以单独下载语言包
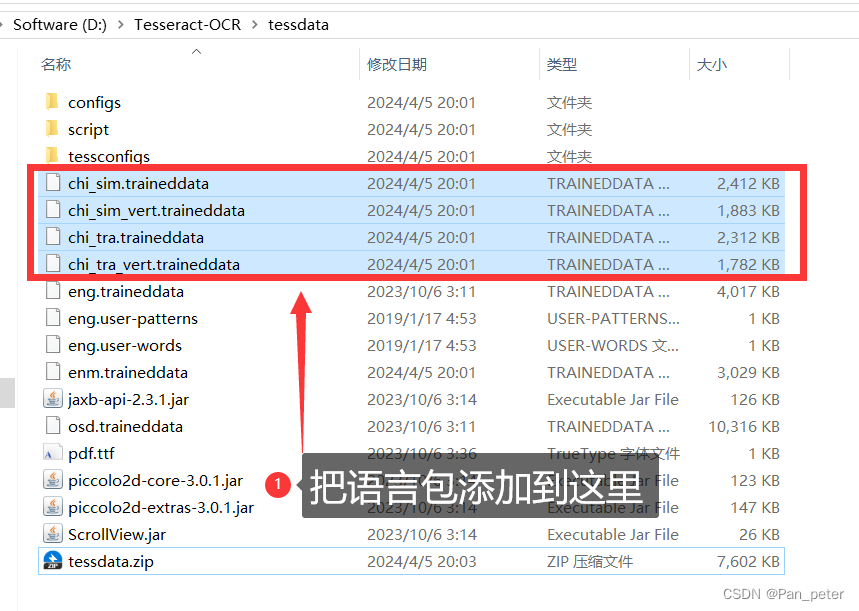
蓝奏云备份(这里是中文语言包):
tessdata语言包-中文+英文.zip - 蓝奏云文件大小:7.4 M|
把语言包——放在这里面就行了!!!
把语言包——放在这里面就行了!!!
更多语言包下载
GitCode - 开发者的代码家园
示例程序
pip install Pillow pytesseractfrom PIL import Image
import pytesseract# 使用 pytesseract 进行文字识别,lang 参数指定识别语言为简体中文
text = pytesseract.image_to_string(Image.open(r'D:\333.png'),lang='chi_sim')
print(text)
其他
from PIL import Image
import pytesseract# 设置 Tesseract 路径(根据你的安装路径修改)
pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files (x86)\Tesseract-OCR\tesseract.exe"# 打开图像文件
image_path = r'D:\333.png'
image = Image.open(image_path)# 使用 pytesseract 进行文字识别,lang 参数指定识别语言为简体中文
text = pytesseract.image_to_string(image, lang='chi_sim')# 打印识别结果
print(text)
这篇关于tesseract-ocr一站式安装与使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




