reward专题

扩展KMP --- HDU 3613 Best Reward
Best Reward Problem's Link: http://acm.hdu.edu.cn/showproblem.php?pid=3613 Mean: 给你一个字符串,每个字符都有一个权值(可能为负),你需要将这个字符串分成两个子串,使得这两个子串的价值之和最大。一个子串价值的计算方法:如果这个子串是回文串,那么价值就是这个子串所有字符权值之和;否则价值为0。

HDU 3613 Best Reward 正反两次扩展KMP
题目来源:HDU 3613 Best Reward 题意:每个字母对应一个权值 将给你的字符串分成两部分 如果一部分是回文 这部分的值就是每个字母的权值之和 求一种分法使得2部分的和最大 思路:考虑扩展KMP 输出a串 得到a的反串b 求出f[0]和f[1] 和 extend[0]和extend[1] 正反求2次 枚举位置i 分成2部分0到i-1 和i到n-1 因为分成的2部分必须组成原字符

Leetcode 3181. Maximum Total Reward Using Operations II
Leetcode 3181. Maximum Total Reward Using Operations II 1. 解题思路2. 代码实现 题目链接:3181. Maximum Total Reward Using Operations II 1. 解题思路 这一题的话思路上依然还是动态规划的思路,核心的迭代关系式如下: def dp(idx, pre_sum) :if nums[idx

Llama模型家族训练奖励模型Reward Model技术及代码实战(二)从用户反馈构建比较数据集
LlaMA 3 系列博客 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (一) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (二) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (三) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (四) 基于 LlaMA 3

Offline RL : Beyond Reward: Offline Preference-guided Policy Optimization
ICML 2023 paper code preference based offline RL,基于HIM,不依靠额外学习奖励函数 Intro 本研究聚焦于离线偏好引导的强化学习(Offline Preference-based Reinforcement Learning, PbRL),这是传统强化学习(RL)的一个变体,它不需要在线交互或指定奖励函数。在这个框架下,代理(agent)被提
HDU3613 Best Reward - exkmp/Manacher
题目连接:http://acm.hdu.edu.cn/showproblem.php?pid=3613 题意:多组数据,给定每个字母的价值和一个串S,要把这个串S分成两个串T1、T2,若某串T是回文串那么就能获得该串上字母的价值,否则可获得的价值为0,求最大价值 题解:RT 用exkmp或者马拉车搞一搞就好了 心得什么的:撒比的我想着用exkmp搞,练习一下,结果..一搞就搞了半个世纪qwq
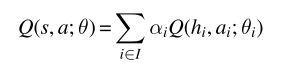
10MARL深度强化学习 Value Decomposition in Common-Reward Games
文章目录 前言1、价值分解的研究现状2、Individual-Global-Max Property3、Linear and Monotonic Value Decomposition3.1线性值分解3.2 单调值分解 前言 中心化价值函数能够缓解一些多智能体强化学习当中的问题,如非平稳性、局部可观测、信用分配与均衡选择等问题,然而存在很难直接学习价值函数等问题,特别是动作价值

【EAI 019】Eureka: Human-Level Reward Design via Coding LLM
论文标题:Eureka: Human-Level Reward Design via Coding Large Language Models 论文作者:Yecheng Jason Ma, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi Fan, Anima A

Sparse Reward的思考——Hierarchical RL
背景 现在就出现了另外一个场景,就是我们的目标是多个步骤的。可能在中间的某个步骤,很难获得最好的收益。举个例子,小孩子在学习和玩耍的过程看成一个强化的过程。比如,下一步如果选择玩耍,下一步可以得到1分,但是最终是-100分。对于学习步骤,下一步可能是-1分,但是最终是100分。但是我们的机器在选择适合,可能会选择玩耍,因为最终的reward是多步的,比较难以学习。在这种情况下,就需要用到spar

奖励Reward系统设计
介绍 一般来说系统前期,发放奖励,就简单的发放道具就可以,基本上是,遇到一个配置一个,不同的系统可能配置的方法不一样,每次活动更是加不同的配置。 经历里这些不同的需求,我们需要设计一个系统它可以统一的管理这些,满足各种奖励需求。 配置 Reward RewardIdGroupIds奖励id组列表 可以在导表中将Item表中的数据直接放入这里,可以很方便的配置道具,这里每个组必定产
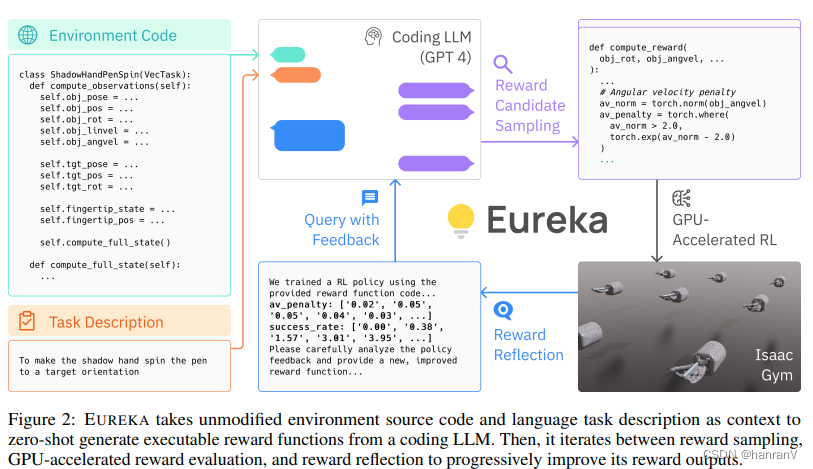
EUREKA: HUMAN-LEVEL REWARD DESIGN VIACODING LARGE LANGUAGE MODELS
目录 一、论文速读 1.1 摘要 1.2 论文概要总结 相关工作 主要贡献 论文主要方法 实验数据 未来研究方向 二、论文精度 2.1 论文试图解决什么问题? 2.2 论文中提到的解决方案之关键是什么? 2.3 用于定量评估的数据集是什么?代码有没有开源? 2.4 这篇论文到底有什么贡献? 2.5 下一步呢?有什么工作可以继续深入? 一、论文速读 paper
HDOJ 2647 Reward 【逆拓扑排序+分层】
题意:每个人的基础工资是888, 由于一部分人要显示自己水平比较高,要求发的工资要比其他人中的一个人多,问你能不能满足他们的要求,如果能的话最终一共要发多少钱,如果不能就输出-1. 策略:拓扑排序。 这道题有些难点:一:数据大,建二维数组肯定不行,要换其他的数据结构(vector, 或者是链式前向星(本题代码用的是链式前向星)); 二:要逆拓扑排序(就是将++in[b]换成++in[a]),

GPT实战系列-GPT训练的Pretraining,SFT,Reward Modeling,RLHF
GPT实战系列-GPT训练的Pretraining,SFT,Reward Modeling,RLHF 文章目录 GPT实战系列-GPT训练的Pretraining,SFT,Reward Modeling,RLHFPretraining 预训练阶段Supervised FineTuning (SFT)监督微调阶段Reward Modeling 奖励评价建模Reinforment Learni
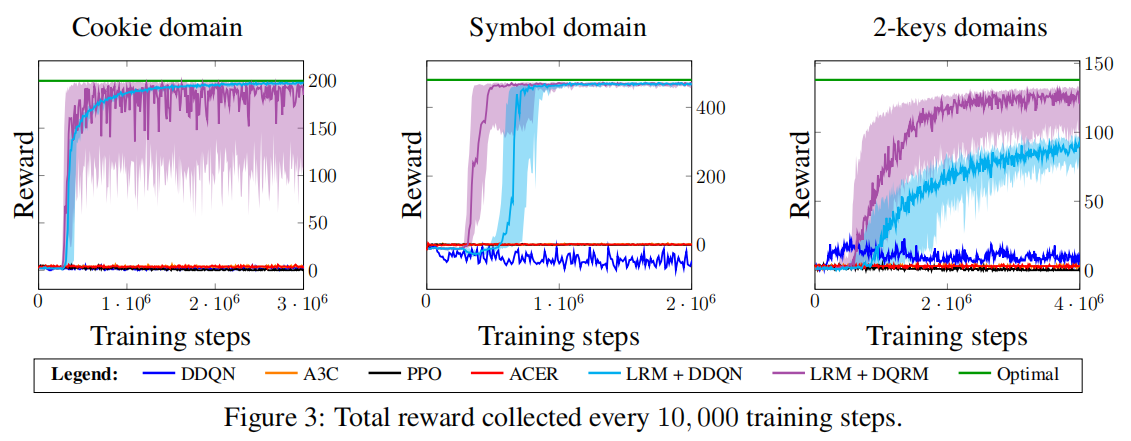
论文笔记 Learning Reward Machines for Partially Observable Reinforcement Learning
摘要 Reward Machines 提供了一种对奖励函数进行结构化的、基于自动机的表示,让agent得以将一个RL问题分解成结构化的子问题,这样一来可以通过离线学习(off-policy)高效解决。 本文展现了RM可以通过经验学习到(而不是由用户来具体说明),以及问题分解可以用来有效解决部分可观察的(partially observable)RL问题。作者将学习RM的任务作为一个离散的优化问
![[摘要生成]Knowledge Graph-Augmented Abstractive Summarization with Semantic-Driven Cloze Reward](https://img-blog.csdnimg.cn/202101131006148.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1NBUkFDSF9XT05H,size_16,color_FFFFFF,t_70)
[摘要生成]Knowledge Graph-Augmented Abstractive Summarization with Semantic-Driven Cloze Reward
arxiv 2020 论文链接:https://arxiv.org/pdf/2005.01159.pdf github链接:https://github.com/luyang-huang96/GraphAugmentedSum 看具体内容,直接跳转链接。本文只从个人角度出发看本篇paper。 疑惑 数据集: NYT:training, validation, and test sets 58

Expressing Arbitrary Reward Functions as Potential-Based Advice将任意奖励函数表示为基于势能的建议
摘要 ------有效地吸纳外部建议是强化学习中的一个重要问题,尤其是在它进入现实世界的时候。基于势能的奖励塑形是在保证策略不变性的前提下,为agent提供特定形式的额外奖励的一种方式。本文提出了一种新的方法,通过隐含地将任意一个具有相同保证的奖励函数转化为动态建议势能的特定形式,使其保持为一个同时学习的辅助值函数。我们证明了这种方式提供的建议捕获了期望中的输入奖励函数,并通过实证证明了其有效性
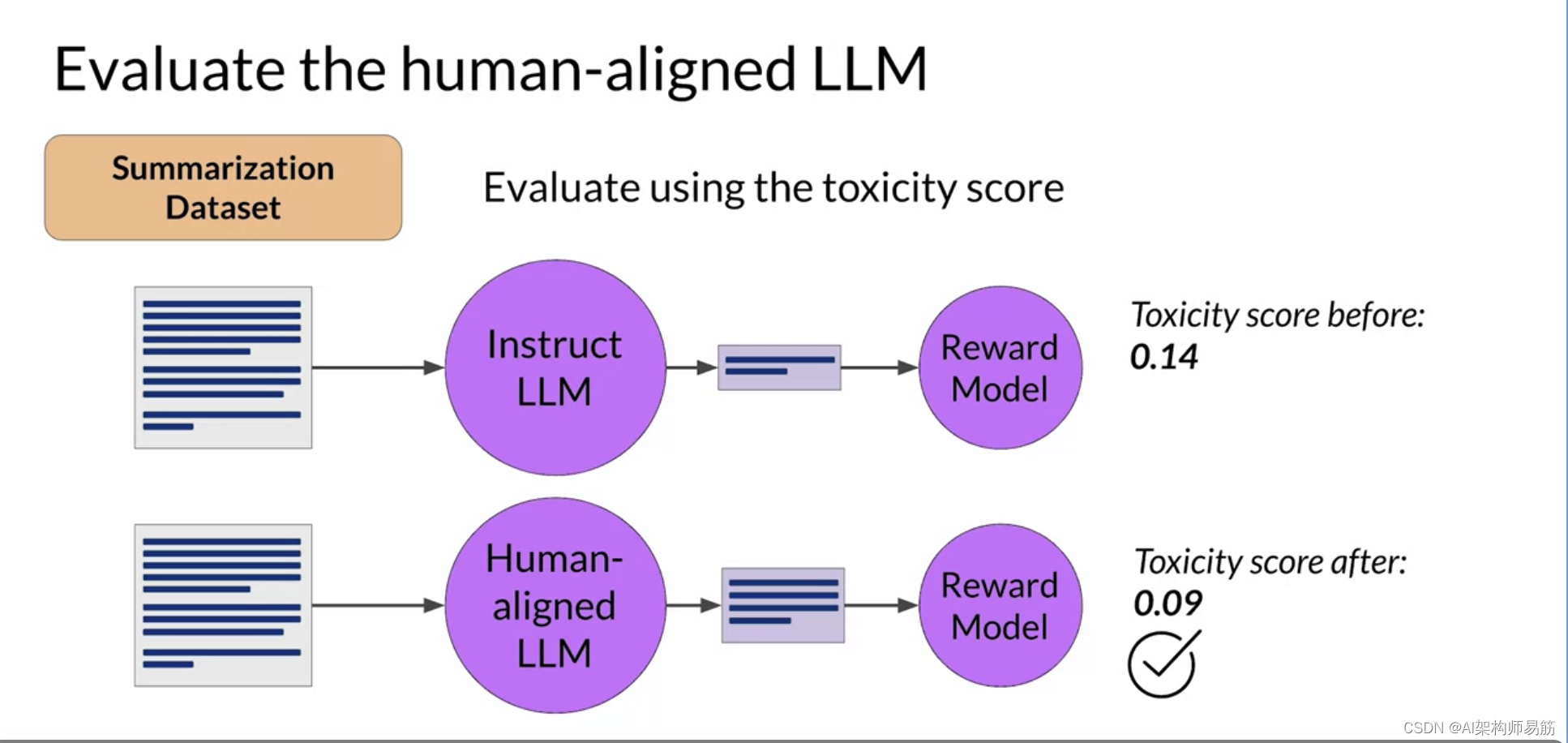
LLMs 奖励剥削 RLHF: Reward hacking
让我们回顾一下你到目前为止所学到的内容。RLHF是一个微调过程,用于使LLM与人类偏好保持一致。在这个过程中,您利用奖励模型来评估LLM对提示数据集的完成情况,根据人类偏好指标(如有帮助或无帮助)进行评估。 接下来,您使用强化学习算法,即PPO,在基于当前版本的LLM生成的完成情况上,根据奖励对LLM的权重进行更新。您将在多个迭代中使用许多不同的提示和模型权重的更新来执行此周期,直到获得所期望
LLMs 奖励剥削 RLHF: Reward hacking
让我们回顾一下你到目前为止所学到的内容。RLHF是一个微调过程,用于使LLM与人类偏好保持一致。在这个过程中,您利用奖励模型来评估LLM对提示数据集的完成情况,根据人类偏好指标(如有帮助或无帮助)进行评估。 接下来,您使用强化学习算法,即PPO,在基于当前版本的LLM生成的完成情况上,根据奖励对LLM的权重进行更新。您将在多个迭代中使用许多不同的提示和模型权重的更新来执行此周期,直到获得所期望