本文主要是介绍雪花算法(Snowflake)介绍和Java实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、雪花算法介绍
(1) 雪花算法(SnowFlake)是分布式微服务下生成全局唯一ID,并且可以做到去中心化的常用算法,最早是Twitter公司在其内部的分布式环境下生成ID的方式。 雪花算法的名字可以这么理解,世界上没有两片完全相同的雪花,而雪花算法希望自己生成的ID是独一无二的。
去中心化可以理解成不需要依赖某一个中间件,比如可以用Redis来生成全局唯一的ID,但Redis此时就属于中心,同时还会需要依赖网络。 而雪花算法通过10位bit的本地标识实现去中心化。
(2) 雪花算法生成的ID特点
- 64bit位的正整数,即java中的long类型;
- 整体结构是有序的。
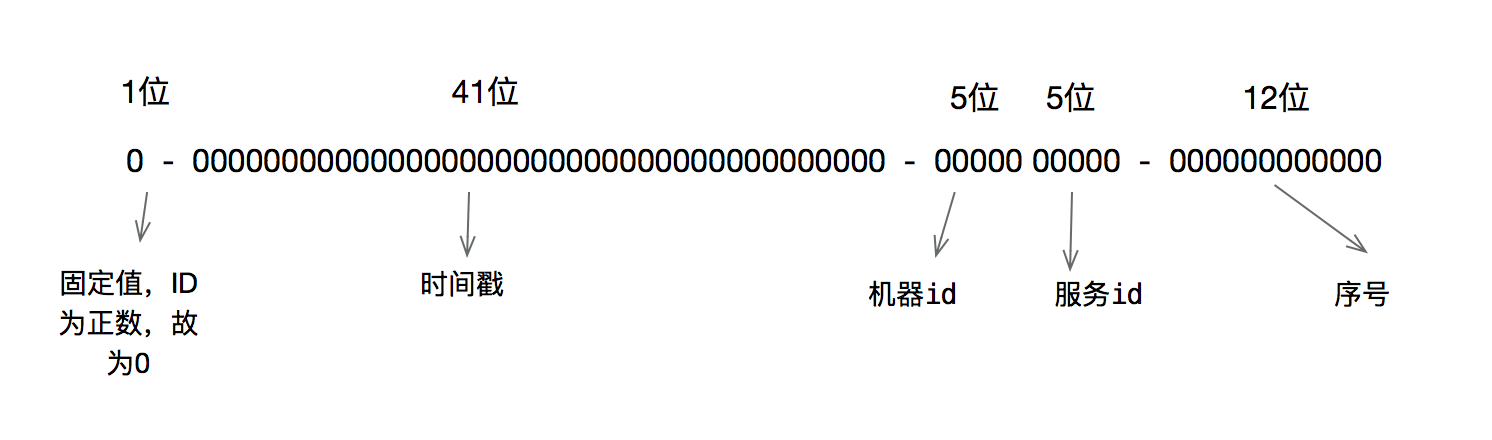
(3) 64个bit位
- 最高位:0, 代表是 一个正整数;
- 41位:存储毫秒级的时间戳,在java中可以使用 System.currentMillons()获取,并且保证了自增特性;
- 10位:存储机房/机器/操作系统/容器/服务的ID;
- 12位:存储一个自增的序列。
说明:雪花算法内部的bit位数可以进行微调,比如5位机器id和5位服务id组合成10位。
2、Java方式实现雪花算法
(1)整体实现逻辑
64个bit位的long类型的值
第一位:占 1 个bit位,就是0
第二位:占 41 个bit位, 代表时间戳
第三位:占 5 个bit位, 代表机器id (这里将 10 bit 位 做了调整)
第四位:占 5 个bit位,服务id
第五位:占 12 个bit位, 自增序列
(2) 具备知识
- java实现bit位移运算以及异或运算,用于计算固定bit位代表的最大数值,以及将bit位移动到固定位置。
例如:java中41个bit位的最大数值
long max41Bit = (1L << 41) - 1; // 41 bit 位 可以表示的最大数值 2的42次方减1, 即 1往左移41位减1
(3) 核心逻辑
- 先是定义5个位数对应的变量, 以及对应的偏移量,因为需要通过偏移后变量的bit位才能到达固定的位置;
- 再是计算自定义的机器id和服务id的最大值,用于严谨校验;
- 分别拿到对应的值,然后做位移运算;
- 做位移运算时的时间戳不从1900-01-01开始算起,因为41bit位的时间戳大概可用70年。
逻辑难点:在同一毫秒生成多个ID时,当前时间戳 与 自增序列的关系
- 拿到当前系统的毫秒值,记录生成上一个ID的毫秒值;
- 如果是同一毫秒生成ID,则自增序列递增(递增时要注意不能超出递增序列允许的最大值,超出需要等待下一毫秒);不同毫秒自增序列还原为初始值;
- 对于时针回拨问题,需要注意将当前的时间戳与生成的上一个ID的时间戳进行比较。
(4) Java代码具体实现
import org.springframework.beans.factory.annotation.Value;
import javax.annotation.PostConstruct;/*** 雪花算法生成全局唯一的ID* 64个bit位的long类型的值* 第一位:占 1 个bit位,就是0* 第二位:占 41 个bit位, 代表时间戳* 第三位:占 5 个bit位, 代表机器id (这里将 10 bit 位 做了调整)* 第四位:占 5 个bit位,服务id* 第五位:占 12 个bit位, 自增序列*/
public class SnowFlakeUtil {/*** 41 个bit位存储时间戳, 从0开始计算, 最多可以存储 69.7年。* 如果从默认使用, 从1970年到现在,最多可以用到2040年。* 按照从 2023-12-28号开始计算,存储41个bit位, 最多可以使用到2093年*/private long timeStart = 1703692800000L;/*** 机器id, 通过yml配置的方式声明*/@Value("${snowflake.machineId:0}")private long machineId = 0;/*** 服务id, 通过yml配置的方式声明*/@Value("${snowflake.serviceId:0}")private long serviceId = 0;/*** 自增序列*/private long sequence;// 需要做机器id和服务id的兼容性校验, 不能超过了5位的最大值/*** 机器id占用的bit位数*/private long machineIdBits = 5L;/*** 服务id占用的bit位数*/private long serviceIdBits = 5L;/*** 序列占用的bit位数*/private long sequenceBits = 12L;/*** 计算出机器id的最大值 -1 往左移 machineIdBits 位, 再做亦或运算*/private long maxMachineId = -1 ^ (-1 << machineIdBits); // -1 往左移 machineIdBits 位, 再做亦或运算// 11111111 11111111 11111111 11111111 11111111// 11111111 11111111 11111111 11111111 11100000// 00000000 00000000 00000000 00000000 00011111/*** 计算出服务id的最大值*/private long maxServiceId = -1 ^ (-1 << serviceIdBits);/*** 校验 机器id 和 服务id 是否超过最大范围值*/@PostConstructpublic void init() {if (machineId > maxMachineId || serviceId > maxServiceId) {System.out.println("机器id或服务id超过最大范围值");}}/*** 服务id需要位移的位数, 即从右侧开始, 将数字左移 sequenceBits 到固定的位置*/private long serviceIdShift = sequenceBits;/*** 机器id需要位移的位数, 即从右侧开始, 将数字左移 sequenceBits + serviceIdBits 到固定的位置*/private long machineIdShift = sequenceBits + serviceIdBits;/*** 时间戳需要位移的位数, 即从右侧开始, 将数字左移 sequenceBits + serviceIdBits + machineIdBits 到固定的位置*/private long timestampShift = sequenceBits + serviceIdBits + machineIdBits;/*** 序列的最大值 -1 往左移 sequenceBits 位, 再做亦或运算*/private long maxSequenceId = -1 ^ (-1 << sequenceBits);/*** 记录最近一次获取id的时间*/private long lastTimestamp = -1;/*** 拿到当前系统时间的毫秒值** @return*/private long timeGen() {return System.currentTimeMillis();}/*** 生成全局唯一id* 因为有很多服务调用这个方法, 所以需要加sychronized锁*/public synchronized long nextId() {//1. 拿到当前系统时间的毫秒值long timestamp = timeGen();// 避免时间回拨造成出现重复的idif (timestamp < lastTimestamp) {// 说明出现了时间回拨System.out.println("当前服务出现时间回拨");}//2. 41个bit的时间知道了存什么了, 但是序列也需要计算一下。 如果是同一毫秒,序列就需要 还原 或者 ++// 判读当前生成的id的时间 和 上一次生成的时间if (timestamp == lastTimestamp) {// 同一毫秒值生成idsequence = (sequence + 1) & maxSequenceId; // 加1最大值进行与运算, 结果是如果超过了maxSequenceId则为0, 小于则不变if (sequence == 0) {// 进到这个if,说明已经超出了sequence序列的最大取值范围// 需要等到下一个毫秒值再回来生成具体的值timestamp = timeGen();// 写 <= 而不 写 == 是为了避免出现时间回拨的问题while (timestamp <= lastTimestamp) {// 时间还没动timestamp = timeGen();}}} else {// 另一个时间点生成idsequence = 0;}//3. 重新给 lastTimestamp 赋值lastTimestamp = timestamp;//4. 计算id,将几位值拼接起来, 41bit位的时间, 5位的机器, 5位的服务, 12位的序列return ((timestamp - timeStart) << timestampShift) | // 相减的差值 往左移 timestampShift(machineId << machineIdShift) | // machineId 往左移 machineIdShift(serviceId << serviceIdShift) | // serviceId 往左移 serviceIdShiftsequence &Long.MAX_VALUE;}
}这篇关于雪花算法(Snowflake)介绍和Java实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




