本文主要是介绍Spark官方文档-SparkStreaming,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
概述
Spark Streaming 是核心 Spark API 的扩展,它支持实时数据流的可扩展、高吞吐量、容错流处理。支持多个数据源操作,Kafka, Kinesis, or TCP sockets等;并且可以使用复杂算法来处理数据,像高级别功能表达map,reduce,join和window。



在内部,它的工作原理如下。Spark Streaming 接收实时输入的数据流,并将数据分成批处理,然后由 Spark 引擎处理以批处理生成最终的结果流。
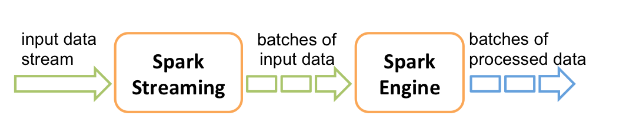
Spark Streaming 提供了一种称为离散流或DStream的高级抽象,它表示连续的数据流。DStreams 可以从来自 Kafka 和 Kinesis 等来源的输入数据流创建,也可以通过在其他 DStreams 上应用高级操作来创建。在内部,DStream 表示为一系列 RDD。
一个简单的例子
StreamingContext是所有流功能的主要入口点。我们创建了一个具有两个执行线程的本地 StreamingContext,批处理间隔为 1 秒。
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._ // not necessary since Spark 1.3// Create a local StreamingContext with two working thread and batch interval of 1 second.
// The master requires 2 cores to prevent a starvation scenario.val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))使用这个上下文,我们可以创建一个 DStream 来表示来自 TCP 源的流数据,指定为主机名(例如localhost)和端口(例如9999)。
// Create a DStream that will connect to hostname:port, like localhost:9999
val lines = ssc.socketTextStream("localhost", 9999)此linesDStream 表示将从数据服务器接收的数据流。此 DStream 中的每条记录都是一行文本。接下来,我们要按空格字符将行拆分为单词。
// Split each line into words
val words = lines.flatMap(_.split(" "))flatMap是一对多的 DStream 操作,它通过从源 DStream 中的每个记录生成多个新记录来创建新的 DStream。在这种情况下,每行将被拆分为多个单词,单词流表示为 wordsDStream。接下来,我们要计算这些单词。
import org.apache.spark.streaming.StreamingContext._ // not necessary since Spark 1.3
这篇关于Spark官方文档-SparkStreaming的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




