pagerank专题

随机游走的PageRank算法 sensitive PageRank
随机游走的pagerank建立在pagerank基础之上, PageRank的简单介绍请看这里http://blog.csdn.net/zhonghuan1992/article/details/24396435 请先看随机游走的pageRank算法部分代码(代码写的挫了写见谅),根据代码分析 #include <cstdio>#include <cstring>#includ

PageRank算法浅析
转载请注明出处!!!http://blog.csdn.net/zhonghuan1992 本文是根据 Topic-Sensitive PageRank Google’s PageRank:The Math Behind the Search Engine http://blog.csdn.net/hguisu/article/details/7996185 http://blog


搜索引擎算法之初探——PageRank、DocRank
从文档集合中找出出现搜索词的文档,进一步可能是通过搜索词在文档中出现的次数来对文档排名,这种搜索就是信息检索(Information retrieval)。 有很多现有的库可以很方便的就让我们做出来这些工作,其中最有名的当属Lucene了。当然,现在的搜索已不单单是索引了,而在于链接分析、用户点击分析和自然语言处理等方面,这些技术能大大的增强搜索的性能。 基本搜索 构建一个搜索引擎的基本步骤
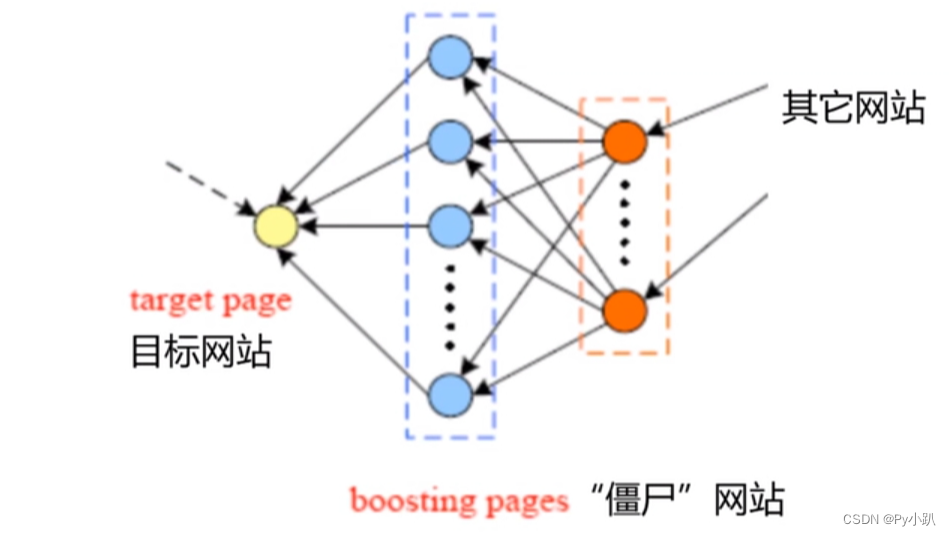
【补充】图神经网络前传——PageRank
对于任何一个网页,都可以给出网页的重要度,给每个网页重要度打分,高分的靠前。 改变世界的谷歌PageRank算法_哔哩哔哩_bilibili (这个参考资料考虑之后去自己看看) 把互联网用图来表示,每一个网页就是一个节点,网页之间的引用(放一个超链接,比如)就是边。不过现在可能这样就不太方便了,因为现在的网页是可以随时生成的(比如支付成功页面),同时还有无法触达的部分(比如朋
头歌:Spark案例剖析 - 谷歌网页排名引擎PageRank实战
第1关:海量数据导入:SparkSQL大数据导入处理 任务描述 工欲善其事必先利其器,大数据分析中最重要的是熟练掌握数据导入工具的使用方法。Spark SQL是Spark自带的数据库,本关你将应用Spark SQL的数据导入工具实现文本数据的导入。其中,graphx-wiki-vertices.txt文件中含有网页及其id数据,graphx-wiki-edges.txt文件中含有网页及其连接网
Python数学建模学习-PageRank算法
1-基本概念 PageRank算法是由Google创始人Larry Page在斯坦福大学时提出,又称PR,佩奇排名。主要针对网页进行排名,计算网站的重要性,优化搜索引擎的搜索结果。PR值是表示其重要性的因子。 中心思想: 数量假设:在网页模型图中,一个网页接受到的其他网页指向的入链(In-Links)越多,说明该网页越重要。 质量假设:当一个质量高的网页指向(Out-Link
十四、PageRank工具NetworkX的使用
igraph:处理复杂网络问题,提供Python, R, C语言接口 性能强大,效率比NetworkX高 NetworkX:基于python的复杂网络库 对于Python使用者友好 NetworkX的简单使用 # 使用networkX计算节点的pagerankimport networkx as nximport matplotlib.pyplot as plt# 创建有向图G =

超链分析和PageRank
自己整理的一些资料 超链分析 超链分析的基本原理是:在某次搜索的所有结果中,被其他网页用超链指向得越多的网页,其价值就越高,就越应该在结果排序中排到前面。超链分析是一种引用投票机制,对于静态网页或者网站主页,它具有一定的合理性,因为这样的网页容易根据其在互联网上受到的评价产生不同的超链指向量,超链分析的结果可以反映网页的重要程度,从而给用户提供更重要、更有价值的搜索结果。 可是搜索引擎,
pageRank.py的计算
pyspark GOGOGO! 1.加载数据 sc = SparkContext(appName="PythonPageRank") # Loads in input file. It should be in format of: # URL neighbor URL # URL neighbor
数据挖掘十大经典算法之——PageRank 算法
数据挖掘十大经典算法系列,点击链接直接跳转: 数据挖掘简介及十大经典算法(大纲索引) 1. 数据挖掘十大经典算法之——C4.5 算法 2. 数据挖掘十大经典算法之——K-Means 算法 3. 数据挖掘十大经典算法之——SVM 算法

python networkx PageRank
最近用Java写了个pagerank,发现最终算出来的PageRank值的和不是1,但是这个和应该是1的,所以就用python的networkx包中的PageRank算法做了一个测试: import osimport networkx as nxos.chdir('C:\\Users\\XXX\\Desktop\\')filename = 'Wiki-Vote.txt'G=nx

从PageRank到TextRank的简要介绍
PageRank PageRank部分主要参考bilibili网站的视频,视频讲解的比较清晰易懂,视频目录内容如下: 接下来做简单的几点总结: PageRank的定义和由来 PageRank,网页排名,又称网页级别、Google左侧排名或佩奇排名,是一种由 [1] 根据网页之间相互的超链接计算的技术,而作为网页排名的要素之一,以Google公司创办人拉里·佩奇(Larry Page)之姓来命
HITS算法类PageRank
百度百科: 理解HITS算法是Web结构挖掘中最具有权威性和使用最广泛的算法。HITS(Hypertext-InducedTopic Search)算法是利用Web的链接结构进行挖掘典型算法,其核心思想是建立在页面链接关系的基础上,对链接结构的改进算法。HITS算法通过两个评价权值——内容权威度(Authority)和链接权威度(Hub)来对网页质量进行评估。其基本思想是利用页面之间的引用链来挖

数学建模--PageRank算法的Python实现
文章目录 1. P a g e R a n k PageRank PageRank算法背景2. P a g e R a n k PageRank PageRank算法基础2.1. P a g e R a n k PageRank PageRank问题描述2.2.有向图模型2.3.随机游走模型 3. P a g e R a n k PageRank PageRank算法定义3.1. P a g
Google公开确认将停止提供PageRank,SEO怎么办?
近日,Google已经确认将停止公开提供PageRank,这意味着任何从Google获取并展示PageRank数据的浏览器、工具栏,很快就再也没有任何数据了。 PageRank诞生于2000年,以特定算法为网页排序,得分范围0-10(越高越好),能让用户直观地了解网页的价值等级,但也催生了庞大的SEO(搜索引擎优化)地下产业,让很多毫无价值的网页也能得到高分

机器学习笔记--PageRank算法
斯坦福大学CS224W图机器学习笔记 学习参考 CS224W公开课:双语字幕 斯坦福CS224W《图机器学习》课程(2021) by Jure Leskove 官方课程主页:官方主页 子豪兄精讲:斯坦福CS224W图机器学习、图神经网络、知识图谱 同济子豪兄 子豪兄公开代码:同济子豪兄CS224W公开课 基于图的项目: 读论文、搜论文、做笔记、吐槽论文的社区:ReadPaper可以画

大数据挖掘笔记2——PageRank
1.PageRank PageRank是一个函数,为Web中每个网页赋予一个实数值。PageRank值越高,越重要。 Web转移矩阵:描述随机冲浪者下一步的访问行为。网页数目为n,则M为一个n*n的方阵。网页j有k条出链,则对链向网页i的元素值Mij=1/k。 第一列表示处于A的随机冲浪者将以1/3的概率访问其他3个网页。随机冲浪者位置的概率分布可以通过n维列向量描述,第j个分量代表冲
PageRank 算法-Google 如何给网页排名
PageRank 算法-Google 如何给网页排名 在互联网早期,随着网络上的网页逐渐增多,如何从海量网页中检索出我们想要的页面,变得非常的重要。 当时著名的雅虎和其它互联网公司都试图解决这个问题,但都没能有一个很好的解决方案。 直到1998 年前后,两位斯坦福大学的博士生,拉里·佩奇和谢尔盖·布林一起发明了著名的 PageRank 算法,才完美的解决了网页排名的问题。也正是因为这个
一瞬间的触动:PageRank
摘自《数学之美》 在互联网上,如果一个网页被很多其他网页所链接,说明它受到普遍的承认和信赖,那么它的排名就高。这就是PageRank的核心思想。当然Google的PageRank算法实际上要复杂得多。比如说,对来自不同网页的链接区别对待,因为那些排名高的网页的链接更可靠,于是要给这些链接以较大的权重。这就好比在现实世界中股东大会里的表决,要考虑每个股东的表决权( Voting Power),拥有
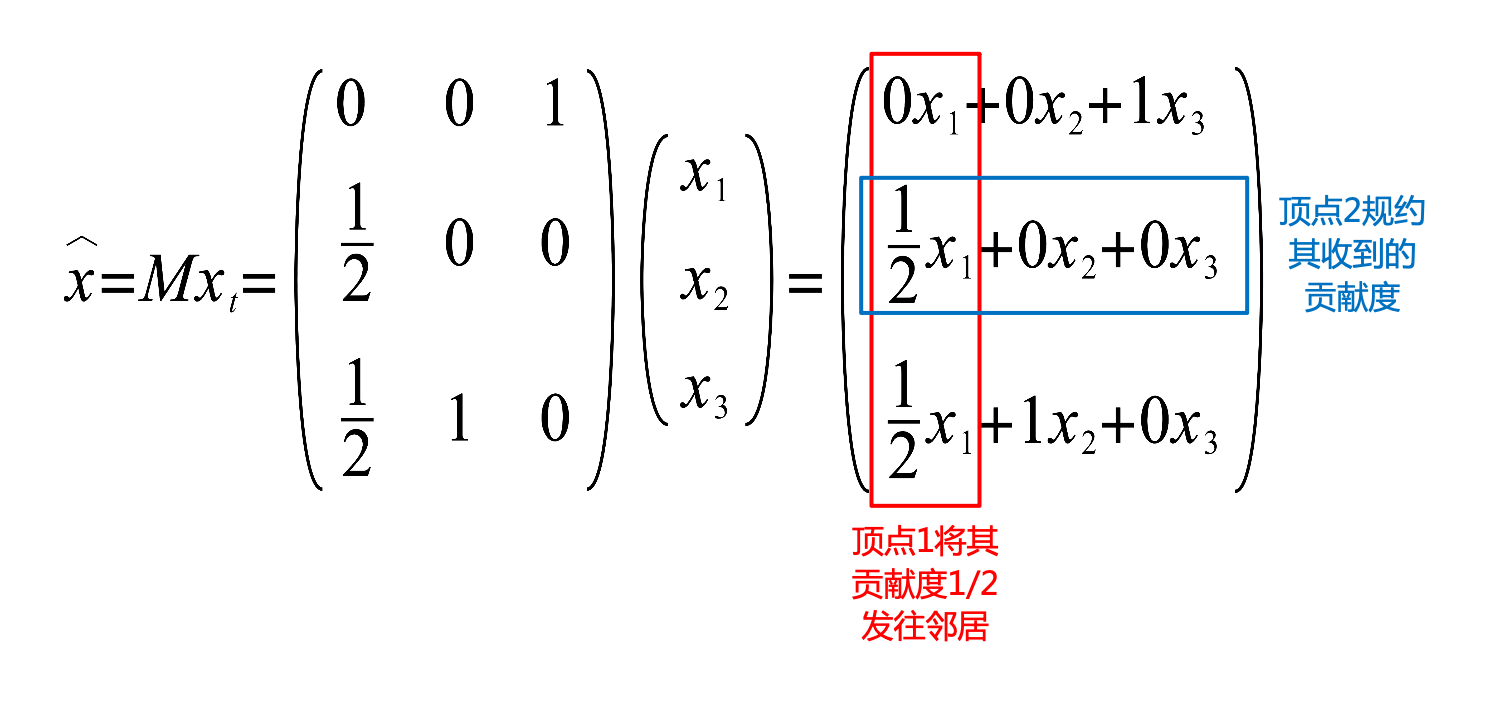
PageRank迭代求解方法
PageRank算法迭代求解第二版程序 /* 描述: 小型Web超链图的PageRank算法迭代求解 作者: xiaocui 时间: 2008.4.19 版本: v1.0 */ /*简单的PageRank算法为 PR(T) = PR(T1)/C(T1)+...+PR(Tn)/C(Tn)), 最后写成了 P = M * P, P为n个网页的pagerank值组成的列向量, M为马尔可夫转移矩阵,
《数学之美》第三版的读书笔记一、主要是马尔可夫假设、隐马尔可夫模型、图论深度/广度、PageRank相关算法、TF-IDF词频算法
1、马尔可夫假设 从19世纪到20世纪初,俄国有个数学家叫马尔可夫他提出了一种方法,假设任意一个词出现的概率只同它前面的词有关。这种假设在数学上称为马尔可夫假设。 2、二元组的相对频度 利用条件概率的公式,某个句子出现的概率等于每一个词出现的条件概率相乘,于是可展开为: 有了语料库,只要数一数,这对词在统计的文本中前后相邻出现了多少次#(
分布式机器学习:PageRank算法的并行化实现(PySpark)
🚀 优质资源分享 🚀 学习路线指引(点击解锁)知识定位人群定位🧡 Python实战微信订餐小程序 🧡进阶级本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。💛Python量化交易实战💛入门级手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 1. PageRank的两种串行迭代求解算法 我们在博客《数值分析:幂迭代和P

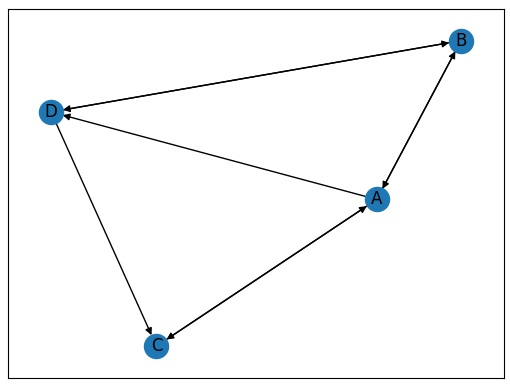
PageRank计算方法及java实现
倒排索引解决的是如何有效的搜索包含某一关键字的网页,PageRank就是如何计算这些网页的价值。PageRank的计算是根据网页的链接计算的。若有1,2,3,4号网页之间的链接关系如下: 这里假设每个网页的权重相等,都为1,这个S矩阵是这样得出来的,第1列是1号网页,它指向了2,3,4号网页,它的权重为1,所以2,3,4每个获得的为1/3,这样依次类推。 求解G的特征向量可以通过q(
PageRank算法与特征向量和特征值(eigenvector和eigenvalue)
1. PageRank算法概述 PageRank,即网页排名,又称网页级别、Google左侧排名或佩奇排名。 是Google创始人拉里·佩奇和谢尔盖·布林于1997年构建早期的搜索系统原型时提出的链接分析算法,自从Google在商业上获得空前的成功后,该算法也成为其他搜索引擎和学术界十分关注的计算模型。目前很多重要的链接分析算法都是在PageRank算法基础

PageRank算法c++实现
首先用邻接矩阵A表示从页面j到页面i的概率,然后根据公式生成转移概率矩阵 M=(1-d)*Q+d*A 常量矩阵Q=(qi,j),qi,j=1/n 给定点击概率d,等级值初始向量R0,迭代终止条件e; 计算Ri+1=M*Ri; ei=|Ri+1-Ri|,当ei<=e时输出Ri+1作为最终等级值向量。 #include "fstream"