本文主要是介绍1.7Python组合数据类型及jieba库分词,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录:
- 一,集合类型及操作
- 1.集合类型定义
- 2.集合操作符
- 3.集合处理方法
- 4.集合类型应用场景
- 二,序列类型及操作(元组,列表)
- 1.序列类型定义
- 2.序列处理函数及方法
- 3.元组类型及操作
- 4.列表类型及操作
- 5.序列类型应用场景
- 三, 字典类型及操作
- 1. 字典类型定义
- 2.字典处理函数及方法
- 3. 字典类型应用场景
- 4.拓展(转载至其他博客):
- 四,jieba库的使用
- 1.jieba库基本介绍:
- 2.jieba库的安装
- 3.jieba库使用说明
- 4.拓展(转载至其他博客):
- 五,实例
- 1.基本统计值计算:
- 2.文本词频统计:
- (1)英文文本:Hamet
- (2)中文文本:《三国演义》
一,集合类型及操作
1.集合类型定义
(集合是多个元素的无序组合)
(1)与数学上集合的基本定义基本一样;
- 集合类型与数学中的集合概念一致
- 集合元素之间无序,每个元素唯一,不存在相同元素
- 集合元素不可更改,不能是可变数据类型
(2)集合的建立: - 集合用大括号 {} 表示,元素间用逗号分隔
- 建立集合类型用 {} 或 set()
- 建立空集合类型,必须使用set()
>>> A = {"python", 123, ("python",123)} #使用{}建立集合
{123, 'python', ('python', 123)}
>>> B = set("pypy123") #使用set()建立集合
{'1', 'p', '2', '3', 'y'}
>>> C = {"python", 123, "python",123}
{'python', 123}
2.集合操作符
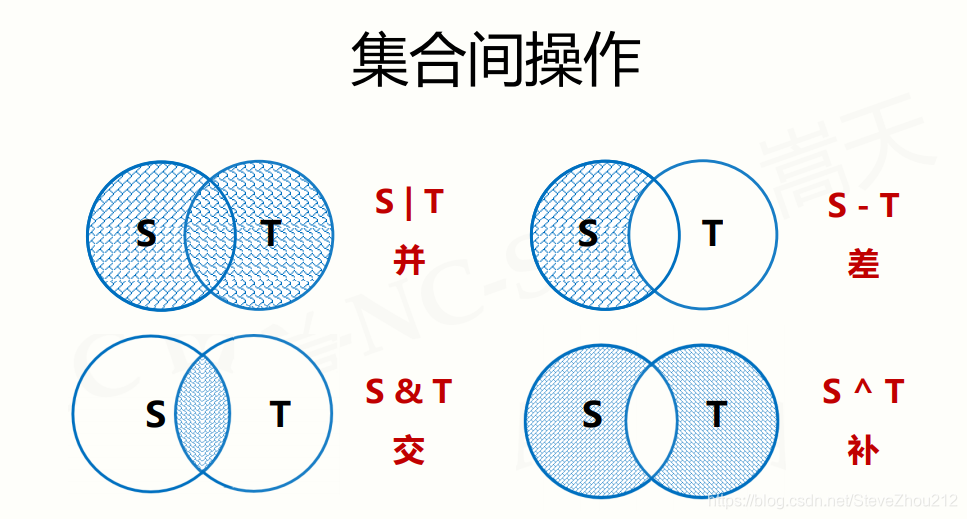
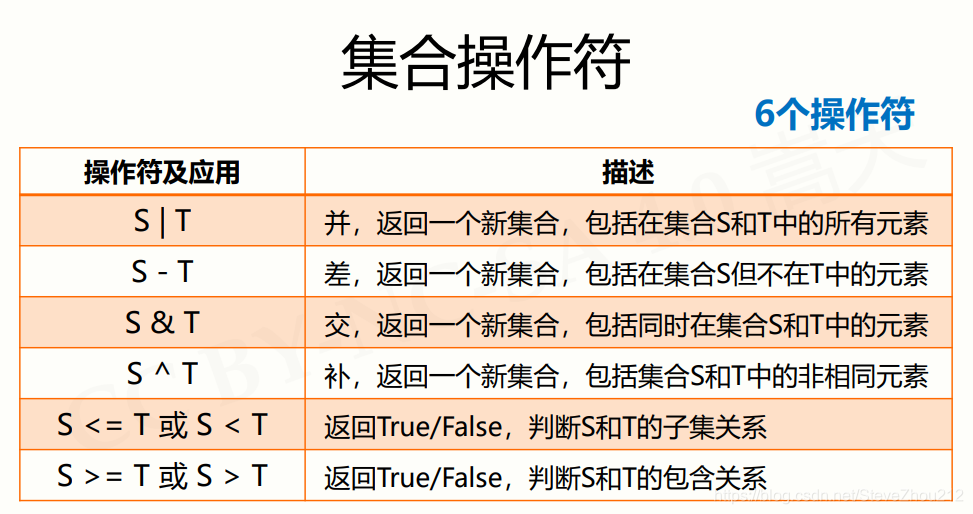
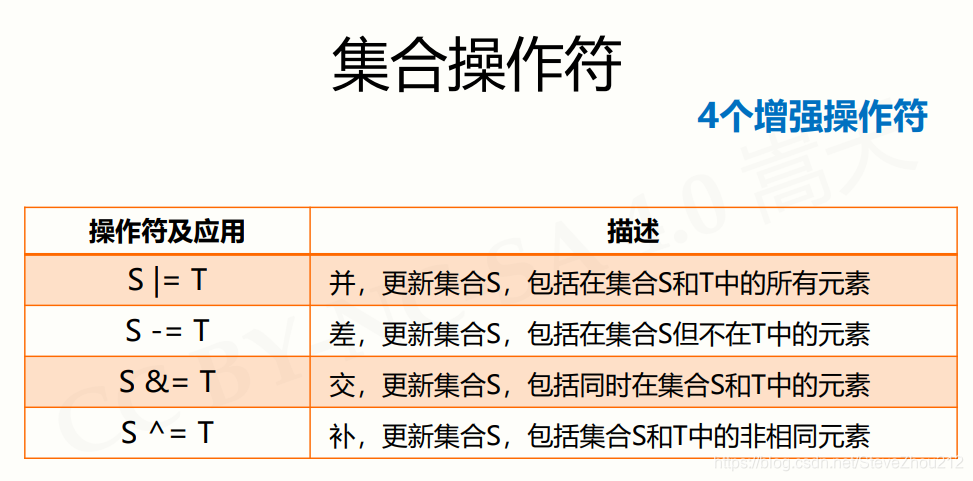
实例:
>>> A = {"p"
,
"y" , 123}
>>> B = set("pypy123")
>>> A-B
{123}
>>> B-A
{'3', '1', '2'}
>>> A&B
{'p', 'y'}
>>> A|B
{'1', 'p', '2', 'y', '3', 123}
>>> A^B
{'2', 123, '3', '1'}
3.集合处理方法


实例:
>>> A = {"p"
,
"y" , 123}
>>> for item in A:
print(item, end="")
p123y
>>> A
{'p', 123, 'y'}
>>> try:
while True:
print(A.pop(), end=""))
except:
pass
p123y
>>> A
set()
4.集合类型应用场景
(1)包含关系比较
示例:
>>> "p" in {"p", "y" , 123}
True
>>> {"p", "y"} >= {"p", "y" , 123}
False
(2)数据去重:集合类型所有元素无重复
示例:
>>> ls = ["p", "p", "y", "y", 123]
>>> s = set(ls) # 利用了集合无重复元素的特点
{'p', 'y', 123}
>>> lt = list(s) # 还可以将集合转换为列表
['p', 'y', 123]
二,序列类型及操作(元组,列表)
1.序列类型定义
(序列是具有先后关系的一组元素)
- 序列是一维元素向量,元素类型可以不同
- 类似数学元素序列: s0, s1, … , sn-1
- 元素间由序号引导,通过下标访问序列的特定元素
-序列是一个基类类型:
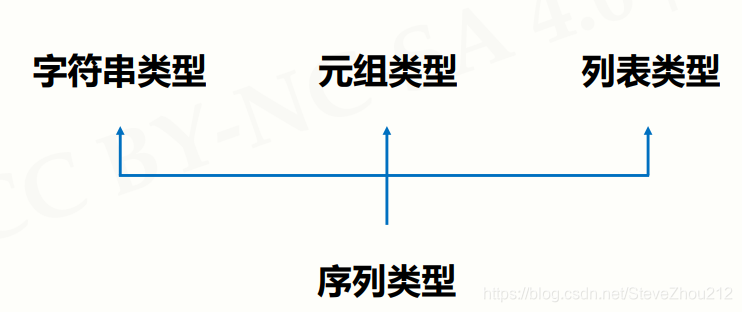

2.序列处理函数及方法

示例:
>>> ls = ["python", 123,
".io"]
>>> ls[::-1]
['.io', 123, 'python']
>>> s = "python123.io"
>>> s[::-1]
'oi.321nohtyp'

示例:
>>> ls = ["python", 123, ".io"]
>>> len(ls)
3
>>> s = "python123.io"
>>> max(s)
'y'
3.元组类型及操作
(1)元组类型定义:元组是序列类型的一种扩展
- 元组是一种序列类型,一旦创建就不能被修改
- 使用小括号 () 或 tuple() 创建,元素间用逗号 , 分隔
- 可以使用或不使用小括号
-示例:
>>> creature = "cat", "dog","tiger","human"
>>> creature
('cat', 'dog', 'tiger', 'human')
>>> color = (0x001100, "blue", creature)
>>> color
(4352, 'blue', ('cat', 'dog', 'tiger', 'human'))
(2)元组类型操作:元组继承序列类型的全部通用操作
- 元组继承了序列类型的全部通用操作
- 元组因为创建后不能修改,因此没有特殊操作
- 使用或不使用小括号
-示例:
>>> creature = "cat", "dog","tiger","human"
>>> creature[::-1]
('human', 'tiger', 'dog', 'cat')
>>> color = (0x001100, "blue", creature)
>>> color[-1][2]
'tiger'
4.列表类型及操作
(1)列表类型定义:列表是序列类型的一种扩展,十分常用
- 列表是一种序列类型,创建后可以随意被修改;
- 使用方括号 [] 或list() 创建,元素间用逗号 , 分隔;
- 列表中各元素类型可以不同,无长度限制;
-示例:
>>> ls = ["cat", "dog","tiger", 1024]
>>> ls
['cat', 'dog', 'tiger', 1024]
>>> lt = ls
>>> lt
['cat', 'dog', 'tiger', 1024]
方括号 [] 真正创建一个列表,赋值仅传递引用
(3)列表类型操作函数和方法:
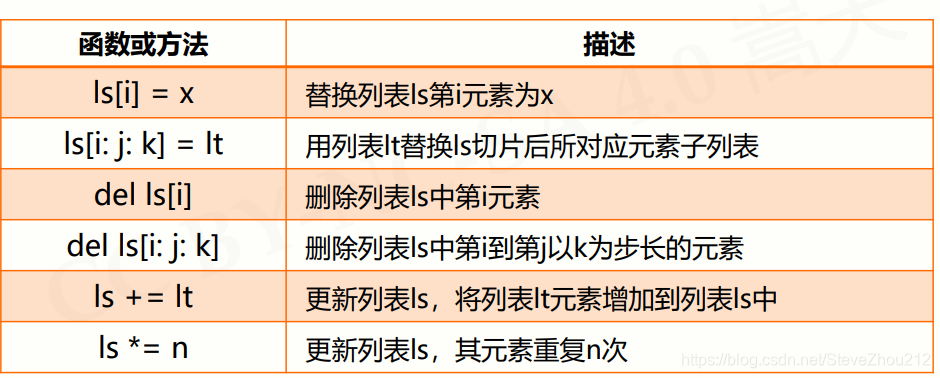
示例:
>>> ls = ["cat", "dog","tiger", 1024]
>>> ls[1:2] = [1, 2, 3, 4]
['cat', 1, 2, 3, 4, 'tiger', 1024]
>>> del ls[::3]
[1, 2, 4, 'tiger']
>>> ls*2
[1, 2, 4, 'tiger', 1, 2, 4, 'tiger']
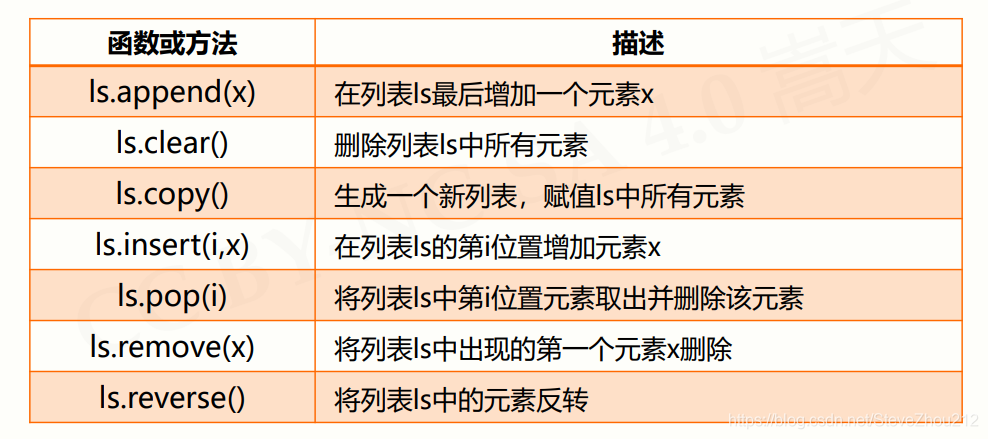
示例:
>>> ls = ["cat", "dog","tiger", 1024]
>>> ls.append(1234)
['cat', 'dog', 'tiger', 1024, 1234]
>>> ls.insert(3, "human")
['cat', 'dog', 'tiger', 'human', 1024, 1234]
>>> ls.reverse()
[1234, 1024, 'human', 'tiger', 'dog', 'cat']
列表功能汇总:
定义空列表lt
向lt新增5个元素
修改lt中第2个元素
向lt中第2个位置增加一个元素
从lt中第1个位置删除一个元素
删除lt中第1-3位置元素
判断lt中是否包含数字0
向lt新增数字0
返回数字0所在lt中的索引
lt的长度
lt中最大元素
清空lt


5.序列类型应用场景
数据表示:元组 和 列表
- 元组用于元素不改变的应用场景,更多用于固定搭配场景
- 列表更加灵活,它是最常用的序列类型
- 最主要作用:表示一组有序数据,进而操作它们
- (1)元素遍历:
-
(2)数据保护: - 如果不希望数据被程序所改变,转换成元组类型
- 示例:
>>> ls = ["cat", "dog","tiger", 1024]
>>> lt = tuple(ls)
>>> lt
('cat', 'dog', 'tiger', 1024)
三, 字典类型及操作
1. 字典类型定义
理解“映射”:
- 映射是一种键(索引)和值(数据)的对应



(1)字典类型是“映射”的体现 - 键值对:键是数据索引的扩展
- 字典是键值对的集合,键值对之间无序
- 采用大括号{}和dict()创建,键值对用冒号: 表示
{<键1>:<值1>, <键2>:<值2>, … , <键n>:<值n>}
(2)在字典变量中,通过键获得值
<字典变量> = {<键1>:<值1>, … , <键n>:<值n>}
<值> = <字典变量>[<键>]
<字典变量>[<键>] = <值>
[ ] 用来向字典变量中索引或增加元素
>>> d = {"中国":"北京", "美国":"华盛顿", "法国":"巴黎"}
>>> d
{'中国': '北京', '美国': '华盛顿', '法国': '巴黎'}
>>> d["中国"]
'北京'
>>> de = {} ; type(de)
<class 'dict'>
2.字典处理函数及方法
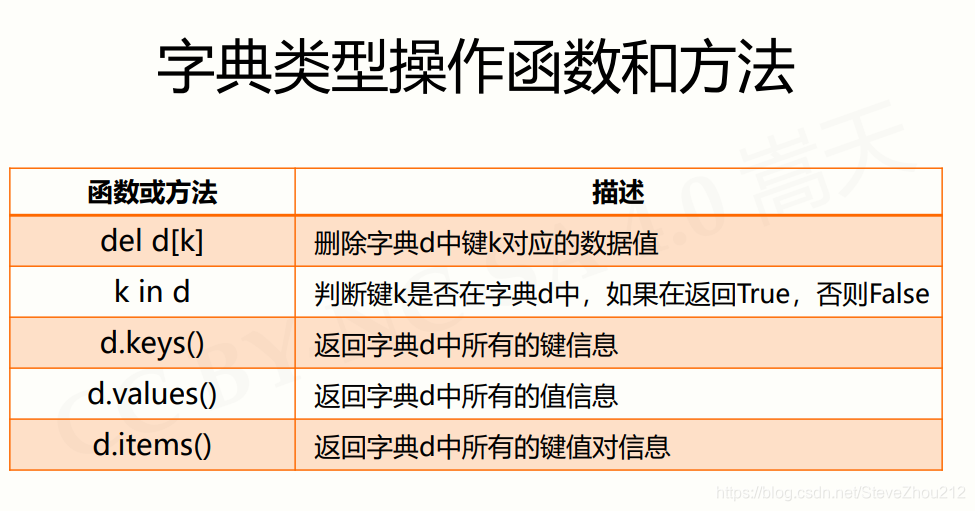
>>> d = {"中国":"北京", "美国":"华盛顿", "法国":"巴黎"}
>>> "中国" in d
True
>>> d.keys()
dict_keys(['中国', '美国', '法国'])
>>> d.values()
dict_values(['北京', '华盛顿', '巴黎'])

>>> d = {"中国":"北京", "美国":"华盛顿", "法国":"巴黎"}
>>> d.get("中国","伊斯兰堡")
'北京'
>>> d.get("巴基斯坦","伊斯兰堡")
'伊斯兰堡'
>>> d.popitem()
('美国', '华盛顿')

3. 字典类型应用场景
映射的表达
- 映射无处不在,键值对无处不在
- 例如:统计数据出现的次数,数据是键,次数是值
- 最主要作用:表达键值对数据,进而操作它们
元素遍历
for k in d :
<语句块>
4.拓展(转载至其他博客):
列表排序的常见排序方法
向字典添加键值对,并统计出现次数的方法
四,jieba库的使用
1.jieba库基本介绍:
(1)jieba是优秀的中文分词第三方库
- 中文文本需要通过分词获得单个的词语
- jieba是优秀的中文分词第三方库,需要额外安装
- jieba库提供三种分词模式,最简单只需掌握一个函数
-jieba分词的原理
(2)jieba分词依靠中文词库 - 利用一个中文词库,确定中文字符之间的关联概率
- 中文字符间概率大的组成词组,形成分词结果
- 除了分词,用户还可以添加自定义的词组
2.jieba库的安装
(cmd命令行) pip install jieba
和一般的第三方库安装过程一样,只是pip命令对应的是jieba相关;
3.jieba库使用说明
jieba分词的三种模式
精确模式、全模式、搜索引擎模式
- 精确模式:把文本精确的切分开,不存在冗余单词
- 全模式:把文本中所有可能的词语都扫描出来,有冗余
- 搜索引擎模式:在精确模式基础上,对长词再次切分


jieba分词要点
jieba.lcut(s)
4.拓展(转载至其他博客):
jieba库的用法
五,实例
1.基本统计值计算:
def getnumber(): #输入用户所需的数据(不确定长度输入)num=[]inum=input("请输入数字(回车退出):")while inum !="":num.append(eval(inum))inum=input("请输入数字(回车退出):")return num
def mean(numbers): #计算平均值s=0.0for num in numbers:s=s+numreturn s/len(numbers)
def dev(numbers,mean): #计算方差sdev=0.0for num in numbers:sdev=sdev+(num-mean)**2return pow(sdev/(len(numbers)-1),0.5)
def median(numbers): #计算中位数sorted(numbers)size=len(numbers)if size%2==0:med =(number[size//2-1]+number[size//2])/2else:med=numbers[size//2]return med
n=getnumber()
m=mean(n)
print("平均值:{},方差:{:.2},中位数:{}.".format(m,dev(n,m),median(n)))'''
sorted()函数对括号内进行排序;'''
'''
基本统计值:总个数,求和,平均值,方差,中位数等;
'''
2.文本词频统计:
(本实例需要自己找到对应的.txt文本,用中英文两个版本来进行举例)
(1)英文文本:Hamet
(分析文本中的词频)
Hamet.txt 下载链接,建议复制保存
def getText():#获得文本信息txt=open("hamlet.txt","r").read()txt=txt.lower()for ch in '!"#$%&()*_+/:;,.<>=?@[\\]^{|}~':txt=txt.replace(ch," ")return txthamletTxt=getText()
words=hamletTxt.split()#采用空格,将元素分开,返回列表类型
counts={}
for word in words:counts[word]=counts.get(word,0)+1#遍历字符串,使得向空字典中新增加键值对,并统计出现次数;
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)#排序完将保留在item变量中;
print("{0:<10}{1:>5}".format('词','统计数量'))
for i in range(10):word,count=items[i]print("{0:<10}{1:>5}".format(word,count))
运行效果:

(2)中文文本:《三国演义》
(分析文本中的人物)
《三国演义》文本下载,建议复制保存
1)基础版:
import jieba
txt=open("三国演义.txt","r",encoding="utf-8").read()
words=jieba.lcut(txt)
counts={}
for word in words:if len(word)==1:continueelse:counts[word]=counts.get(word,0)+1
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(15):word,count=items[i]print("{0:<10}{1:>5}".format(word,count))2)进阶版:
import jieba
excludes = {"将军","却说","荆州","二人","不可","不能","如此","主公","军士","商议"}
txt = open("三国演义.txt", "r", encoding='utf-8').read()
words = jieba.lcut(txt)
counts = {}
for word in words:if len(word) == 1:continueelif word == "诸葛亮" or word == "孔明曰":rword = "孔明"elif word == "关公" or word == "云长":rword = "关羽"elif word == "玄德" or word == "玄德曰":rword = "刘备"elif word == "孟德" or word == "丞相":rword = "曹操"else:rword = wordcounts[rword] = counts.get(rword,0) + 1
for word in excludes:del counts[word]
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
for i in range(10):word, count = items[i]print ("{0:<10}{1:>5}".format(word, count))最后,文中如有不足,欢迎批评指正!
后面也会更新文章的内容,多多关注和点赞啊!
这篇关于1.7Python组合数据类型及jieba库分词的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



