本文主要是介绍超链分析和PageRank,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
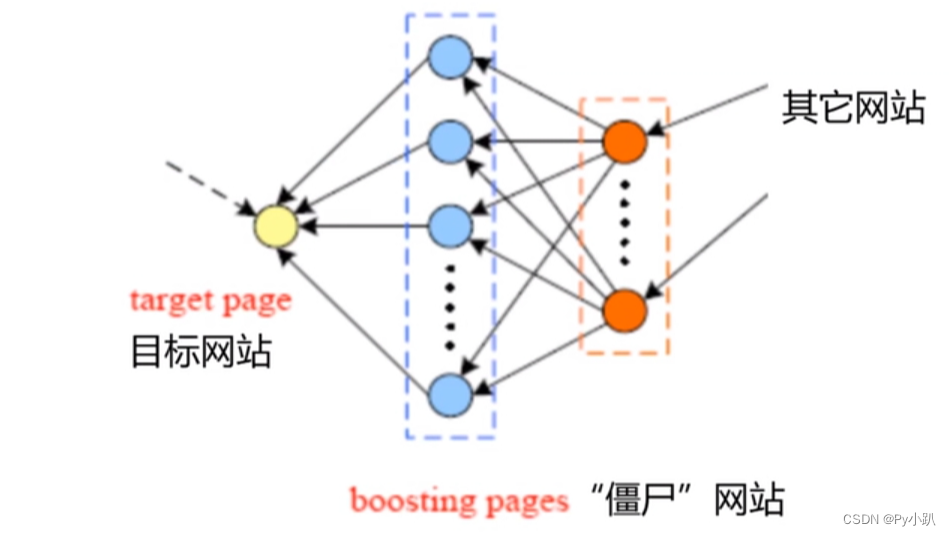
自己整理的一些资料超链分析超链分析的基本原理是:在某次搜索的所有结果中,被其他网页用超链指向得越多的网页,其价值就越高,就越应该在结果排序中排到前面。超链分析是一种引用投票机制,对于静态网页或者网站主页,它具有一定的合理性,因为这样的网页容易根据其在互联网上受到的评价产生不同的超链指向量,超链分析的结果可以反映网页的重要程度,从而给用户提供更重要、更有价值的搜索结果。可是搜索引擎,并不能真正理解网页上的内容,它只能机械地匹配网页上的文字。它收集了互联网上几千万到几十亿个网页并对网页中的每一个文字(即关键词)进行索引,建立索引数据库的全文搜索引擎。当用户查找某个关键词的时候,所有在页面内容中包含了该关键词的网页都将作为搜索结果被搜出来。在经过复杂的算法进行排序后,这些结果将按照与搜索关键词的相关度高低,依次排列。搜索引擎在查询时主要根据一个站点的内容与查询词的关联程度进行排序。对于一个站点的内容搜索引擎则是根据标题、关键词、描述、页面开始部分的内容以及这些内容本身之间的关联程度以及一个站点在整个网络上的关联程度来确定的。使用超链分析技术,除要分析索引网页本身的文字,还要分析索引所有指向该网页的链接的URL、AnchorText,甚至链接周围的文字。所以,有时候,即使某个网页A 中并没有某个词,比如“软件”,但如果有别的网页B 用链接“软件”指向这个网页A,那么用户搜索“软件”时也能找到网页A。而且,如果有越多网页(C、D、E、F……)用名为“软件” 的链接指向这个网页A,或者给出这个链接的源网页(B、C、D、E、F……)越优秀,那么网页A 在用户搜索“超链分析”时也会被认为相关度越高,排序也会越靠前。超链分析是最近几年搜索引擎技术的研究重点,取得了很大的成功,百度等搜索引擎的技术基础,但是,从搜索引擎的基本功能来看,超链分析很可能是走入了一条错误的道路。搜索引擎的基本功能是从浩如烟海的网页信息中找到用户所想要寻找的信息,目前所有实用的搜索引擎技术都是以“关键字匹配”为最基础的原理的。但是,超链分析本质上是针对一种公开的、通行的价值评估体系的。当用户搜索的目的是寻找关于某些关键字的站点资源或网站入口时,它是有效的;但当用户搜索的目的是寻找关于某些内容的有效信息本身时,超链分析的结果不仅没有参考价值,而且会破坏用户搜索结果的精确度。
这篇关于超链分析和PageRank的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!