sklearn专题

【学习笔记】 陈强-机器学习-Python-Ch15 人工神经网络(1)sklearn
系列文章目录 监督学习:参数方法 【学习笔记】 陈强-机器学习-Python-Ch4 线性回归 【学习笔记】 陈强-机器学习-Python-Ch5 逻辑回归 【课后题练习】 陈强-机器学习-Python-Ch5 逻辑回归(SAheart.csv) 【学习笔记】 陈强-机器学习-Python-Ch6 多项逻辑回归 【学习笔记 及 课后题练习】 陈强-机器学习-Python-Ch7 判别分析 【学

【机器学习 sklearn】模型正则化L1-Lasso,L2-Ridge
#coding:utf-8from __future__ import divisionimport sysreload(sys)sys.setdefaultencoding('utf-8')import timestart_time = time.time()import pandas as pd# 输入训练样本的特征以及目标值,分别存储在变量X_train与y_train之中。

【机器学习 sklearn】特征筛选feature_selection
特征筛选更加侧重于寻找那些对模型的性能提升较大的少量特征。 继续沿用Titannic数据集,这次试图通过特征刷选来寻找最佳的特征组合,并且达到提高预测准确性的目标。 #coding:utf-8from __future__ import divisionimport sysreload(sys)sys.setdefaultencoding('utf-8')import timest

结合sklearn说一下特征选择
特征选择(排序)对于数据科学家、机器学习从业者来说非常重要。好的特征选择能够提升模型的性能,更能帮助我们理解数据的特点、底层结构,这对进一步改善模型、算法都有着重要作用。 特征选择主要有两个功能: 减少特征数量、降维,使模型泛化能力更强,减少过拟合增强对特征和特征值之间的理解 拿到数据集,一个特征选择方法,往往很难同时完成这两个目的。通常情况下,我们经常不管三七二十一,选择一种自己最熟悉或者

5.sklearn-朴素贝叶斯算法、决策树、随机森林
文章目录 环境配置(必看)头文件引用1.朴素贝叶斯算法代码运行结果优缺点 2.决策树代码运行结果决策树可视化图片优缺点 3.随机森林代码RandomForestClassifier()运行结果总结 环境配置(必看) Anaconda-创建虚拟环境的手把手教程相关环境配置看此篇文章,本专栏深度学习相关的版本和配置,均按照此篇文章进行安装。 头文件引用 from sklear

4.sklearn-K近邻算法、模型选择与调优
文章目录 环境配置(必看)头文件引用1.sklearn转换器和估计器1.1 转换器 - 特征工程的父类1.2 估计器(sklearn机器学习算法的实现) 2.K-近邻算法2.1 简介:2.2 K-近邻算法API2.3 K-近邻算法代码2.4 运行结果2.5 K-近邻算法优缺点 3.模型选择与调优3.1 交叉验证(cross validation)3.2 网格搜索(Grid Search)3

复现反向传播BP算法:手动实现与Sklearn MLP对比分析【复现】
完整代码 import numpy as npimport matplotlib.pyplot as pltfrom sklearn.datasets import make_moonsfrom sklearn.model_selection import train_test_splitfrom sklearn.datasets import load_breast_cancerfr
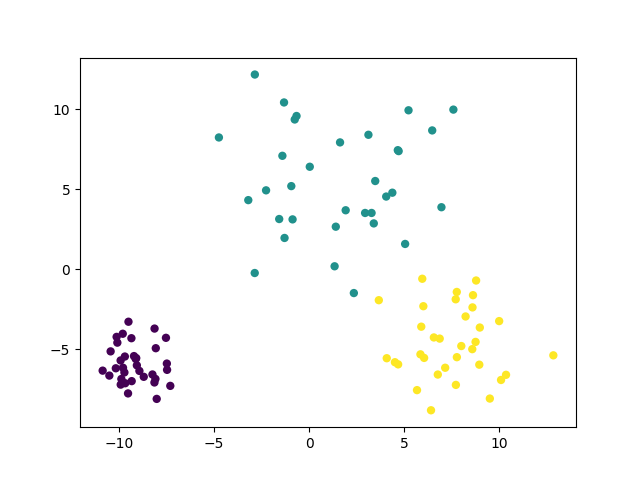
sklearn学习笔记(1)--make_blobs
make_blobs聚类数据生成器简介 scikit中的make_blobs方法常被用来生成聚类算法的测试数据,直观地说,make_blobs会根据用户指定的特征数量、中心点数量、范围等来生成几类数据,这些数据可用于测试聚类算法的效果。 make_blobs方法: sklearn.datasets.make_blobs(n_samples=100, n_features=2,cente
![sklearn光速入门实践[1]——实现一个简单的SVM分类器](https://i-blog.csdnimg.cn/blog_migrate/37b1cd9f70b70b7a88429c60af5e31b8.png)
sklearn光速入门实践[1]——实现一个简单的SVM分类器
python的sklearn库封装了许多常用的机器学习算法,而且入门简单,调用方便。下面我们用sklearn库和简单的几个点作为数据集,来实现一个简单的SVM分类器。 首先,准备好数据。我们把(2,0),(0,2),(0,0)这三个点当作类别1;(3,0),(0,3),(3,3)这三个点当作类别2,训练好SVM分类器之后,我们预测(-1,-1),(4,4)这两个点所属的类别。示意图如下: 1

sklearn中的线性回归
多元线性回归 指的 是一个样本 有多个特征的 线性回归问题。 w 被统称为 模型的 参数,其中 w0 被称为截距(intercept),w1~wn 被称为 回归系数(regression coefficient)。这个表达式和 y=az+b 是同样的性质。其中 y 是目标变量,也就是 标签。xi1~xin 是样本 i 上的特征 不同特征。如果考虑有 m 个样本

python库——sklearn的关键组件和参数设置
文章目录 模型构建线性回归逻辑回归决策树分类器随机森林支持向量机K-近邻 模型评估交叉验证性能指标 特征工程主成分分析标准化和归一化 scikit-learn,简称sklearn,是Python中一个广泛使用的机器学习库,它建立在NumPy、SciPy和Matplotlib这些科学计算库之上。sklearn提供了简单而有效的工具来进行数据挖掘和数据分析。我们将介绍sklea

【Sklearn驯化-环境配置】一文搞懂sklearn建模的最优环境搭建用法
【Sklearn驯化-环境配置】一文搞懂sklearn建模的最优环境搭建用法 本次修炼方法请往下查看 🌈 欢迎莅临我的个人主页 👈这里是我工作、学习、实践 IT领域、真诚分享 踩坑集合,智慧小天地! 🎇 相关内容文档获取 微信公众号 🎇 相关内容视频讲解 B站 🎓 博主简介:AI算法驯化师,混迹多个大厂搜索、推荐、广告、数据分析、数据挖掘岗位 个人申请专利40+,熟练掌握机
sklearn k最邻近算法
1、介绍 k最邻近算法可以说是一个非常经典而且原理十分容易理解的算法,可以应用于分类和聚合。 优点 : 1、简单,易于理解,易于实现,无需估计参数,无需训练; 2、适合对稀有事件进行分类; 3、特别适合于多分类问题(multi-modal,对象具有多个类别标签), kNN比SVM的表现要好; 缺点: 1、对规模超

机器学习 sklearn SVM
1、简介 SVM:支持向量机(Support Vector Machines),通俗来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。 目的:SVM 是一个面向数据的分类算法,它的目标是为确定一个分类超平面,从而将不同的数据分隔开 大佬简易通俗理解SVM,强烈推荐看 SVM具体实现和推导 SVM基
5 sklearn的数据集-datasets
sklearn的数据集-datasets sklearn的数据集-datasets sklearn 强大数据库文档介绍 1 经典数据2 构造数据 例子1房价例子2创建虚拟数据并可视化 1 sklearn 强大数据库 data sets,有很多有用的,可以用来学习算法模型的数据库。 eg: boston 房价, 糖尿病, 数字, Iris 花。 主要有两种:

python(numpy scipy matplotlib sklearn)安装
最近利用python做机器学习,安装中遇到一些问题 1、首先强烈建议不要使用.exe文件进行安装,不要随意在网上找安装包,其次是几个包的版本匹配问题 2、我的电脑是win7 x64 numpy scipy matplotlib sklearn 的.whl 文件都可以在下面的网址找到,下载时注意版本问题 http://www.lfd.uci.edu/~gohlke/pyth

sklearn中SVM的可视化
文章目录 第一部分:如何绘制三维散点图和分类平面第二部分:sklearn中的SVM参数介绍第三部分:源代码and数据 最近遇到一个简单的二分类任务,本来可用一维的线性分类器来解决,但是为了获得更好的泛化性能,我选取了三个特征,变成了一个三维空间的二分类任务。目的就是使两类样本之间的间隔再大一些,为了满足这种需求,自然而然的想到使用SVM作为分类器,并且该任务是线性可分,自然的选用L
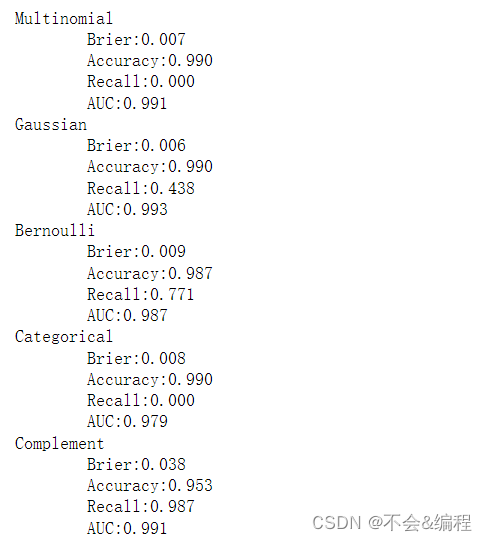
Sklearn之朴素贝叶斯应用
目录 sklearn中的贝叶斯分类器 前言 1 分类器介绍 2 高斯朴素贝叶斯GaussianNB 2.1 认识高斯朴素贝叶斯 2.2 高斯朴素贝叶斯建模案例 2.3 高斯朴素贝叶斯擅长的数据集 2.3.1 三种数据集介绍 2.3.2 构建三种数据 2.3.3 数据标准化 2.3.4 朴素贝叶斯处理数据 2.4 高斯朴素贝叶斯的拟合效果与运算速度 2.4.1 交叉验证
001-基于Sklearn的机器学习入门:Sklearn库基本功能和标准数据集
本节将介绍Sklearn库基本功能,以及其自带的几个标准数据集的调用方法。本节是学习后面内容的基础,如果您已经对本节内容相当熟悉,可跳过本节内容。 1.1 Sklearn库基本功能 的 1.2 Sklearn库标准数据集 Sklearn自带许多标准数据集,这些数据集从简单到复杂,可用于机器学习的各个领域。主要包括以下四类: Toy datasetsReal world dataset

sklearn 基础教程
scikit-learn(简称sklearn)是一个开源的机器学习库,它提供了简单和有效的数据分析和数据挖掘工具。sklearn是Python语言中最重要的机器学习库之一,广泛用于统计学习和数据分析。 以下是scikit-learn的基础教程,帮助您开始使用这个强大的工具。 安装 在开始之前,您需要确保已经安装了Python和pip。然后,您可以使用pip来安装scikit-learn: p

机器学习逻辑回归模型总结——从原理到sklearn实践
0x00 基本原理 逻辑回归算法,从名字上看似乎是个回归问题,但实际上逻辑回归是个典型的分类算法。 对于分类问题,一般都是一些离散变量,且y的取值如下: y∈{0,1,2,3,...,n} y \in \{0, 1, 2, 3, ..., n\},显然不能使用线性回归拟合。 以二元分类问题开始讨论,y的取值为“类别1,类别2”,为了表示清楚,这里使用0和1来表示二元分类中的两
掌握机器学习基础:Scikit-Learn(sklearn)入门指南
Scikit-Learn(sklearn)是Python中一个非常受欢迎的机器学习库,它提供了各种用于数据挖掘和数据分析的算法。以下是Scikit-Learn的入门指南,以帮助您掌握机器学习的基础知识。 1. 简介 定义:Scikit-Learn是一个基于Python的开源机器学习库,它建立在NumPy、SciPy、Pandas和Matplotlib等库之上。功能:它涵盖了几乎所有主流机器学习
sklearn(Scikit-learn)入门学习教程
sklearn(Scikit-learn)是一个功能强大的Python机器学习库,它提供了丰富的工具和方法,用于数据挖掘、数据分析和预测建模。以下是一个关于sklearn的清晰教程,涵盖了其主要特点和功能: 1. sklearn简介 定义:sklearn是Python中常用的机器学习库,它封装了多种机器学习算法,包括分类、回归、聚类、降维等。特点: 简单高效的数据挖掘和数据分析工具。允许用户在
Sklearn简介、安装教程、入门学习
当谈到sklearn(scikit-learn)教程时,以下是一个清晰、分点表示和归纳的概述,结合了参考文章中的相关信息: 1. Sklearn简介 定义:Scikit-learn(sklearn)是Python中用于机器学习的开源库,提供了各种机器学习算法的实现,包括分类、回归、聚类、降维等。特点: 简单高效的数据挖掘和数据分析工具。允许在复杂环境中重复使用。建立在NumPy、SciPy和M
sklearn、tensorflow、keras区别与联系--九五小庞
1.sklearn库 sklearn是一个功能强大的Python机器学习库。 sklearn库提供了多种常用的机器学习算法,包括回归、分类、聚类和降维等,适用于那些希望通过预制的算法快速实现原型设计和数据分析的开发者和研究人员。sklearn几乎涵盖了所有常见的机器学习模型和算法,其通过提供一致的界面和简洁的用法,使得机器学习的应用变得简单易行。 首先,sklearn库的主要优势在于其丰富性
sklearn工具包---分类效果评估(acc、recall、F1、ROC、回归、距离)
一、acc、recall、F1、混淆矩阵、分类综合报告 1、准确率 第一种方式:accuracy_score # 准确率import numpy as npfrom sklearn.metrics import accuracy_scorey_pred = [0, 2, 1, 3,9,9,8,5,8]y_true = [0, 1, 2, 3,2,6,3,5,9] #共9个数据,3个相