本文主要是介绍pickle序列化学习笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在机器学习中,我们常常需要把训练好的模型存储起来,这样在进行决策时直接将模型读出,而不需要重新训练模型,这样就大大节约了时间。Python提供的pickle模块就很好地解决了这个问题,它可以序列化对象并保存到磁盘中,并在需要的时候读取出来,任何对象都可以执行序列化操作。
pickle模块实现用于序列化和反序列化Python对象结构的二进制协议。 “Pickling”是将Python对象层次结构转换为字节流的过程,“unpickling”是相反的操作,即字节流(来自二进制文件或类似字节的对象)被转换回对象层次结构。 picking(unpickle)可替代地被称为“序列”,“marshalling” [1]或“flattening”; 然而,为了避免混淆,这里使用的术语是“pickling”和“unpickling”。
注意:pickle模块对于错误或恶意构建的数据不安全,切勿取消从不可信或未经认证的来源收到的数据。
pickle与marshal比较
Python有一个更原始的序列化模块marshal,但通常pickle应该是序列化Python对象的首选方式。marshal 主要是为了支持Python的.pyc文件。
该pickle模块与以下marshal几个重要方面有所不同:
该pickle模块跟踪它已经序列化的对象,以便以后对同一对象的引用不会再次序列化。marshal 不这样做。
这对递归对象和对象共享都有影响。递归对象是包含对自己的引用的对象。这些不是由编组处理的,实际上,尝试编组递归对象会导致Python解释器崩溃。如果在被序列化的对象层次结构中的不同位置存在多个对同一对象的引用,则会发生对象共享。pickle 只存储一次这样的对象,并确保所有其他引用指向主副本。共享对象保持共享,这对于可变对象非常重要。
marshal不能用于序列化用户定义的类及其实例。pickle可以透明地保存和恢复类实例,但类定义必须是可导入的,并且与存储对象时位于同一模块中。
该marshal序列化格式是不能保证整个Python版本移植。因为它的主要工作是支持
.pyc文件,所以Python实施者保留在需要时以非向后兼容方式更改序列化格式的权利。该pickle序列化格式是保证不同的Python版本向后兼容。
pickle与比较JSON
pickle协议和JSON(JavaScript Object Notation)之间有着根本的区别 :
- JSON是一种文本序列化格式(它输出unicode文本,大部分的编码是UTF-8),而pickle是一种二进制序列化格式。
- JSON是人类可读的,而pickle不是;
- JSON可以在Python生态系统之外进行互操作和广泛使用,而pickle则是Python特有的;
- 默认情况下,JSON只能表示Python内置类型的一个子集,并且不包含自定义类; pickle可以代表大量的Python类型(其中许多是自动的,通过巧妙使用Python的内省设施;复杂的情况可以通过实现特定的对象API来解决)。
Pickle模块接口
要序列化对象层次结构,只需调用该dumps()函数。同样,为了反序列化数据流,您可以调用该loads()函数。但是,如果您想要更多地控制序列化和反序列化,则可以分别创建一个Pickler或一个Unpickler对象。
该pickle模块提供以下常量:
-
一个整数, 可用的最高协议版本。这个值可以作为一个被传递协议的价值函数
dump()和dumps()以及该Pickler构造函数。
pickle. HIGHEST_PROTOCOL -
整数,用于pickle的默认协议版本。可能会少于
HIGHEST_PROTOCOL。目前默认的协议是3,一种为Python 3设计的新协议。
pickle. DEFAULT_PROTOCOL 该pickle模块提供以下功能,使pickling过程更加方便:
-
将obj的pickle表示写入打开的文件对象 文件。这相当于。
Pickler(file, protocol).dump(obj)可选的协议参数,一个整数,告诉pickler使用给定的协议; 支持的协议是0到
HIGHEST_PROTOCOL。如果未指定,则默认为DEFAULT_PROTOCOL。如果指定了负数,HIGHEST_PROTOCOL则选中。文件参数必须具有接受单个字节的参数写()方法。因此它可以是为二进制写入,
io.BytesIO实例或任何符合此接口的其他自定义对象打开的磁盘上文件 。如果fix_imports为true并且protocol小于3,pickle会尝试将新的Python 3名称映射到Python 2中使用的旧模块名称,以便pickle数据流可以用Python 2读取。
pickle. dump ( obj , file , protocol = None , * , fix_imports = True ) -
将对象的pickled表达式作为
bytes对象返回,而不是将其写入文件。参数protocol和fix_imports与in中的含义相同
dump()。
pickle. dumps ( obj , protocol = None , * , fix_imports = True ) -
从打开的文件对象 文件读取一个pickle对象表示并返回其中指定的重组对象层次结构。这相当于
Unpickler(file).load()。自动检测pickle的协议版本,因此不需要任何协议参数。经过pickle对象的表示的字节被忽略。
参数文件必须有两个方法,一个使用整数参数的read()方法和一个不需要参数的readline()方法。两种方法都应该返回字节。因此,文件可以是为二进制读取打开的磁盘上文件,
io.BytesIO对象或符合此界面的任何其他自定义对象。可选的关键字参数是fix_imports,编码和错误,用于控制由Python 2生成的pickle stream的兼容性支持。如果fix_imports为true,pickle将尝试将旧的Python 2名称映射到Python 3中使用的新名称。编码和 错误告诉pickle如何解码由Python 2腌制的8位字符串实例; 这些默认值分别为'ASCII'和'strict'。该编码可以是“字节”作为字节对象读取这些8位串的实例。
pickle. load ( file , * , fix_imports = True , encoding =“ASCII” , errors =“strict” ) -
从
bytes对象中读取一个pickled object层次结构并返回其中指定的重组对象层次结构。自动检测pickle的协议版本,因此不需要任何协议参数。经过腌渍对象的表示的字节被忽略。
可选的关键字参数是fix_imports,编码和错误,用于控制由Python 2生成的pickle stream的兼容性支持。如果fix_imports为true,pickle将尝试将旧的Python 2名称映射到Python 3中使用的新名称。编码和 错误告诉pickle如何解码由Python 2pickel的8位字符串实例; 这些默认值分别为'ASCII'和'strict'。该编码可以是“字节”作为字节对象读取这些8位串的实例。
pickle. loads ( bytes_object , * , fix_imports = True , encoding =“ASCII” , errors =“strict” ) import pickledataList = [[1, 1, '是'],[1, 1, '是'],[1, 0, '是'],[0, 1, '负']]dataDic = {0: [1, 2, 3, 4],1: ('E', 'F'),2: {'e': 'yes', 'f': 'no'}}# 使用dump()将数据序列化到文件中
fw = open('dataFile.txt', 'wb')
# Pickle the list using the highest protocol available.
#protocol:序列化使用的协议。如果该项省略,则默认为0。
# 如果为负值或HIGHEST_PROTOCOL,则使用最高的协议版本
pickle.dump(obj=dataList, file=fw, protocol=-1)
# Pickle dictionary using protocol 0.
pickle.dump(obj=dataDic, file=fw)
fw.close()# 使用load()将数据从文件中序列化读出
fr = open('dataFile.txt', 'rb')
data1 = pickle.load(fr)
print('data1:', data1)
data2 = pickle.load(fr)
print('data2:', data2)
fr.close()# 使用dumps()和loads()举例
p1 = pickle.dumps(dataList)
print('p1:', pickle.loads(p1))
p2 = pickle.dumps(dataDic)
print('p2:', pickle.loads(p2))结果: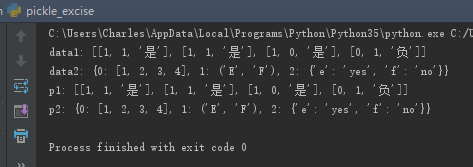
若要进一步了解可查看: 源代码
这篇关于pickle序列化学习笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







