本文主要是介绍jieba安装和使用教程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- jieba安装
- 自定义词典
- 关键词提取
- 词性标注
jieba安装
pip install jieba
jieba常用的三种模式:
- 精确模式,试图将句子最精确地切开,适合文本分析;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
可使用 jieba.cut 和 jieba.cut_for_search 方法进行分词,两者所返回的结构都是一个可迭代的 generator,可使用 for 循环来获得分词后得到的每一个词语(unicode),或者直接使用 jieba.lcut 以及 jieba.lcut_for_search 返回 list。
jieba.Tokenizer(dictionary=DEFAULT_DICT) :使用该方法可以自定义分词器,可以同时使用不同的词典。jieba.dt 为默认分词器,所有全局分词相关函数都是该分词器的映射。
jieba.cut 和 jieba.lcut 可接受的参数如下:
- 需要分词的字符串(
unicode或UTF-8字符串、GBK字符串) cut_all:是否使用全模式,默认值为FalseHMM:用来控制是否使用HMM模型,默认值为Truejieba.cut_for_search和jieba.lcut_for_search接受 2 个参数:
import jiebawords = '今天哪里都没去,在家里睡了一天'
# 全匹配
seg_list = jieba.cut(words, cut_all=True)
print(list(seg_list))# 精确匹配 默认模式
seg_list = jieba.cut(words, cut_all=False)
print(list(seg_list)) # 精确匹配
seg_list = jieba.cut_for_search(words)
print(list(seg_list))
['今天', '哪里', '都', '没去', ',', '在家', '家里', '睡', '了', '一天']
['今天', '哪里', '都', '没', '去', ',', '在', '家里', '睡', '了', '一天']
['今天', '哪里', '都', '没', '去', ',', '在', '家里', '睡', '了', '一天']
自定义词典
add_word方法加载
jieba.add_word():向自定义字典中添加词语
# 添加自定义词典text = "我喜欢C++语言编程很有趣"
print(jieba.lcut(text))jieba.add_word("C++语言")# 打印分词结果
print(jieba.lcut(text))
load_userdict方法加载
sent = "你认为人工智能、机器学习和深度学习的关系是什么?"print("添加前:",jieba.lcut(sent))jieba.load_userdict('dict.txt')
print("添加后:",jieba.lcut(sent))
添加前: ['你', '认为', '人工智能', '、', '机器', '学习', '和', '深度', '学习', '的', '关系', '是', '什么', '?']
添加后: ['你', '认为', '人工智能', '、', '机器学习', '和', '深度学习', '的', '关系', '是', '什么', '?']
关键词提取
可以基于 TF-IDF 算法进行关键词提取,也可以基于TextRank 算法。 TF-IDF 算法与 elasticsearch 中使用的算法是一样的。
- 使用
jieba.analyse.extract_tags()函数进行关键词提取,其参数如下:
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
sentence为待提取的文本topK为返回几个TF/IDF权重最大的关键词,默认值为20withWeight为是否一并返回关键词权重值,默认值为FalseallowPOS仅包括指定词性的词,默认值为空,即不筛选jieba.analyse.TFIDF(idf_path=None)新建TFIDF实例,idf_path为IDF频率文件- 也可以使用
jieba.analyse.TFIDF(idf_path=None)新建TFIDF实例,idf_path为IDF频率文件。
content = "十里洋场,雪月风花。形色男女往来穿梭,追逐着名利,追逐梦想,追随着心底无尽的欲望。一曾名不见经传的小青年阿宝(胡歌 饰),为了实现发财致富梦拜在老法师爷叔(游本昌 饰)门下,随后便于一众亲信驰骋股市,盆满钵圆,眼见得起了高楼,平步青云。不满足股市的狂欢冒险,宝总转身投入商界,他和27号的汪小姐(唐嫣 饰)互惠合作,彼此信赖;和青梅竹马的铃子(马伊琍 饰)合开餐厅,互为表里;与初来乍到的至真园老板娘李李(辛芷蕾 饰)往来试探,暗流涌动。人头攒动,熙熙攘攘的黄河路有如大上海的缩影,上演了几多悲欢离合,阴晴圆缺。"import jieba.analysetopK = 6# 使用tf-idf算法提取关键词
tags = jieba.analyse.extract_tags(content, topK=topK)
print(tags)# 使用textrank算法提取关键词
tags2 = jieba.analyse.textrank(content, topK=topK)# withWeight=True:将权重值一起返回
tags = jieba.analyse.extract_tags(content, topK=topK, withWeight=True)
print(tags)
print(tags2)
['追逐', '往来', '阿宝', '十里洋场', '马伊', '阴晴圆']
[('追逐', 0.2082690959655263), ('往来', 0.19066413951605263), ('阿宝', 0.17378329567631579), ('十里洋场', 0.1684482284644737), ('马伊', 0.1684482284644737), ('阴晴圆', 0.1684482284644737)]
['追逐', '信赖', '股市', '上海', '冒险', '转身']
词性标注
词性标注主要是标记文本分词后每个词的词性。
import jieba.posseg as pseg# 默认模式
sent1 = "今天哪里都没去,在家里睡了一天"
print(sent1)
seg_list = pseg.cut(sent1)
for word, flag in seg_list:print(word + " " + flag)# paddle 模式
sent2 = "我今天吃早饭了"
print(sent2)
words = pseg.cut(sent2,use_paddle=True)
for word, flag in words:print(word + " " + flag)
今天哪里都没去,在家里睡了一天
今天 t
哪里 r
都 d
没去 v
, x
在 p
家里 s
睡 v
了 ul
一天 m
我今天吃早饭了
我 r
今天 t
吃 v
早饭 n
了 ul
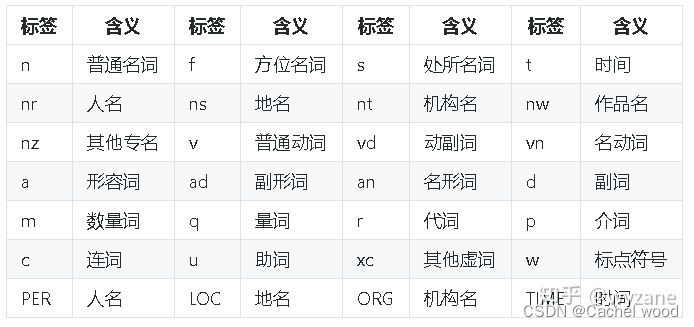
paddle模式的词性对照表如下
这篇关于jieba安装和使用教程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







