pickle专题

python pickle 模块用于保存python内存数据(包括实例对象、字典、列表等所有python中的数据)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言基本用法 前言 Python 的 pickle 模块用于序列化和反序列化 Python 对象。这意味着你可以将 Python 对象(如列表、字典、类实例等)转换为字节流(序列化),并将其保存到文件中或在网络上传输,然后在需要的时候将其恢复为原始 Python 对象(反序列化)。 常见用途

Python——文件的基本操作、上下文管理器、pickle序列化和路径处理
文件的基本操作 Python中打开文件并进行基本操作是一个常见的任务,这包括读取文件内容、写入文件内容、追加内容到文件末尾以及修改文件内容(虽然修改通常涉及读取、修改内容然后重新写入)。以下是这些基本操作的一些基本示例: 打开文件 在Python中,使用内置的open()函数来打开文件。这个函数返回一个文件对象,你可以对这个对象进行读取、写入等操作。open()函数的基本语法是: file
Python序列化与反序列化:pickle库使用详解
pickle是Python中一个用于对象序列化与反序列化的模块。它可以将Python对象转换成字节流,这样这些对象就可以容易地存储到文件中,或者通过网络传输。同样地,pickle也可以将这些字节流重新转换成原来的Python对象。 pickle库的主要功能 将Python对象序列化成字节流。从字节流中反序列化出Python对象。 常用pickle函数及其参数 pickle.dump(obj
mac系统Python Pickle报错:OSError: [Errno 22] Invalid argument
问题描述 在Python代码中使用Pickle模块dump一个对象,报错: >>> with open(path, 'wb') as f:>>> pickle.dump(self, f)Traceback (most recent call last):File "<stdin>", line 1, in <module>OSError: [Errno 22] Invalid argu

Python pickle反序列化
基础知识 Pickle Pickle在Python中是一个用于序列化(将对象转换为字节流)和反序列化(将字节流转换回对象)的标准库模块。它主要用于将Python对象保存到文件或通过网络进行传输,使得数据可以跨会话和不同的Python程序共享。 python序列化和php序列化都是将对象序列化为字符串来方便存储,只是python的序列化没有php序列化那么多的方法之间的调用触发,pyth

Python序列化与反序列化——json和pickle
简介 序列化:将Python里的基本类型如字典、列表、数组等序列化为字符串 反序列化:将字符串反序列化为Python里的基本类型如字典、列表等 用于序列化的两个模块 json,用于字符串 和 python数据类型间进行转换 pickle,用于python特有的类型 和 python的数据类型间进行转换 Json模块提供了四个功能:dumps、dump、loads、load pickl
2.4.1 Python存储之pickle
pickle是标准库中的一个模块,还有跟它完全一样的叫作 cpickle,两者的区别就是后者更快,所以,在操作中,不管是用import pickle,还是用import cpickle as pickle,在功能上都是一样的。 >>> import pickle >>> a = [1,2,3,4,5] >>> f = open("D://test.txt","wb")
python pickle模块 序列化
Python内置的pickle模块能够将Python对象序列成字节流,也可以把字节流反序列成对象。 import pickleclass Student:def __init__(self, name, age):self.name = nameself.age = agedef say(self):print("I am", self.name)>>> t = Student('Tom',
9.7Python文件操作(7):使用pickle进行二进制IO
@概述 通常的文件读写要么是读入/写出字符,要么是读入/写出字节;而二进制IO是指直接是读入/写出Python数据类型的值;二进制IO可以给小规模的数据读写带来极大的便利;其底层原理,仍是某种形式的对象到字节的“编码”,以及字节到对象的“解码”;对文件进行二进制IO时,文件的打开方模式必须是字节读写模式;我们习惯上将存储二进制IO数据的文件以.dat后缀命名;pickle是系统标准库所提供的二进
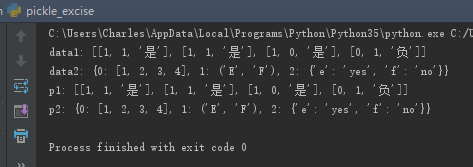
pickle序列化学习笔记
在机器学习中,我们常常需要把训练好的模型存储起来,这样在进行决策时直接将模型读出,而不需要重新训练模型,这样就大大节约了时间。Python提供的pickle模块就很好地解决了这个问题,它可以序列化对象并保存到磁盘中,并在需要的时候读取出来,任何对象都可以执行序列化操作。 pickle模块实现用于序列化和反序列化Python对象结构的二进制协议。 “Pickling”是将Python对象层次结构转
python3序列化模块之pickle
官方文档 简介 pickle 是 Python 中用于对象序列化和反序列化的标准库模块。它可以将 Python 对象转换为字节流,并将其保存到文件或通过网络传输,在需要时再将其恢复为原来的 Python 对象。 模块 pickle 实现了对一个 Python 对象结构的二进制序列化和反序列化。 “pickling” 是将 Python 对象及其所拥有的层次结构转化为一个字节流的过程,而 “u
python 中 pickle 模块学习笔记
概要和json 模块的比较常用api说明具体应用举例总结参考文档 pickle模块 一. 概要 用这个模块 可以创建Python对象的可移植序列化表示。 Create portable serialized representations of Python objects. 二.pickle 和json 模块对比 json 模块实现序列化方式 一般是 unicode text ,而且序列化后,
python 3以上版本使用pickle.load读取文件报UnicodeDecodeError: 'ascii' codec can't decode byte 0x8d in position 1
源码中 resource_val = pickle.load(opened_resource) 改为 resource_val = pickle.load(opened_resource,encoding='iso-8859-1')

python3 PicklingError: Can't pickle function lambda at...... attribute lookup lambda on __main
有皱纹的地方只表示微笑曾在那儿呆过。-------马克.吐温 在Unix/Linux下,multiprocessing模块封装了fork()调用,是我们不需要关注fork()的细节。由于windows没有fork调用,因此,multiprocessing需要“模拟”出fork的效果,父进程所有Python对象都必须通过pickle序列号再传到子进程中去。所以,如

ValueError: Object arrays cannot be loaded when allow_pickle=False 报错解决
今天手残升级了Numpy库的版本,从1.16升级到了1.17,在深度学习图像处理的任务里面表现是正常的,但是当我想运行一个Keras 学习Demo实例的时候就报错了,报错内容如下所示: ValueError: Object arrays cannot be loaded when allow_pickle=False 截图如下所示: 这个错误并没有

Python 输出输入(包含文件)以及格式美化的方式 以及 pickle
一、str() 和 repr() str() 将放入其中的参数转换为字符串 repr() 产生一个解释器易读的表达形式 >>> s1 = '泰坦尼克号'>>> str(s1)'泰坦尼克号'>>> repr(s1)"'泰坦尼克号'" 二、rjust(), ljust(), zfill() 分别为靠右,靠左,填充 >>> for x in range(1, 11):print(re
解释Python中的pickle模块及其用途
解释Python中的pickle模块及其用途 Python中的pickle模块是一个强大的序列化和反序列化工具,它允许开发者将Python对象转换为一种可以保存到磁盘或通过网络传输的格式,并在需要时将其重新转换回Python对象。这种转换过程被称为序列化和反序列化,而pickle模块为这些操作提供了简单易用的接口。 首先,我们需要了解序列化的概念。序列化是将数据结构或对象状态转换为可以存储或传
python pickle模块(数据持久存储)
存放:pickling 读取:unpickling 示例: >>> my_list = ['ddd',564,'TG',['1523','rww']] >>> pickle_file = open('my_list.pkl','wb') >>> pickle.dump(my_list,pickle_file) >>> pickle_file.close() >>> >>> >>> >>
【踩坑记录】TypeError: can‘t pickle SwigPyObject objects
笔者利用keras训练模型时,当程序运行到保存模型model.save('model.h5')的时候,报如下错误 TypeError: can't pickle SwigPyObject objects 根据错误提示,可以看到在对模型进行序列化保存的时候,出现了不支持序列化的对象,也就是SwigPyObject对象。 然而模型都可以跑通,但是为什么会在保存模型的时候报这样的错误呢?建模过程
Python标准库之pickle包,cpickle包
1、pickle包 对于上述过程,最常用的工具是Python中的pickle包。 (1)、将内存中的对象转换成为文本流: import pickle# define classclass Bird(object):have_feather = Trueway_of_reproduction = 'egg'summer = Bird() #
(20200720已解决)_pickle.UnpicklingError: A load persistent id instruction was encountered,
but no persistent_load function was specified. 问题描述 如题,提取pickle数据 解决方案 直接解释是因为生成pickle文件的过程中使用了persistent_load,但是读取过程中没有提供。 本例中的具体原因是,读取的pickle文件并非pickle格式,只是用pickle这个词表示这是一个规范压缩的数据文件,改用合适的read_*()
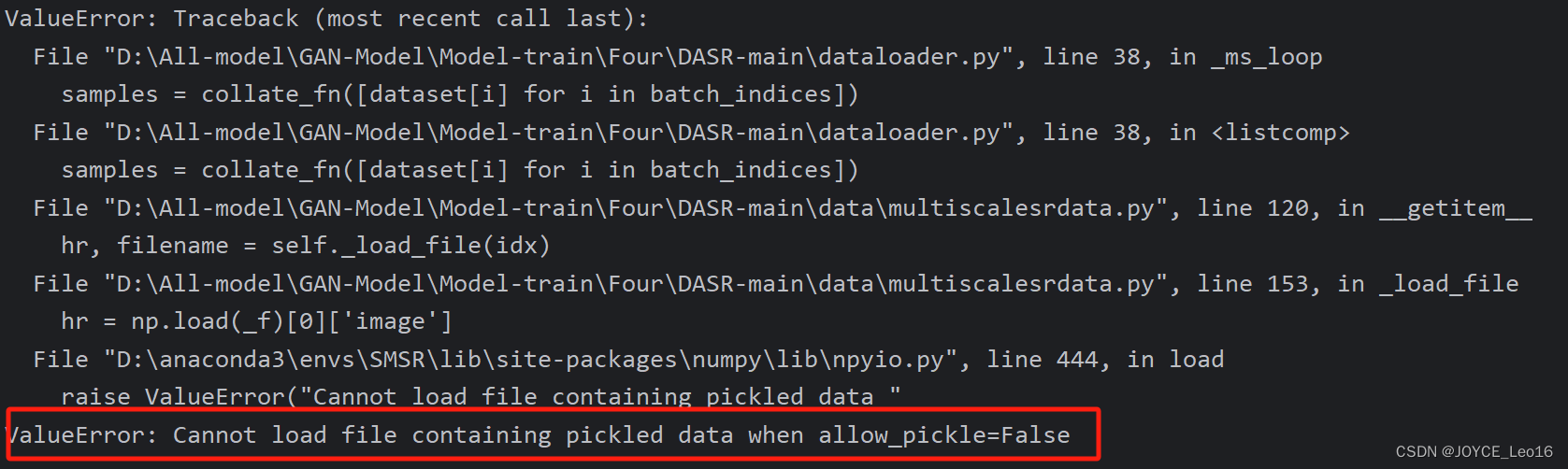
ValueError: Cannot load file containing pickled data when allow_pickle=False
问题描述 遇到报错:ValueError: Cannot load file containing pickled data when allow_pickle=False 解决方案 经过查阅有人说是与numpy的版本有关,但是还是不要轻易改变环境中的版本,不一定哪个地方就会报错。这里放个解决方案: 找到报错位置,修改代码: 将下面一行代码: hr = np.load(_f
将FER数据集使用Pickle处理-Python代码
之前写过一篇文章,是将FER2013数据集还原成灰度图像的Python代码,便于我们查看。 现在我想把它转换成pickle进行存储,这样便于读取和传输。 直接上代码就好了: def process_to_pickle(self):"""将csv文件加工成pickle文件,方便存储和读取:return: None"""# 创建文件夹if not os.path.exists(self.

pickle数据序列化和反序列化
pickle pickle 是 Python 中用于序列化和反序列化对象的标准模块。序列化是指将对象转换为字节流的过程,反序列化是指将字节流转换回对象的过程。pickle 提供了一种在 Python 对象和字节流之间相互转换的方式,可以用于将对象保存到文件或通过网络传输,并在需要时恢复原始对象。以下是 pickle 模块中常用的函数和方法: pickle.dump(obj, file):将对象

TypeError:can’t pickle dict_values objects.解决办法
出现问题如下图中所示: 问题出在这里:deepcopy那一行要改!加上list就可以了 。具体如下图所示:
72_Pandas.DataFrame保存并读取带pickle的系列(to_pickle、read_pickle)
72_Pandas.DataFrame保存并读取带pickle的系列(to_pickle、read_pickle) 要将 pandas.DataFrame、pandas.Series 对象保存为 pickle 文件,请使用 to_pickle() 方法,并使用 pd.read_pickle() 函数读取保存的 pickle 文件。 在此对以下内容进行说明。 什么是pickle将 pickle