neighbor专题

python K-Nearest Neighbor KNN算法
1、最初的邻近算法,分类算法,基于实例的学习,懒惰学习。 2、算法步骤: a、为了判断未知实例类别,选择所有已知的实例作为参考 b,选择参数k c,计算未知实例和所有已知实例的距离 d,选择最近k个已知实例 e,根据少数服从多数,让未知实例归类为k个中最多的类别 公式:E(x,y)=(xi-yi)^2求和之后再开方 import mathdef ComputeEuclidean

lightoj 1047 Neighbor House(Dp)
思路:定义dp[i][j] 为粉刷第i个房子用的颜色j dp[i][j] = min(dp[i-1][(j+1)%3] , dp[i-1][(j+2) % 3]); 一共有三种颜色{0, 1, 2},任取一种颜色{j},那么和颜色j不同的颜色就为{(j + 1) % 3 , (j + 2) % 3}; /******************************************
LightOJ 1047 - Neighbor House(dp)
题目链接:LightOJ 1047 - Neighbor House 代码 #include <cstdio>#include <cstring>#include <algorithm>using namespace std;const int maxn = 30;const int inf = 0x3f3f3f3f;int N, dp[maxn][3];int main () {in
用最近邻插值(Nearest Neighbor interpolation)进行图片缩放
图片缩放的两种常见算法: 最近邻域内插法(Nearest Neighbor interpolation) 双向性内插法(bilinear interpolation) 本文主要讲述最近邻插值(Nearest Neighbor interpolation算法的原理以及python实现 基本原理 最简单的图像缩放算法就是最近邻插值。顾名思义,就是将目标图像各点的像素值设为源图像

K Nearest Neighbor
KNN算法 概述 KNN算法:即最邻近分类算法(K-NearestNeighbor 算法思路:如果一个样本在特征空间中的k个最相似(即特征空间中最临近)的样本中的大多数属于某一个类别 则该样本也属于这个类别 k通常是不大于20的整数 KNN算法中 所选择的邻居都是已经正确分类的对象 该方法在定义决策上只依据最邻近的一个或几个样本的类别来决定待分样本所属的类别 如上所示 绿色圆要被决定

【机器学习】KNN(K-Nearest Neighbor)
KNN简介 KNN算法又称为K最近邻分类(K-nearest neighbor classification)算法,是一种非常简单的机器学习分类算法。 KNN算法的原理十分简单:对于待分类的样本,计算其到所有训练样本的距离,从中选取K个距离最近的训练样本,统计这K个距离最近的训练样本所属的类别,按照少数服从多数的原理,将待分类的样本归入k个训练样本所属数目最

机器学习之深入理解K最近邻分类算法(K Nearest Neighbor)
【机器学习】《机器学习实战》读书笔记及代码:第2章 - k-近邻算法 1、初识 K最近邻分类算法(K Nearest Neighbor)是著名的模式识别统计学方法,在机器学习分类算法中占有相当大的地位。主要应用领域是对未知事物的识别,即推断未知事物属于哪一类。 推断思想是,基于欧几里得定理,推断未知事物的特征和哪一类已知事物的的特征最接近。简单来说就是:如果一个样本在特征空间中的k个最相似(
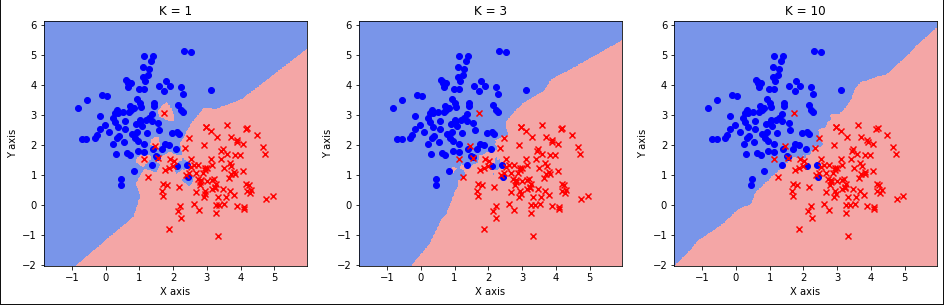
【机器学习】k近邻(k-nearest neighbor )算法
文章目录 0. 前言1. 算法原理1.1 距离度量1.2 参数k的选择 2. 优缺点及适用场景3. 改进和扩展4. 案例5. 总结 0. 前言 k近邻(k-nearest neighbors,KNN)算法是一种基本的监督学习算法,用于分类和回归问题。k值的选择、距离度量及分类决策规则是k近邻法的三个基本要素。 1. 算法原理 给定一个训练数据集,KNN算法通过计算待分类样本与
李宏毅机器学习课程笔记5:Unsupervised Learning - Linear Methods、Word Embedding、Neighbor Embedding
台湾大学李宏毅老师的机器学习课程是一份非常好的ML/DL入门资料,李宏毅老师将课程录像上传到了YouTube,地址:NTUEE ML 2016 。 这篇文章是学习本课程第13-15课所做的笔记和自己的理解。 **Lecture 13: Unsupervised Learning - Linear Methods ** Unsupervised Learning有两种,化繁为简(Cluste
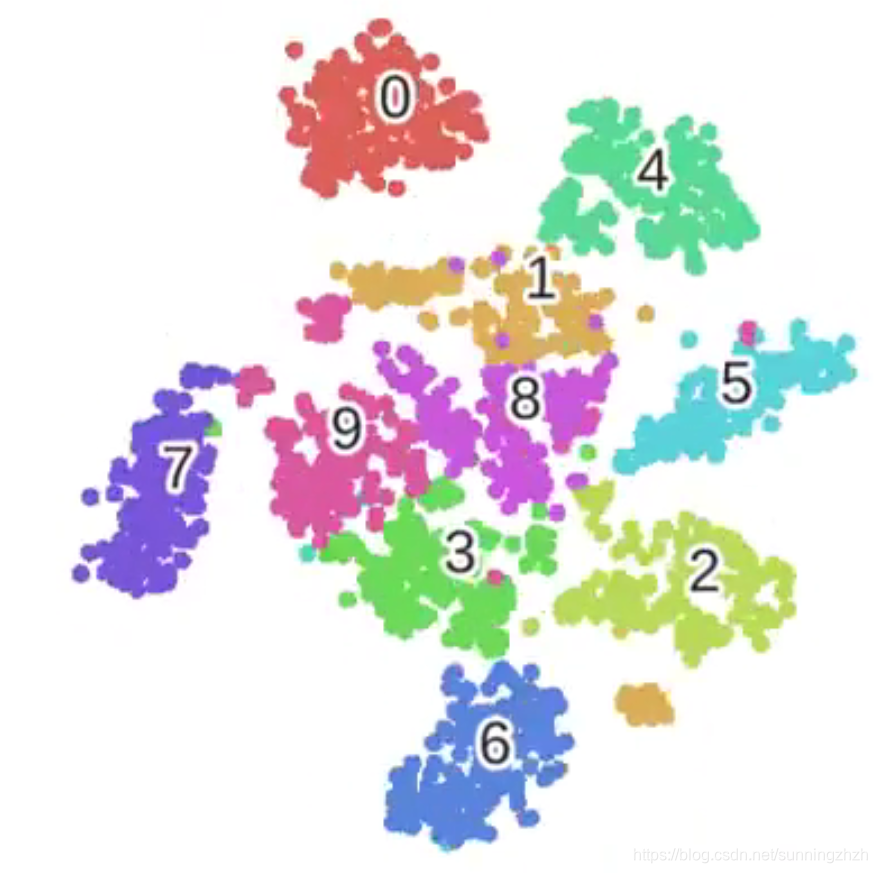
WDK李弘毅学习笔记第十周01_Unsupervised Learning: Neighbor Embedding
Unsupervised Learning: Neighbor Embedding 文章目录 Unsupervised Learning: Neighbor Embedding摘要1、Manifold Learning1.1 Locally Linear Embedding(LLE)1.1.1 思想1.1.2 做法1.1.3 实验 1.2 Laplacian Eigenmaps(拉普拉斯特
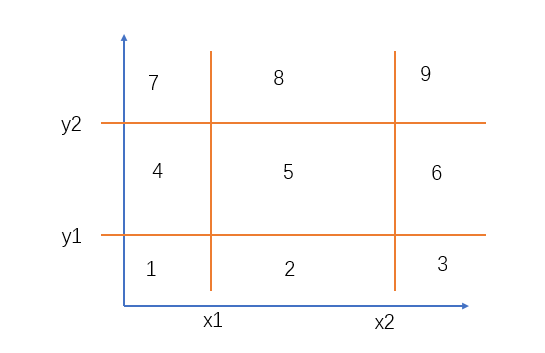
Nearest Neighbor Search 简单几何(求空间一点到区域的距离)
题目链接: https://acm.bnu.edu.cn/v3/statments/52296.pdf 题意: 求空间一点(x0,y0,z0),到三维空间区域的最小距离? 分析: 先求二维平面的最小距离(将平面分为9部分分别处理即可),再求高的距离。 AC代码: #include <iostream>#include <cstdio>#include <cstring>#i

2.机器学习-K最近邻(k-Nearest Neighbor,KNN)分类算法原理讲解
2️⃣机器学习-K最近邻(k-Nearest Neighbor,KNN)分类算法原理讲解 个人简介一·算法概述二·算法思想2.1 KNN的优缺点 三·实例演示3.1电影分类3.2使用KNN算法预测 鸢(yuan)尾花 的种类3.3 预测年收入是否大于50K美元 个人简介 🏘️🏘️个人主页:以山河作礼。 🎖️🎖️:Python领域新星创作者,CSDN实力新星认证,C

无监督学习 - t-分布邻域嵌入(t-Distributed Stochastic Neighbor Embedding,t-SNE)
什么是机器学习 t-分布邻域嵌入(t-Distributed Stochastic Neighbor Embedding,t-SNE)是一种非线性降维技术,用于将高维数据映射到低维空间,以便更好地可视化数据的结构。t-SNE主要用于聚类分析和可视化高维数据的相似性结构,特别是在探索复杂数据集时非常有用。 t-SNE的基本原理 相似度测量: 对于高维数据中的每一对数据点,计算它们之间的相似度。

我的cs231n学习笔记(2)lecture2-K Nearest Neighbor
lecture2:KNN 根据KNN算法所做的表现效果并不是很好: 我们可以通过将k值调大的方法使算法表现的更好,但还有另外一个选择,更换距离函数。L2 distance距离函数也叫做欧式距离函数(Euclidean distance) 不同的距离度量函数在预测的空间里对底层的几何或拓扑结构做出不同的假设。 kNN模拟 k值、距离函数成为超参数(hyperparameters),因为他们并
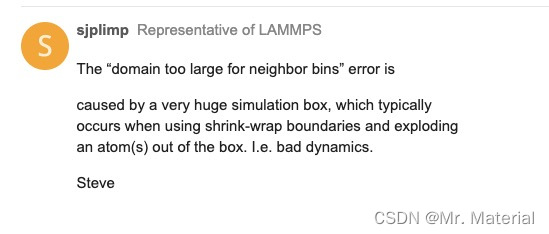
Lammps错误:domain too large for neighbor bins
关注 M r . m a t e r i a l , \color{Violet} \rm Mr.material\ , Mr.material , 更 \color{red}{更} 更 多 \color{blue}{多} 多 精 \color{orange}{精} 精 彩 \color{green}{彩} 彩! 主要专栏内容包括: †《LAMMPS小技巧》: ‾ \textbf{ \
机器学习: t-Stochastic Neighbor Embedding 降维算法 (一)
Introduction 在计算机视觉及机器学习领域,数据的可视化是非常重要的一个应用,一般我们处理的数据都是成百上千维的,但是我们知道,目前我们可以感知的数据维度最多只有三维,超出三维的数据是没有办法直接显示出来的,所以需要做降维的处理,数据的降维,简单来说就是将高维度的数据映射到较低的维度,如果要能达到数据可视化的目的,就要将数据映射到二维或者三维空间。数据的降维是一种无监督的学习过程,我们
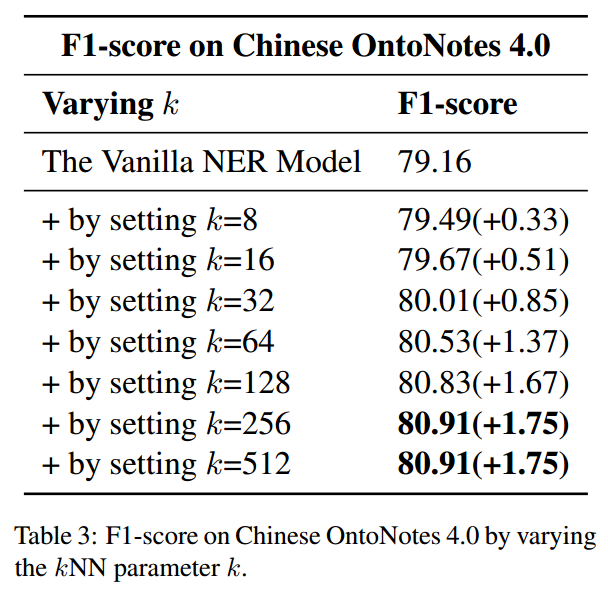
kNN-NER: Named Entity Recognition with Nearest Neighbor Search
原文链接:https://arxiv.org/pdf/2203.17103.pdf 预发表论文 介绍 受到增强式检索方法的启发,作者提出了kNN-NER,通过检索训练集中k个邻居的标签分布来提高模型命名实体识别分类的准确性。该框架能够通过充分利用训练信息来解决样本类别不平衡问题。 方法 整个模型的框架如下图所示,作者提出的框架在训练阶段不需要进行额外
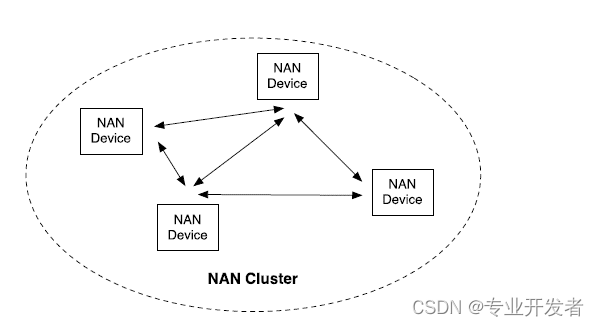
高通WLAN框架学习(12)-- Neighbor awareness networking(NAN)功能
介绍以下主题: ■邻居感知网络(NAN)概述 ■NAN的软件架构 ■调用流程:发布、订阅和匹配 ■测试程序和日志 13.1 NAN概述 社交Wi-Fi协议在Wi-Fi联盟邻居感知网络中标准化。 NAN技术在后台持续运行,发送小消息,为广泛的应用提供服务发现。 NAN设备在连接之前就发现了,进一步提高了Wi-Fi对社交应用(如游戏、点对点消息和媒体共享)的便利性; 以及特定位置的服务

【机器学习笔记】——k近邻(k-nearest neighbor,k-NN)
目 录 1 k-NN 1.1 基本思路 1.1.1 距离度量1.1.2 k值的选择1.1.3 决策1.2 基于kd树的k-NN算法 1.2.1 构造kd树1.2.2 搜索kd树(基于kd树的k-NN算法) 1.2.2.1 基于kd树的最近邻算法1.2.2.2 基于kd树的k-NN算法1.3 k-NN的优缺点 1.3.1 优点1.3.2 缺点2 算法实现 2.1 原始形式1——自定义二维特征分类

机器学习3:K近邻法K-Nearest-Neighbor Classifier/KNN(基于R languagePython)
k k k 近邻法是一种基本分类与回归问题。 k k k 近邻法的输入为实例的特征向量,对应于特征空间中的点;输出为实例的类别,可以取很多类。 k k k 近邻法假设给定一个训练数据集,其中的实例类别已定。分类时,对新的实例,根据其 k k k 个最近邻的训练实例的类别,通过多数表决等方式进行预测。因此, k k k 近邻法不具有显式的学习过程。 k k k 近邻法实际上利用训练数据集对特
KNN(k-Nearest Neighbor)算法原理
KNN(k-Nearest Neighbor)算法是一种基于实例的学习方法,常用于分类和回归问题。下面是KNN算法的原理和步骤,以及欧式距离和曼哈顿距离的计算原理: 原理 KNN算法基于一个假设:与一个样本最相似的其他k个样本的类别可以用来预测该样本的类别。KNN算法将所有的训练数据看作一个点集,根据他们与新样本之间的距离进行分类。 步骤 KNN算法的实现步骤如下: 计算测试数据与训练数

邻居发现(Neighbor Discovery)协议
转载:http://hi.baidu.com/xiongfei2008/item/0e40d7f27e5c17d443c36a23 1. ND协议介绍 邻居发现协议(Neighbor Discovery Protocol,以下称ND协议)是IPv6的一个关键协议,可以说,ND协议是IPv4某些协议在IPv6中综合起来的升级和改进,如ARP、ICMP路由器发现和ICMP重定向等协议。当然,作为I