本文主要是介绍pageRank.py的计算,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
pyspark GOGOGO!
1.加载数据
sc = SparkContext(appName="PythonPageRank")
# Loads in input file. It should be in format of:
# URL neighbor URL
# URL neighbor URL
# URL neighbor URL
# ...
lines = sc.textFile(sys.argv[1], 1)
2.
对同一个key的数据进行分组
# Loads all URLs from input file and initialize their neighbors.
links = lines.map(lambda urls: parseNeighbors(urls)).distinct().groupByKey().cache()
# Loads all URLs with other URL(s) link to from input file and initialize ranks of them to one.
ranks = links.map(lambda url_neighbors: (url_neighbors[0], 1.0))
画个图表示
这里我只是画了两个group key
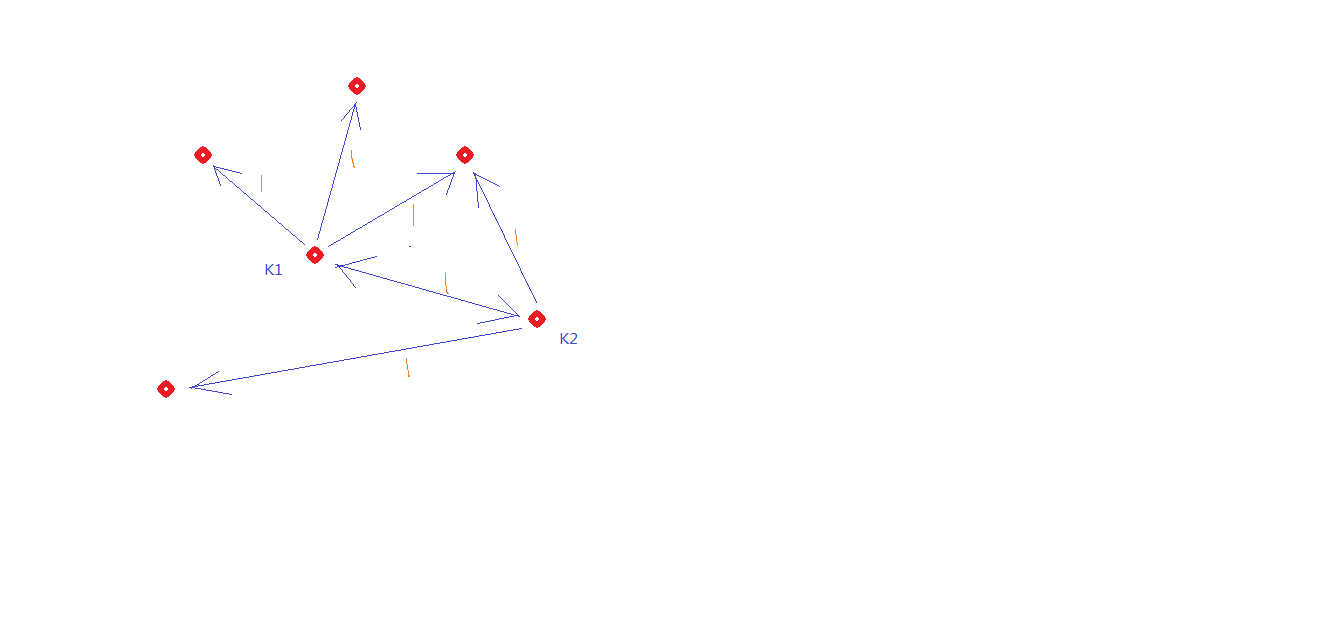
橙色的表示初始rank值为1
3.
这篇关于pageRank.py的计算的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



