snowflake专题

哈希—— POJ 3349 Snowflake Snow Snowflakes
对应POJ题目:点击打开链接 Snowflake Snow Snowflakes Time Limit: 4000MS Memory Limit: 65536KTotal Submissions: 33595 Accepted: 8811 Description You may have heard that no two snowflakes are alike. Y
《前端攻城狮 · Snowflake 雪花算法》
📢 大家好,我是 【战神刘玉栋】,有10多年的研发经验,致力于前后端技术栈的知识沉淀和传播。 💗 🌻 CSDN入驻不久,希望大家多多支持,后续会继续提升文章质量,绝不滥竽充数,欢迎多多交流。👍 文章目录 写在前面的话利用现有库自定义实现雪花ID和UUID总结陈词 写在前面的话 雪花 ID 是一种分布式唯一 ID 生成算法,通常由 Twitter 提出的。它的

Twitter的分布式自增ID算法snowflake - C#版
概述 分布式系统中,有一些需要使用全局唯一ID的场景,这种时候为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,另外UUID一般是无序的。有些时候我们希望能使用一种简单一些的ID,并且希望ID能够按照时间有序生成。而twitter的snowflake解决了这种需求,最初Twitter把存储系统从MySQL迁移到Cassandra,因为Cassandra没有顺序I
poj3349 Snowflake Snow Snowflakes
大致题意: 在n (n<100000)个雪花中判断是否存在两片完全相同的雪花,每片雪花有6个角,每个角的长度限制为1000000 两片雪花相等的条件: 雪花6个角的长度按顺序相等(这个顺序即可以是顺时针的也可以是逆时针的) 大概思路: 用连加求余法求key值(用同余定理简化),链地址法解决冲突 写好左旋转模块和右旋转模块,进行地址冲突之后的比较 边插入边比较

全局唯一ID生成常见的几种方式和twitter/snowflake(雪花算法)解析
全局唯一ID生成常见的几种方式和twitter/snowflake(雪花算法)解析 全局唯一ID生成常见的几种方式: 1,(twitter/snowflake)雪花算法 2,利用数据库的auto_increment特性 3,UUID 4,其他(如redis也有incr,redis加lua脚本实现twitter/snowflake算法) 一、 (twitter/snowflake

(Snowflake Algorithm)雪花算法Java的简单使用
概述 雪花算法(Snowflake Algorithm)最初是由Twitter开源的,用于生成一个64位的长整型数字作为全局唯一的ID。这个算法是用Scala语言编写的,并且在Twitter内部得到了广泛应用。由于其简单、高效和分布式友好的特性,雪花算法后来也被其他很多公司和项目采用,并可能被移植到其他编程语言中实现。 其结构如下: 第一位:未使用,因为二进制中最高位是符号位,正数是0,负数
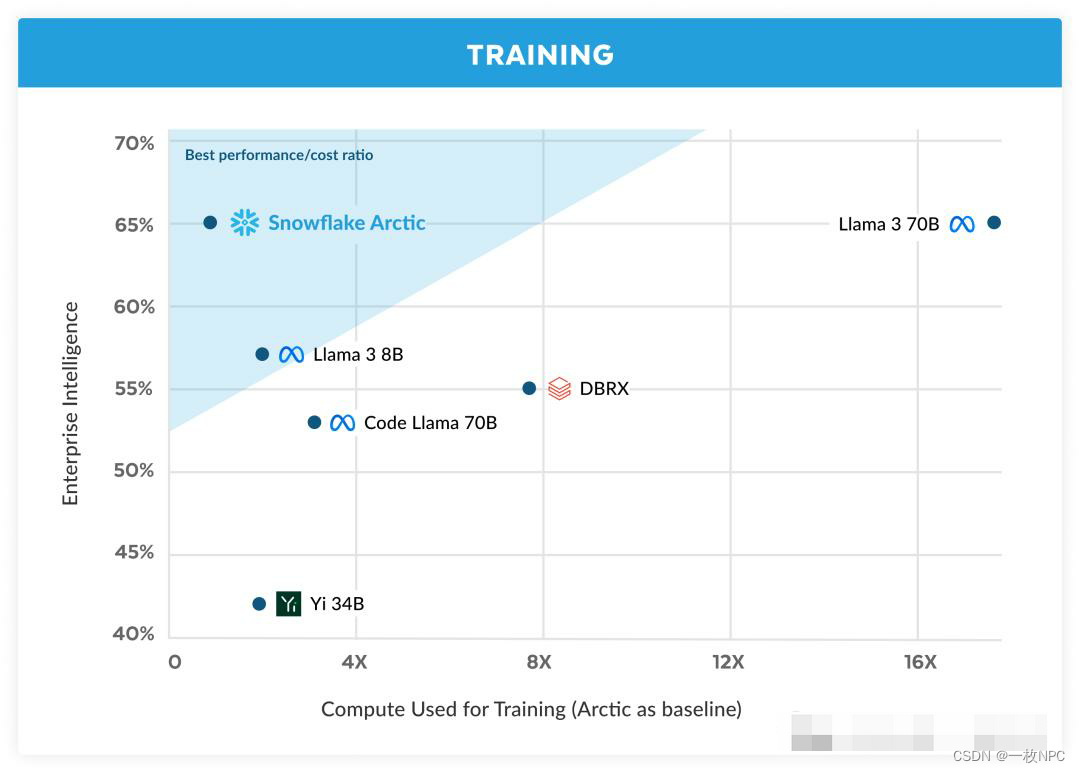
仅需Llama3 1/17的训练成本,全球最大开源模型Arctic问世:Snowflake携128位专家系统重塑AI未来
在人工智能领域,模型的大小往往与性能成正比,而模型的开放程度则决定了其应用范围和影响力。今天,云计算巨头Snowflake携其AI研究团队,发布了一款名为Arctic的的开源企业级大型语言模型,该模型以128位专家和惊人的4800亿参数,成功刷新了全球最大开源模型的纪录,为AI的未来发展描绘出了一幅崭新的蓝图。 Arctic的诞生,无疑为人工智能领域注入了新的活力。这款由Snowflake精心打
POJ 3349 Snowflake Snow Snowflakes hash
题意:每个雪花有六个角,每个角用一个数字表示。输入n个雪花,若存在两个雪花相等则输出Twin snowflakes found。否则输出No two snowflakes are alike. 题解:hash #include <iostream>#include <cstdlib>using namespace std;#define Prime 14997struct ListNode

Django如何使用snowflake自定义生成主键而不是自动生成主键?
之前ID都是用自增实现的,那现在想用Snowflake算法生成主键,要做什么改动呢? 目录 背景介绍实现方案方案1 - 手动添加主键方案2 - 重写save()方法方案3 - 使用 Django Signals 中的pre_save()方案4 - 仿照models.UUIDField,写一个models.SnowflakeIDField 总结 背景介绍 目前工程框架如下

企业如何使用SNP Glue将SAP与Snowflake集成?
SNP Glue是SNP的集成技术,适用于任何云平台。它最初是围绕SAP和Hadoop构建的,现在已经发展为一个集成平台,虽然它仍然非常专注SAP,但可以将几乎任何数据源与任何数据目标集成。 我们客户非常感兴趣的数据目标之一是Snowflake。Snowflake是一个基于云的数据仓库平台,旨在处理和分析大量数据。它是一种软件即服务(SaaS)解决方案,允许组织使用云基础设施存储、管理和分析

使用 Meltano 将数据从 Snowflake 导入到 Elasticsearch:开发者之旅
作者:来自 Elastic Dmitrii Burlutskii 在 Elastic 的搜索团队中,我们一直在探索不同的 ETL 工具以及如何利用它们将数据传输到 Elasticsearch,并在传输的数据上实现 AI 助力搜索。今天,我想与大家分享我们与 Meltano 生态系统以及 Meltano Elasticsearch 加载器的故事。 Meltano 是一个声明式的代码优先数据集
使用Twitter的Snowflake设置分布式自增长ID
十次方项目工具类IdWorker.java 描述:使用Twitter的Snowflake雪花算法设置分布式自增长ID import java.lang.management.ManagementFactory;import java.net.InetAddress;import java.net.NetworkInterface;/*** <p>名称:IdWorker.java</p>
Snowflake Snow Snowflakes (POJ - 3349 ,Hash表查找)
一.题目链接: POJ-3349 二.题目大意: 有 n 片雪花,每片雪花有六个角,若六个角均相同,则称两片雪花相等. 雪花六个角的记录可能顺时针,可能逆时针,开始点不确定. 让你判断是否存在两片相同的雪花. 三.分析: 居然还有考 Hash 表的题 一直觉得数据结构课本很鸡肋 题目不难,这里只是存个板子. 哈希函数选用除留余数法,利用链地址法处理冲突. 四.代码实现: #i
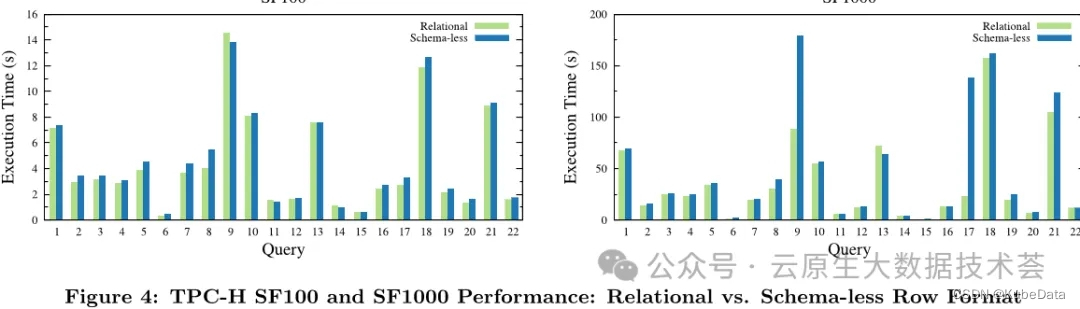
云数据仓库Snowflake论文完整版解读
本文是对于Snowflake论文的一个完整版解读,对于从事大数据数据仓库开发,数据湖开发的读者来说,这是一篇必须要详细了解和阅读的内容,通过全文你会发现整个数据湖设计的起初原因以及从各个维度(架构设计、存算分离、弹性伸缩、查询优化、故障恢复、性能优化等等)展开而来的设计思路。 可能内容本身站在当下并不显得新颖和具备创意,但是从2012年那个时候,云计算和大数据也才刚刚普及不久,在以结构化数据分析
nodejs的中雪花算法(Snowflake)
介绍 雪花算法(Snowflake)是Twitter开发的一种分布式唯一ID生成算法,用于生成全局唯一的ID。雪花算法的核心思想是利用时间戳和机器ID来生成唯一的ID,确保在分布式环境下生成的ID不会重复。 雪花算法生成的ID是一个64位的整数,其中包含以下几个部分: 1位符号位,始终为0。41位的时间戳,精确到毫秒级,可以表示的时间范围约为69年。10位的机器ID,可以部署1024台机器。
Snowflake Snow Snowflakes POJ - 3349 hash表问题
题意是给出一组雪花的6个角的值,判断通过比较是否能发现两片相同的雪花。 主要利用了hash表的映射,计算每个雪花的key值,如果不存在以此key值为键的hash表,则新建一个,若存在则查找hash表, 如果有则标记Find为ture 否则通过hash重映射方法,继续向以此key值为键的hash表添加数据。 判断的时候需要分顺时针和逆时针两种比较方法。 #includ
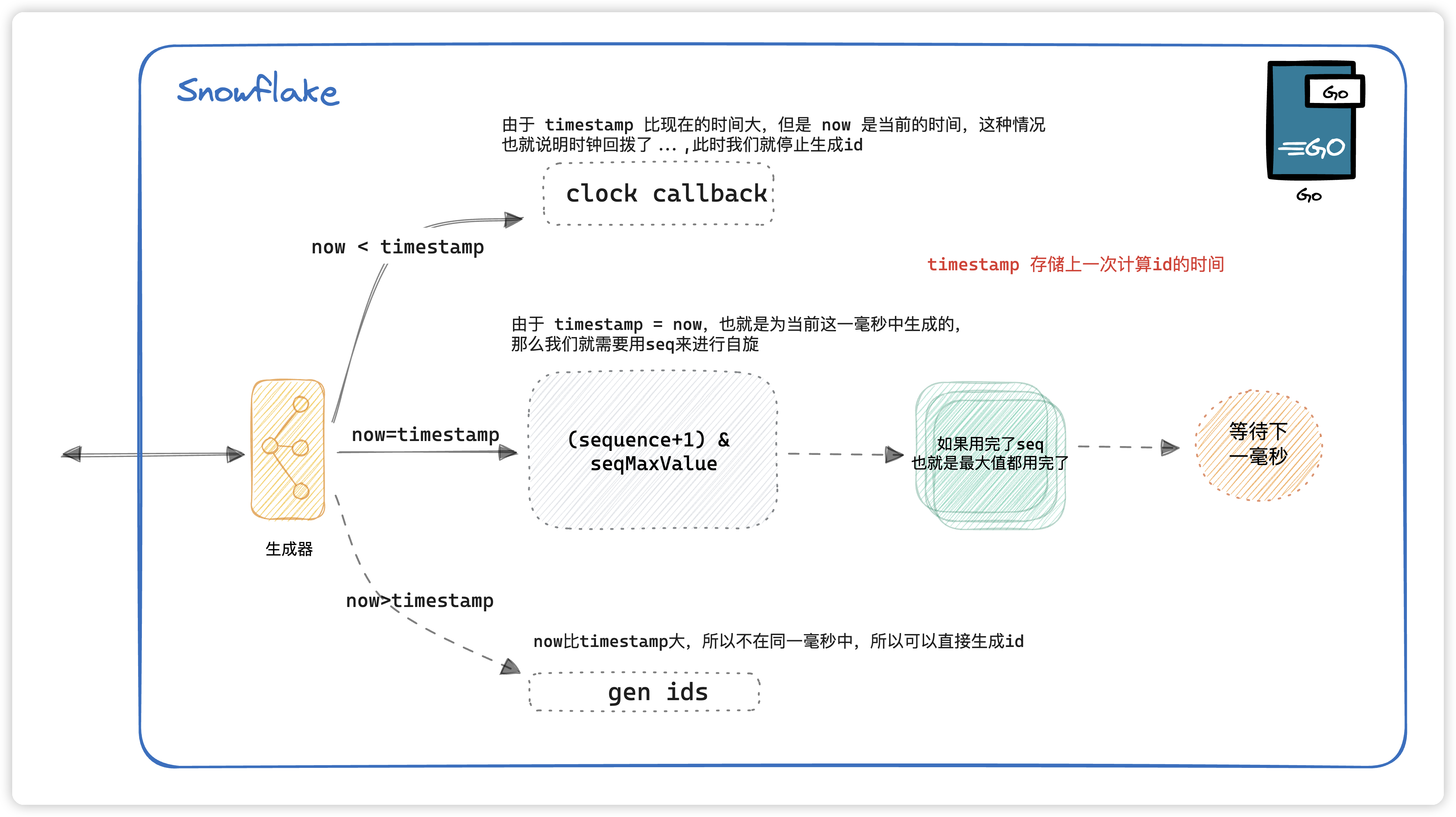
分布式ID生成算法|雪花算法 Snowflake | Go实现
写在前面 在分布式领域中,不可避免的需要生成一个全局唯一ID。而在近几年的发展中有许多分布式ID生成算法,比较经典的就是 Twitter 的雪花算法(Snowflake Algorithm)。当然国内也有美团的基于snowflake改进的Leaf算法。那么今天我们就来介绍一下雪花算法。 雪花算法 算法来源: 世界上没有完全相同的两片雪花 。所以!雪崩的时候,没有任何一片雪花是相同的! 雪花

分布式ID生成策略-雪花算法Snowflake
分布式ID生成策略-雪花算法Snowflake 一、其他分布式ID策略1.UUID2.数据库自增与优化2.1 优化1 - 共用id自增表2.2 优化2 - 分段获取id 3.Reids的incr和incrby 二、雪花算法Snowflake1.雪花算法的定义2.基础雪花算法源码解读3.并发1000测试4.如何设置机房和机器id4.雪花算法时钟回拨问题 这里主要总结雪花算法,其他的分
Twitter Snowflake
http://blog.yxwang.me/2012/08/twitter-snowflake/ 这是一篇两年前 Twitter 开发团队写的文章,今天挖出来研究了一下。原文地址 http://engineering.twitter.com/2010/06/announcing-snowflake.html Twitter 早期用 MySQL 存储数据,随着用户的增长,单一的 M
Twitter的Snowflake算法生成唯一订单号配置类
package com.ten.utils;/*** @author ChenYanbing* @title: UniqueOrderGenerate* @projectName tencent-demo* @description: TODO* @date 2019/8/19:39*//*** Twitter_Snowflake<br>* SnowFlake的结构如下(每部分用-分开):<br>
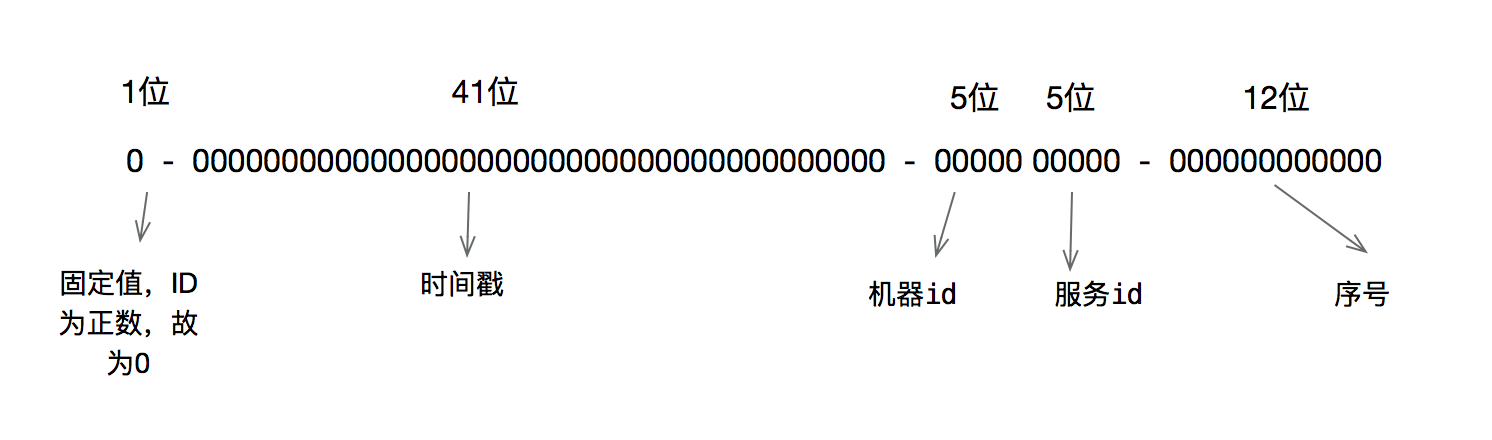
雪花算法(Snowflake)介绍和Java实现
1、雪花算法介绍 (1) 雪花算法(SnowFlake)是分布式微服务下生成全局唯一ID,并且可以做到去中心化的常用算法,最早是Twitter公司在其内部的分布式环境下生成ID的方式。 雪花算法的名字可以这么理解,世界上没有两片完全相同的雪花,而雪花算法希望自己生成的ID是独一无二的。 去中心化可以理解成不需要依赖某一个中间件,比如可以用Redis来生成全局唯一的ID,但Redis此时就属于
Dataiku宣布获得Snowflake战略投资,赋能企业通过数据云中的高级分析来创造更多价值
纽约--(美国商业资讯)--全球领先的人工智能(AI)与机器学习平台之一Dataiku今天宣布获得一笔来自Snowflake旗下风投子公司Snowflake Ventures的新投资。Dataiku和Snowflake将携手提供可供企业运用的AI功能,使客户能够轻松快速地构建、部署和监管各类数据科学项目,包括机器学习和深度学习。 在Dataiku的支持下,Snowflake的客户可以获得独
利用Redis实现集群或开发环境下SnowFlake自动配置机器号
前言: 系统流小说 wap.kuwx.net SnowFlake 雪花ID 算法是推特公司推出的著名分布式ID生成算法。利用预先分配好的机器ID,工作区ID,机器时间可以生成全局唯一的随时间趋势递增的Long类型ID.长度在17-19位。随着时间的增长而递增,在MySQL数据库中,InnoDB存储引擎可以更快的插入递增的主键。而不像UUID那样因为写入是乱序的,InnoDB不得不频繁的做页分裂
在打日志时,如何使用snowflake-id快速方便得随机获取query的唯一id
步骤一:安装snowflake-id pip install snowflake-id 步骤二:代码示例 from snowflake import SnowflakeGeneratorgen = SnowflakeGenerator(42)for i in range(100):val = next(gen)print(val) 参考文档: https://pypi.org/pro
Twitter-Snowflake:自增ID算法
简介 Twitter 早期用 MySQL 存储数据,随着用户的增长,单一的 MySQL 实例没法承受海量的数据,后来团队就研究如何产生完美的自增ID,以满足两个基本的要求: 每秒能生成几十万条 ID 用于标识不同的 记录;这些 ID 应该可以有个大致的顺序,也就是说发布时间相近的两条记录,它们的 ID也应当相近,这样才能方便各种客户端对记录 进行排序。 Twitter-Snowflake算法
分布式唯一ID生成器Twitter 的 Snowflake idworker java版本
import java.lang.management.ManagementFactory;import java.net.InetAddress;import java.net.NetworkInterface;/** * <p>名称:IdWorker.java</p> * <p>描述:分布式自增长ID</p> * <pre> * Twitter的 Snowflake JAV