jieba专题

中文分词jieba库的使用与实景应用(一)
知识星球:https://articles.zsxq.com/id_fxvgc803qmr2.html 目录 一.定义: 精确模式(默认模式): 全模式: 搜索引擎模式: paddle 模式(基于深度学习的分词模式): 二 自定义词典 三.文本解析 调整词出现的频率 四. 关键词提取 A. 基于TF-IDF算法的关键词提取 B. 基于TextRank算法的关键词提取

分词关键字提取-jieba
####jieba支持三种分词模式: 精确模式,试图将句子最精确地切开,适合文本分析;全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。 ###主要功能 ####分词jieba.cut 方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数

使用 flask_whooshalchemyplus jieba 为 Flask 添加 搜索 功能
正在利用Flask仿造知乎,核心的功能都实现了,就差个搜索,可惜flask_SqlAlchemy尚未支持全文搜索,遂取网友经验,用flask_whooshalchemyplus来实现,此文记录下使用方法,以供后续自己和其他同学查找学习之用 备注:flask_whooshalchemy尚未支持py3,flask_whooshalchemy和plus原生都支持英文不支持中文,我们采用公认比较优秀的j
《自然语言处理》—— jieba库的介绍与使用
文章目录 一、jieba库有什么作用1、基本介绍2、分词模式3、常用函数4、应用场景5、安装与使用 二、示例代码1、精确模式分词2、全模式分词3、搜索引擎模式分词4、向jieba词典中添加一个新词5、自定义词典,添加到jiba词库中 一、jieba库有什么作用 jieba库是一个优秀的Python中文分词第三方库,主要用于将中文文本切分成词语或词汇单位,便于后续的自然语言处理(
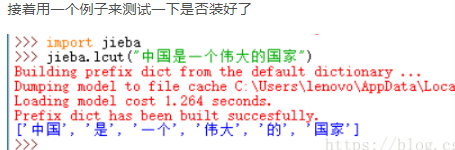
Anaconds3安装jieba 用于pycharm
1、从官网下载jieba压缩包 https://pypi.org/project/jieba/ 2、将压缩包解压到anaconda的pkgs目录。 (譬如我的如下 3、打开anaconda prompt 参考:https://blog.csdn.net/xavier_muse/article/details/94440563?utm_medium=distribute.pc_relevant

jiagu、snownlp、jieba库横向对比
github代码 中文NLP资源库:https://github.com/fighting41love/funNLP snownlp:https://github.com/isnowfy/snownlp HanLP:https://github.com/hankcs/HanLP THULAC:https://github.com/thunlp/THULAC-Python Jiagu:ht

Python文本处理利器:jieba库全解析
文章目录 Python文本处理利器:jieba库全解析第一部分:背景和功能介绍第二部分:库的概述第三部分:安装方法第四部分:常用库函数介绍1. 精确模式分词2. 全模式分词3. 搜索引擎模式分词4. 添加自定义词典5. 关键词提取 第五部分:库的应用场景场景一:文本分析场景三:中文分词统计 第六部分:常见bug及解决方案Bug 1:UnicodeDecodeErrorBug 2:Module
知识笔记——jieba分词初探
1. 简介 jieba 是python中一个非常好用的 中文分词组件,但它并不是只有分词这一个功能,还提供了很多在分词之上的算法,如关键词提取、词性标注等。 安装方式: pip install jieba 2. 分词 支持 3 种分词模式:精确模式、全模式、搜索引擎模式。 1)精确模式:试图将句子最精确地切开,词语间没有重叠。代码中通过cut_all=False选项来指定。 imp
jieba分词的几种形式
1、精确模式:试图将句子最精确地分开,适合文本分析 seg_list = jieba.cut(test_text, cut_all=False)seg_list = " ".join(seg_list)print("cut_all=False:", seg_list) 输出: cut_all=False: 我 今天下午 打篮球 2、全模式:把句子中所有的可以成词的
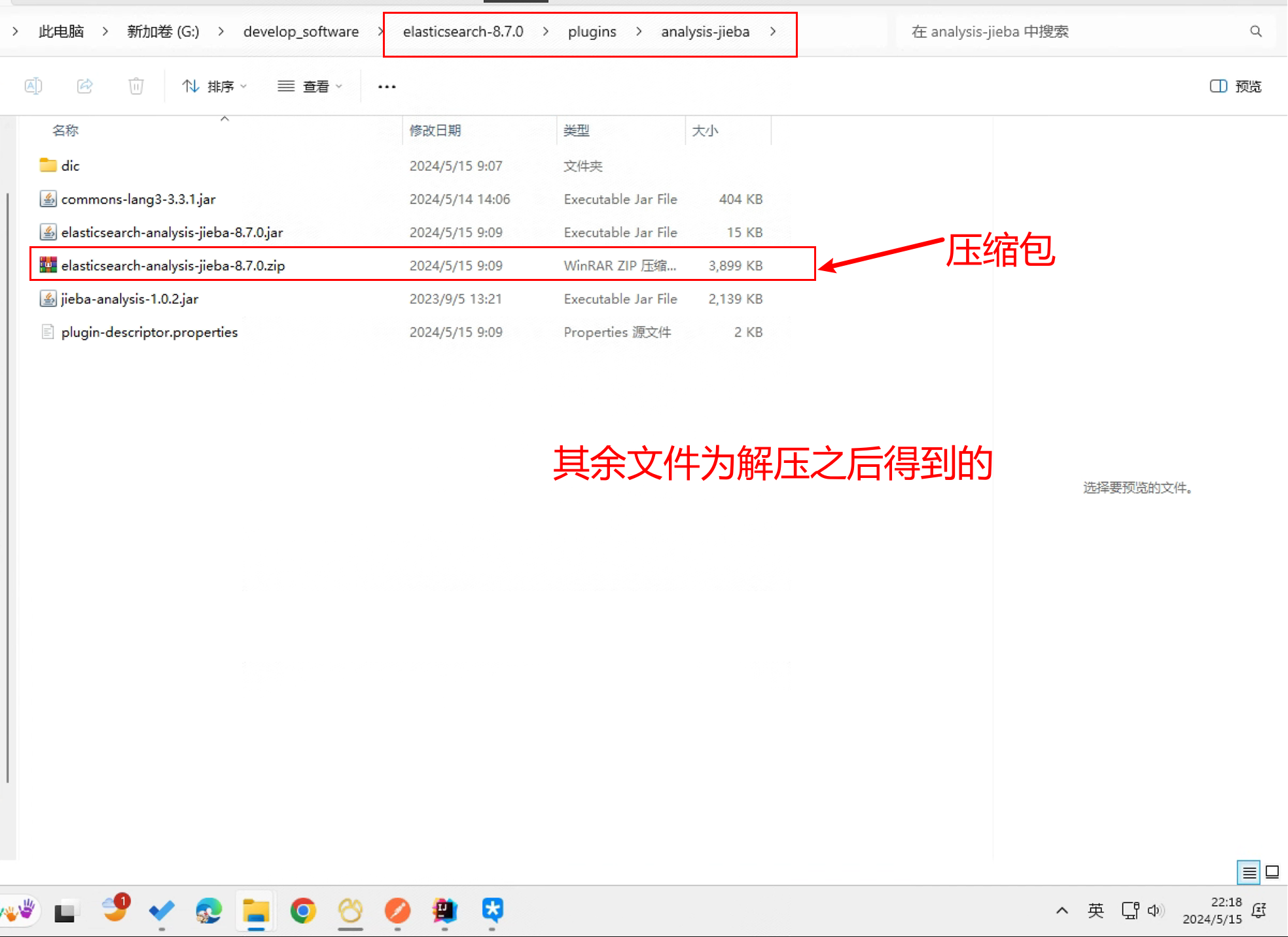
es 分词器(五)之elasticsearch-analysis-jieba 8.7.0
es 分词器(五)之elasticsearch-analysis-jieba 8.7.0 今天咱们就来讲一下es jieba 8.7.0 分词器的实现,以及8.x其它版本的实现方式,如果想直接使用es 结巴8.x版本,请直接修改pom文件的elasticsearch.version版本号即可,然后打包安装就行,不需要做太多的操作。 一、elasticsearch-jieba-plugin 最
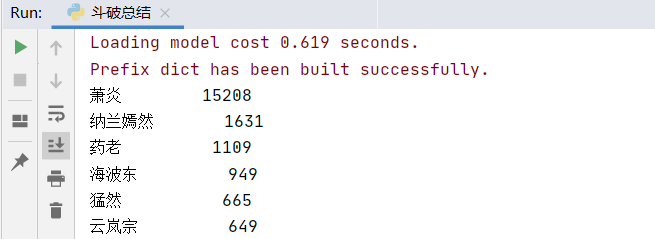
基于Python的jieba库分析《斗破苍穹》文本中的高频词汇
分析《斗破苍穹》文本中的高频词汇 在进行文本分析时,了解文本中出现频率较高的词汇对于把握文本的主题和风格非常有帮助。本文将介绍如何使用Python的jieba库对《斗破苍穹》这部小说的文本进行分词处理,并统计高频词汇的出现次数(本文只统计了小说前四百章节的内容)。 背景介绍 《斗破苍穹》是一部非常受欢迎的玄幻小说,由天蚕土豆所著。为了更好地理解这部小说的词汇使用情况,我们决定排除一些

文章分词/jieba的应用
1.将字符串中的单词找出,并输出 str1 = "The life is short,you need python"str1.split()print(str1.split())['The', 'life', 'is', 'short,you', 'need', 'python'] 2.jieba:中文第三方库 pip install jieba(CMD) //jieba安装

NLP基础—jieba分词
jieba分词 支持四种分词模式 精确模式 试图将句子最精确地切开,适合文本分析;全模式 把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;搜索引擎模式 在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。paddle模式 利用PaddlePaddle深度学习框架,训练序列标注(双向GRU)网络模型实现分词。同时支持词性标注。 paddle模式使用需安装
python jieba 分词自定义字典
python中结巴分词的准确性比较高,网上有详细的教程,包括自字义字典的使用方法。 最近在做实验室的一个小项目,其中有很多实体名不规则,需要使用自定义的字典,按照网上某些教程的方法,建立了自定义字典,该方法说只有词性是可选的,我就设置了词频,发现不管是提高还是降低数值,自己希望的自定义词仍然没有出现。后面上Git看了作者发的东西,说词频也是可选的,然后就试着把词频也去掉了,自已定义的词就出现了。

Python Jieba、pkuseg分词入门案例
pkuseg 一个领域细分的中文分词工具包。 github:https://github.com/lancopku/PKUSeg-python jieba “结巴”中文分词:做最好的 Python 中文分词组件 github:https://github.com/fxsjy/jieba 安装脚本 pip install jiebapip install pkuseg example:

中文分词,c++应用,想到jieba分词,结果还的自己封装。探索中
一、研究背景 随着互联网的快速发展,信息也呈了爆炸式的增长趋势。在海量的信息中,我们如何快速抽取出有效信息成为了必须要解决的问题。由于信息处理的重复性,而计算机又善于处理机械的、重复的、有规律可循的工作,因此自然就想到了利用计算机来帮助人们进行处理。在用计算机进行自然语言处理时,主要使用的还是基于统计的方法,并且实际的使用中取得了不错的效果。 因为中文句子
用jieba 实现中文关键词提取(TF-IDF/TEXT-RANK)
代码块: s = "此外,公司拟对全资子公司吉林欧亚置业有限公司增资4.3亿元,增资后,吉林欧亚置业注册资本由7000万元增加到5亿元。吉林欧亚置业主要经营范围为房地产开发及百货零售等业务。目前在建吉林欧亚城市商业综合体项目。2013年,实现营业收入0万元,实现净利润-139.13万元。"for x, w in jieba.analyse.extract_tags(s, withWeight
python学习1:csv模块、time模块、random、jieba、worldcloud、pycharm的虚拟环境认识、black格式化文件
标准库与第三方库 模块(modules):是包含python函数和变量的文件,名称符合Python标识符要求,并使用.py后缀 包(package):是包含其他模块、包的文件夹。名称符合Python标识符要求,并且必须有一个__init__.py 库(library):模块、包的集合 标准库是Python内置的,可以直接被使用的 csv模块:csv是数据处理中经常会用到的一种文件格式,一
Python 数据分析的敲门砖 jieba模块中文分词
文章目录 文章开篇Jieba简介使用场景jieba的引用jieba常用的方法1.精确模式分词2.搜索引擎模式分词3.添加新词4.调整词频5.提取关键词 应用案例总结 文章开篇 Python的魅力,犹如星河璀璨,无尽无边;人生苦短、我用Python! Jieba简介 jieba 是一个用于中文文本分词的 Python 库。 它能够将一整段中文文本切分成有意义
Python+jieba+pandas+自己写的函数,简单实现用多个词典标注文本
做文本分析经常需要用词典标注,有时需要用很多个不同的词典做标注,每个词典单独跑一遍 or 每个词典都重新写代码显得很傻,所以我 1. 统一了词典的格式:用excel存储,第一列是关键词,这一列对所有词典都是必需的;后面列是标签(维度划分),可能有1个或多个标签; 2. 写了几个词典标注的函数,适用于:dict0-没有标签的词典;dict1-有一列标签的词典;dict2-有两列标签的词典。一般这
jieba安装和使用教程
文章目录 jieba安装自定义词典关键词提取词性标注 jieba安装 pip install jieba jieba常用的三种模式: 精确模式,试图将句子最精确地切开,适合文本分析;全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。 可使用 jieb
Python 文本挖掘:jieba中文分词和词性标注
转自:http://rzcoding.blog.163.com/blog/static/222281017201310155331241/ jieba 分词:做最好的Python 中文分词组件。 这是结巴分词的目标,我相信它也做到了。操作简单,速度快,精度不错。而且是Python 的库,这样就不用调用中科院分词ICTCLAS了。 妈妈再也不用担心我不会分词啦。 jieba 的主页有详
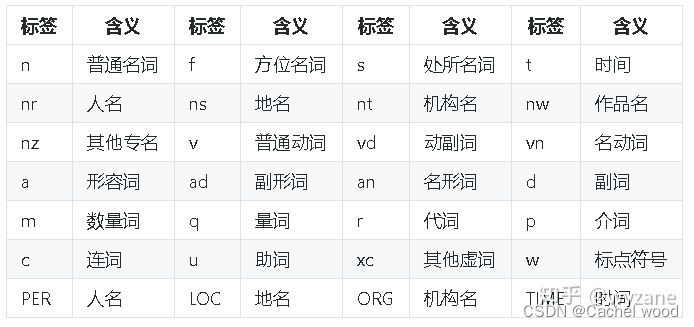
jieba(结巴)分词种词性简介
jieba为自然语言语言中常用工具包,jieba具有对分词的词性进行标注的功能,词性类别如下: Ag 形语素 形容词性语素。形容词代码为 a,语素代码g前面置以A。 a 形容词 取英语形容词 adjective的第1个字母。 ad 副形词 直接作状语的形容词。形容词代码 a和副词代码d并在一起。 an 名形词 具有名词功能的形容词。形容词代码 a和名词代码n并在一

##字典类型及jieba库Python入门(八)
今日主讲字典类型及其应用和jieba库 字典类型 可以理解为"映射“,一种键(索引)和值(数据)之间的对应 键值对:键是数据索引的扩展 字典是键值对的集合,键值对之间无序 采用大括号{}和dict创建,键值对用冒号:表示 如: a={“name”:“太原理工大学”,“address”:"山西太原”} ~~d[“name”] 对应’太原理工大学’ 值=字典变量[键] 字符类型操作函数和方法 字典

1.7Python组合数据类型及jieba库分词
目录: 一,集合类型及操作1.集合类型定义2.集合操作符3.集合处理方法4.集合类型应用场景 二,序列类型及操作(元组,列表)1.序列类型定义2.序列处理函数及方法3.元组类型及操作4.列表类型及操作5.序列类型应用场景 三, 字典类型及操作1. 字典类型定义2.字典处理函数及方法3. 字典类型应用场景4.拓展(转载至其他博客): 四,jieba库的使用1.jieba库基本介绍:2.jieb