preprocessing专题

没有名为 keras.preprocessing 的模块
估计是因为版本原因 我安装的是 3.3.3版本 >>> import keras>>> print(keras.__version__)3.3.3 keras.preprocessing.image 只需要将 keras.preprocessing.image 改为 from keras_preprocessing.image 即可

Datacamp 笔记代码 Supervised Learning with scikit-learn 第四章 Preprocessing and pipelines
更多原始数据文档和JupyterNotebook Github: https://github.com/JinnyR/Datacamp_DataScienceTrack_Python Datacamp track: Data Scientist with Python - Course 21 (4) Exercise Exploring categorical features The G

tf.nn.conv2,cross_entropy,loss,sklearn.preprocessing,next_batch,truncated_normal,seed,shuffle,argmax
tf.truncated_normal https://www.tensorflow.org/api_docs/python/tf/random/truncated_normal truncated_normal( shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None ) seed: 随机种子,若 seed 赋值

CONN | Preprocessing fMRI data
碎碎念:跟我读,CONN的理念是——“一条路走到黑”~~~ CONN是一款基于Matlab的fMRI处理工具,最早是为任务态数据处而开发的,不过分析静息态也很方便啦~~ 目录 准备工作 预处理-SETUP环节 BASIC Structural Functional Preprocessing 图像质量检查 准备工作 1. 下载CONN包,将包所在路径添加到Matl

tf.contrib.keras.preprocessing.sequence.pad_sequences 将标量数据 转换成numpy ndarray
keras.preprocessing.sequence.pad_sequences(sequences, maxlen=None, dtype=’int32’, padding=’pre’, truncating=’pre’, value=0.) 函数说明: 将长为nb_samples的序列(标量序列)转化为形如(nb_samples,nb_timesteps)2D numpy array。
![[译]sklearn.preprocessing.StandardScaler](/front/images/it_default.jpg)
[译]sklearn.preprocessing.StandardScaler
sklearn.preprocessing.StandardScaler class sklearn.preprocessing.StandardScaler(copy=True, with_mean=True, with_std=True) 通过去除均值和缩放为单位变量实现特征标准化。 计算方式为 z = x − μ s z=\frac{x-\mu}{s} z=sx−μ μ \m

【Preprocessing数据预处理】之Pipeline
在机器学习中,管道(Pipeline)是一种工具,用于将数据预处理、特征选择、模型构建等一系列步骤封装成为一个整体流程。这样做的好处是可以简化代码,避免数据泄露,并使模型的训练和预测过程更加高效和可重复。在 `scikit-learn` 库中,`Pipeline` 类是实现这一目的的关键工具。 以下是如何使用 `scikit-learn` 的 `Pipeline` 来创建一个包含数据预处理(如标
【AI学习笔记】AttributeError: module ‘keras.preprocessing.sequence‘ has no attribute ‘pad_sequences‘
报错: AttributeError: module ‘keras.preprocessing.sequence’ has no attribute ‘pad_sequences’ 看了许多博客,说是版本问题,我的版本都是2.11.0 解决方法 有的人说: 将 from keras.preprocessing import sequence 改为 from keras_preproces
【Preprocessing数据预处理】之Information Leakage
在机器学习中,当使用来自训练数据集之外的信息来创建模型时,就会发生信息泄露。这可能导致在训练期间过于乐观的性能估计,并且可能导致模型在未见数据上表现不佳,因为它可能无法从训练数据泛化到现实世界。 信息泄露的示例 1. 使用测试集进行训练:信息泄露最明显的形式是使用测试集或其任何部分进行训练。测试集应该是完全未见过的数据,以准确衡量模型的性能。 from sklearn.datasets im

数据仓库数据挖掘——Data Preprocessing
为什么要进行数据预处理? Data in the real world is dirty:incomplete、noisy、inconsistent(不一致的) No quality data, no quality mining results! 一个广为接受的多维视角: 精度、完整性、一致性、及时性、可信性、增加值、解
sklearn.preprocessing 特征编码汇总
文章目录 常见特征种类one-hot编码特征哈希(`Feature hashing`)基于统计的类别编码对循环特征的编码目标编码(Target encoding)K折目标编码(K-Fold Target encoding) 用于数据分析的特征可能有多种形式,需要将其合理转化成模型能够处理的形式,特别是对非数值的特征,特征编码就是在做这样的工作。 常见特征种类 二值数据:只
sklearn.preprocessing 标准化、归一化、正则化
文章目录 数据标准化的原因作用归一化最大最小归一化针对规模化有异常的数据 标准化线性比例标准化法log函数标准化法 正则化Normalization标准化的意义 数据标准化的原因 某些算法要求样本具有零均值和单位方差; 需要消除样本不同属性具有不同量级时的影响: ① 数量级的差异将导致量级较大的属性占据主导地位; ② 数量级的差异将导致迭代收敛速度减慢; ③ 依赖
sklearn.preprocessing中的标准化StandardScaler与scale的区别
StandardScaler与scale 1、标准化概述2、两种标准化的区别 1、标准化概述 标准化主要用于对样本数据在不同特征维度进行伸缩变换,目的是使得不同度量之间的特征具有可比性,同时不改变原始数据的分布 一些机器学习算法对输入数据的规模和量纲非常敏感,如果输入数据的特征之间存在数量级差异,可能会影响算法的准确性和性能 标准化处理的好处是我们在进行特征提取
[Sklearn应用] Preprocessing data (三)编码分类特征 Encoding categorical features
此内容在sklearn官网地址: http://scikit-learn.org/stable/modules/preprocessing.html# sklearn版本:0.18.2 one-hot-encode 有时特征内容并不是数值,而是字符串类型。如果直接将字符串转成一个对应的数值,造成原本的特征具有大小关系。这是需要使用 one-hot-encode编码格式。 两种转化方
tf.keras.preprocessing.sequence.pad_sequences
这个玩意是啥子?? pad_sequences(sequences, maxlen=None, dtype='int32', padding='pre', truncating='pre', value=0.0)Pads sequences to the same length. 这个不仅有补零的作用,还有截断的功能。 padding: String, 'pre' or 'p

from sklearn.preprocessing import LabelEncoder的详细用法
sklearn.preprocessing 0. 基本解释1. 用法说明2. python例子说明 0. 基本解释 LabelEncoder 是 sklearn.preprocessing 模块中的一个工具,用于将分类特征的标签转换为整数。这在许多机器学习算法中是必要的,因为它们通常不能处理类别数据。 1. 用法说明 # 初始化:le = LabelEncoder()
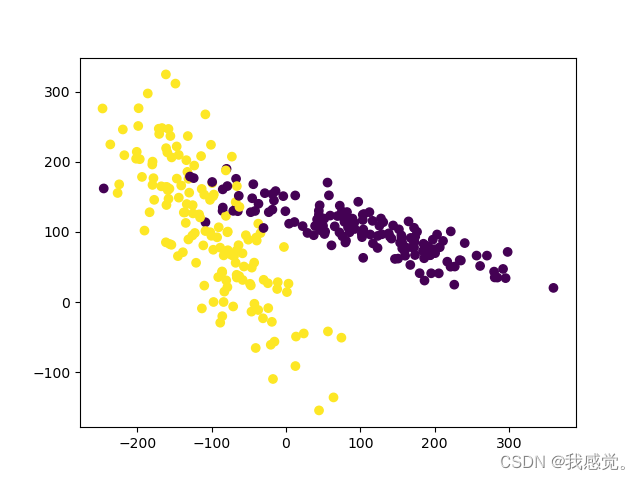
【sklearn练习】preprocessing的使用
介绍 scikit-learn 中的 preprocessing 模块提供了多种数据预处理工具,用于准备和转换数据以供机器学习模型使用。这些工具可以帮助您处理数据中的缺失值、标准化特征、编码分类变量、降维等。以下是一些常见的 preprocessing 模块中的功能和用法示例: 标准化特征(Feature Scaling): 使用 StandardScaler 类可以对特征进行标准化,使其具
详解Keras:keras.preprocessing.image
keras.preprocessing.image Keras 库中的一个模块,用于处理和增强图像数据,它提供了一些实用的函数,如图像的加载、预处理、增强等。 常用函数 1、load_img 用于加载图像文件,并返回一个 NumPy 数组表示该图像 示例 from keras.preprocessing.image import load_img,load_img,array_
sklearn.preprocessing.StandardScaler
http://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.StandardScaler.html#sklearn.preprocessing.StandardScaler sklearn中的StandardScaler,是对每个特征(列向量)独立地进行居中和缩放。然后存储平均值和标准偏差以使用变换方法在以后的数据
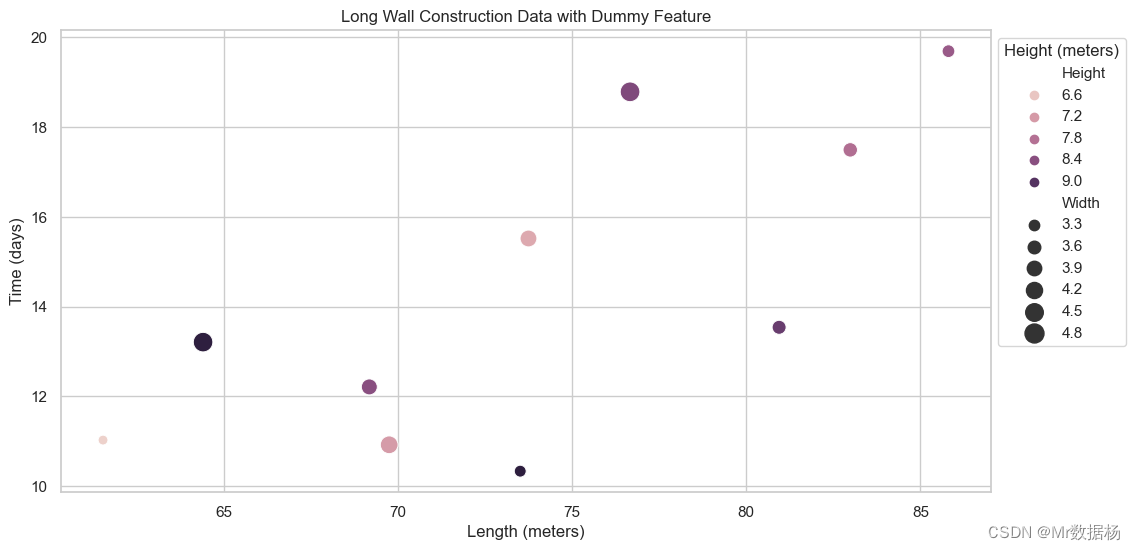
【Python机器学习】零基础掌握Preprocessing and Normalization数据预处理方法
如何优化的数据? 在处理数据之前,为什么总是听说需要进行预处理和规范化?在这个信息爆炸的时代,数据无疑是宝贵的财富,但原始数据往往包含噪声、缺失值、格式不一致等问题。预处理就是在数据分析之前,通过一系列技术手段清洗和整理数据,以增强数据的质量和分析的准确性。规范化(Normalization)则是一种调整数值数据范围以便于比较的技术。 预处理和规范化在现实生活中的应用几乎无处不在。假设一家电商

keras.preprocessing.text.Tokenizer
keras.preprocessing.text.Tokenizer Tokenizer 是一种用于自然语言处理的类,其具体的功能是把一个词(中文单个字或者词组认为是一个词)转化为一个正整数,于是一个文本就变成了一个序列。这里改类方具体如图所示: 具体的代码用例如下所示: from keras.preprocessing import text#facts, accu_label, art

真的明白sklearn.preprocessing中的scale和StandardScaler两种标准化方式的区别吗?
写在前面 之前,写过一篇文章,叫做真的明白数据归一化(MinMaxScaler)和数据标准化(StandardScaler)吗?。这里面搞清楚了归一化和标准化的区别,但是在实用中发现,在数据标准化中,又存在两种方式可以实现,在这里总结一下两者的区别吧。 标准化是怎么回事来? 什么是标准化 在机器学习中,我们可能要处理不同种类的资料,例如,音讯和图片上的像素值,这些资料可能是高维度的,资料标

预处理(Preprocessing)、编译(Compilation)、汇编(Assembly)和链接(Linking)| 个人笔记
预处理(Preprocessing)、编译(Compilation)、汇编(Assembly)和链接(Linking) hello.c 相关代码 #include <stdio.h>int main(){printf("Hello World\n");return 0;} 运行效果如下 Windows和Linux下的文件格式