sparkstreaming专题

实时数仓链路分享:kafka =SparkStreaming=kudu集成kerberos
点击上方蓝色字体,选择“设为星标” 回复”资源“获取更多资源 大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 暴走大数据 点击右侧关注,暴走大数据! 本文档主要介绍在cdh集成kerberos情况下,sparkstreaming怎么消费kafka数据,并存储在kudu里面 假设kafka集成kerberos假设kudu集成kerberos假设用非root用户操作spark基

sparkstreaming的实时黑名单过滤太慢
官网推荐如下这种方法进行过滤,但是这种方法其实有很大弊端,left out join如果黑名单数据量很大就会很伤,其实真不好。 object TransformBlackList {def main(args: Array[String]): Unit = {//获取streamingContextval sc=new StreamingContext(new SparkConf().setAp

Spark学习笔记 --- SparkStreaming 中基本概念
StreamingContext StreamingContext 是Spark Streaming程序的入口点,正如SparkContext是Spark程序的入口点一样。
理解SparkStreaming的Checkpointing
streaming 应用程序必须 24 * 7 运行, 因此必须对应用逻辑无关的故障(例如, 系统故障, JVM 崩溃等)具有弹性. 为了可以这样做, Spark Streaming 需要 checkpoint 足够的信息到容错存储系统, 以便可以从故障中恢复.checkpoint 有两种类型的数据. Metadata checkpointing - 将定义 streaming 计算的信息
【SparkStreaming】面试题
Spark Streaming 是 Apache Spark 提供的一个扩展模块,用于处理实时数据流。它使得可以使用 Spark 强大的批处理能力来处理连续的实时数据流。Spark Streaming 提供了高级别的抽象,如 DStream(Discretized Stream),它代表了连续的数据流,并且可以通过应用在其上的高阶操作来进行处理,类似于对静态数据集的操作(如 map、reduce、

SparkStreaming编程-DStream输出
输出操作指定了对流数据经转化操作得到的数据所要执行的操作(例如把结果推入外部数据库或输出到屏幕上)。与RDD中的惰性求值类似,如果一个DStream及其派生出的DStream都没有被执行输出操作,那么这些DStream就都不会被求值。如果StreamingContext中没有设定输出操作,整个context就都不会启动。 常见的输出操作函数如下:print()、saveAsTextFil
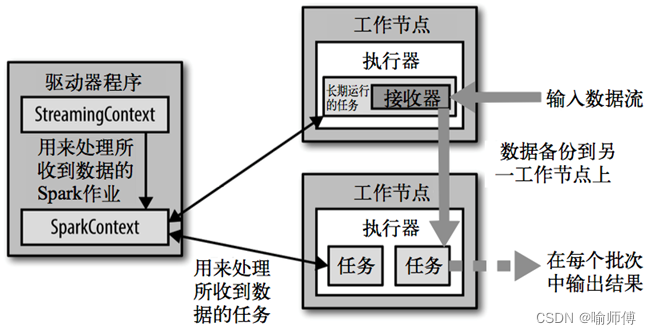
SparkStreaming架构原理(详解)
Spark概述 SparkStreaming架构原理 Spark Streaming的架构主要由以下几个关键部分组成。 1.数据源接收器(Receiver) 执行流程开始于数据源接收阶段,其中接收器(Receiver)负责从外部数据源获取数据流。 接收器可以连接到诸如Kafka、Flume、Kinesis等数据源,或直接通过网络套接字接收数据。 接收器的主要功能是接收数据并

CDH-Kafka-SparkStreaming 异常:org.apache.kafka.clients.consumer.KafkaConsumer.subscribe(Ljava/uti
参考文章: flume kafka sparkstreaming整合后集群报错org.apache.kafka.clients.consumer.KafkaConsumer.subscribe(Ljava/ut https://blog.csdn.net/u010936936/article/details/77247075?locationNum=2&fps=1 最近在使用CD

36_SparkStreaming二—编程
SparkStreaming编程 1 Transformation 高级算子 1.1 updateStateByKey /*** 单词计数** Driver服务:* 上一次 运行结果,状态* Driver服务* 新的数据**/object UpdateStateBykeyWordCount {def main(args: Array[String]): Unit = {v
35_SparkStreaming一
SparkStreaming 1 实时任务简介 Spark流是对于Spark核心API的拓展,从而支持对于实时数据流的可拓展,高吞吐量和容错性流处理。数据可以由多个源取得,例如:Kafka,Flume,Twitter,ZeroMQ,Kinesis或者TCP接口,同时可以使用由如map,reduce,join和window这样的高层接口描述的复杂算法进行处理。最终,处理过的数据可以被推送到文件系
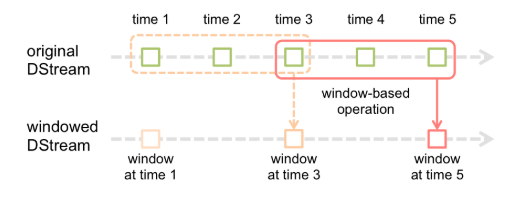
SparkStreaming的窗口
目录 1.window(windowLength, slideInterval)2.countByWindow(windowLength,slideInterval)3.countByValueAndWindow4.reduceByWindow(func, windowLength,slideInterval) 窗口函数,就是在DStream流上,以一个可配置的长度为窗口,以一个
1.8.8 大数据-SparkStreaming-Kafka集成
IDEA客户端MAVEN POM中引入Linux JAR包放入 jars目录或者执行jar包时 引入jar包启动kafka传输消息 bin/kafka-server-start.sh -daemon config/server.propertiesbin/kafka-console-producer.sh --broker-list bigdata-pro01.kfk.com:9092 --t
1.8.7 大数据-Spark-SparkStreaming实时流处理(保存到Mysql)
演练环境搭建 安装nc 作为输出流 [kfk@bigdata-pro03 softwares]$ sudo rpm -ivh nc-1.84-22.el6.x86_64.rpm Preparing... (100%################################
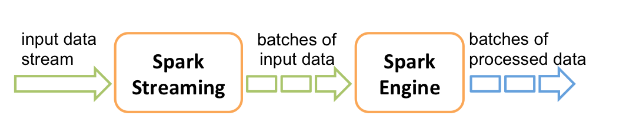
Spark官方文档-SparkStreaming
概述 Spark Streaming 是核心 Spark API 的扩展,它支持实时数据流的可扩展、高吞吐量、容错流处理。支持多个数据源操作,Kafka, Kinesis, or TCP sockets等;并且可以使用复杂算法来处理数据,像高级别功能表达map,reduce,join和window。 在内部,它的工作原理如下。Spark Streaming 接收实时输入的数据流,并将数据分

SparkStreaming在实时处理的两个场景示例
简介 Spark Streaming是Apache Spark生态系统中的一个组件,用于实时流式数据处理。它提供了类似于Spark的API,使开发者可以使用相似的编程模型来处理实时数据流。 Spark Streaming的工作原理是将连续的数据流划分成小的批次,并将每个批次作为RDD(弹性分布式数据集)来处理。这样,开发者可以使用Spark的各种高级功能,如map、reduce、join等,来

大数据-SparkStreaming(九)
大数据-SparkStreaming(九) SparkStreaming调优 调整BlockReceiver的数量 案例演示: val kafkaStream = { val sparkStreamingConsumerGroup = "spark-streaming-consumer-group" val kafkaParams

大数据-SparkStreaming(七)
大数据-SparkStreaming(七) SparkStreaming语义 At most once 一条记录要么被处理一次,要么没有被处理。At least once 一条记录可能被处理一次或者多次,可能会重复处理。Exactly once 一条记录只被处理一次,它最严格,实现起来也是比较困难。数据被处理且只被处理一次。 SparkStr

大数据-SparkStreaming(六)
大数据-SparkStreaming(六) 数据丢失如何处理 利用WAL把数据写入到HDFS中 步骤一:设置checkpoint目录 streamingContext.setCheckpoint(hdfsDirectory) 步骤二:开启WAL日志 sparkConf.set("spark.streaming.recei

大数据-SparkStreaming(五)
大数据-SparkStreaming(五) SparkStreaming和SparkSQL整合 pom.xml里面添加 <dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.11</artifactId><version>2.3.3</version></d

大数据-SparkStreaming(二)
大数据-SparkStreaming(二) 数据源 socket数据源 需求:sparkStreaming实时接收socket数据,实现单词计数 业务处理流程图 安装socket服务 首先在linux服务器node01上用yum 安装nc工具,nc命令是netcat命令的简称,它是用来设置路由器。我们可以利用它向某个端口发送数据

SparkStreaming wordcount demo
流数据统计,将每隔10s内的数据做一次单词统计 package com.streamingimport org.apache.spark.streaming._import org.apache.spark.streaming.StreamingContext._import org.apache.spark.SparkContextimport org.apache.spark.api.
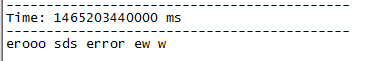
SparkStreaming 删选含有error的行
筛选流数据中所有含error的行 package com.streamingimport org.apache.spark.SparkConfimport org.apache.spark.streaming.Secondsimport org.apache.spark.streaming.StreamingContextobject PrintError {def main(args:
SparkStreaming 打印输出demo
1.nc -lk 9999 -l 使用监听模式,管控传入的资料。 本机开启9999端口 一个server对应一个client,多了可能出问题,也就是下次起sparkstreaming任务时,必须先关了这个端口,重开 2.提交sparkstreaming任务 package com.streamingimport org.apache.spark.streaming.Secondsi

SparkStreaming---DStream
文章目录 1.DStream是什么2.DStream创建2.1 RDD队列2.2 自定义数据源 3.DStream转换3.1 无状态转换3.1.1 Transformations3.1.2 join 3.2 有状态转换操作3.2.1 UpdateStateByKey3.2.2 WindowOperations 4.DStream输出 1.DStream是什么 参考博文Spark
spark之sparkStreaming实时流处理
1、sparkStream官网 http://spark.apache.org/streaming/ 2、什么是sparksreaming? sparkStreamin是一种构建在spark之上的实时计算框架,他扩展了spark处理打过莫流失数据的能力,吞吐量高,容错能力强。(对标hadoop中storm) 3、处理数据方式 sparkStreaming将输入的数据按照时间为单位
一个用Kakfa低级api的SparkStreaming程序实例
spark2.4以后可以用structStreaming 低级api消费:KafkaUtils.createDirectStream方式 这种方式不同于Receiver(高级api)接收数据,它定期地从kafka的topic下对应的partition中查询最新的偏移量,再根据偏移量范围在每个batch里面处理数据,Spark通过调用kafka简单的消费者Api(低级api)读取