本文主要是介绍中文分词,c++应用,想到jieba分词,结果还的自己封装。探索中,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、研究背景
随着互联网的快速发展,信息也呈了爆炸式的增长趋势。在海量的信息中,我们如何快速抽取出有效信息成为了必须要解决的问题。由于信息处理的重复性,而计算机又善于处理机械的、重复的、有规律可循的工作,因此自然就想到了利用计算机来帮助人们进行处理。在用计算机进行自然语言处理时,主要使用的还是基于统计的方法,并且实际的使用中取得了不错的效果。
因为中文句子的特点——没有分隔符来分离句子中的词,所以在进行中文处理的时候,首先要做的就是如何对中文语句进行分词。这也是本次工程所要实现的功能。
在这个工程中,实现的是一个分词系统。系统的主要的内容就是建立隐马尔科夫模型,用《人民日报语料库》进行训练得到模型参数,然后再用维特比算法求出最可能的隐含序列,最后将输入的句子分成一个个词的形式。
二、模型方法
本工程主要使用的是隐马尔科夫模型和维特比算法。
隐马尔科夫模型是一个统计模型,它可以用一个5元组来表示:{S,O,π,A,B}。下面对隐马尔科夫模型的五元组的学术含义和工程含义进行说明,通过对比直观的了解五元组在实际工程中的含义:
| HMM五元素 | 学术含义 | 工程含义 |
| S | 隐含转态 | 词中4种状态:词头、词中、词尾、单字成词 |
| O | 观察状态 | 语料库中的全部汉字 |
| π | 初始状态概率矩阵 | 各种隐含状态的初始概率 |
| A | 隐含状态转移概率矩阵 | 4种隐含状态的转移概率 |
| B | 观察状态转移概率矩阵 | 每一个汉字到四种状态的概率 |
在本工程中,为每个汉字设置了可能的四种状态:词头([/B]Begin)、词中([/M]Middle)、词尾([/E]End)和单字成词([/S]Single)。
根据设置的状态,举个例子说明五个参数:
假设输入的语句为:我是中国人
S={/B、/M、/E、/S}
O={迈、向、新、充、满、……}(语料库中的所有不重复汉字)
π={P(我|B)、P(我|M)、P(我|E)、P(我|S)}
A=
| /B | /M | /E | /S | |
| /B | 0 | 0.3 | 0.7 | 0 |
| /M | … | … | … | … |
| /E | … | … | … | … |
| /S | … | … | … | … |
B=
| 我 | 是 | 中 | 国 | 人 | |
| /B | 0.3 | … | |||
| /M | … | … | … | ||
| /E | … | 0.6 | |||
| /S | … | … |
上述涉及到的概率均可从语料库中根据统计得到。
三、系统设计
本分词系统主要分为两个部分,一个部分是通过语料库训练出需要的文件。该部分只要执行一次即可。另一个部分是根据输入的语句,构建具体的模型参数(通过上面也可以看到,根据具体输入得到对应的概率),然后执行维特比算法求出最佳的隐含状态序列。根据隐含状态序列得到最终的分词结果。
系统的开发语言是C++。C++在处理中文方面显得有点不方便——表示英文字符时用的是一个字节,表示中文时用的是两个字节(可以通过判断字符是否小于0来分出是ASCII字符还是中文字符)。但是最后还是通过一些技巧解决了C++处理中文的不便带来的问题。
1、语料库处理
(1)去掉原语料库中的词性
A、原始语料库如图所示:

B、处理后的语料库(在每行前面加了一个空格并去掉了词性)

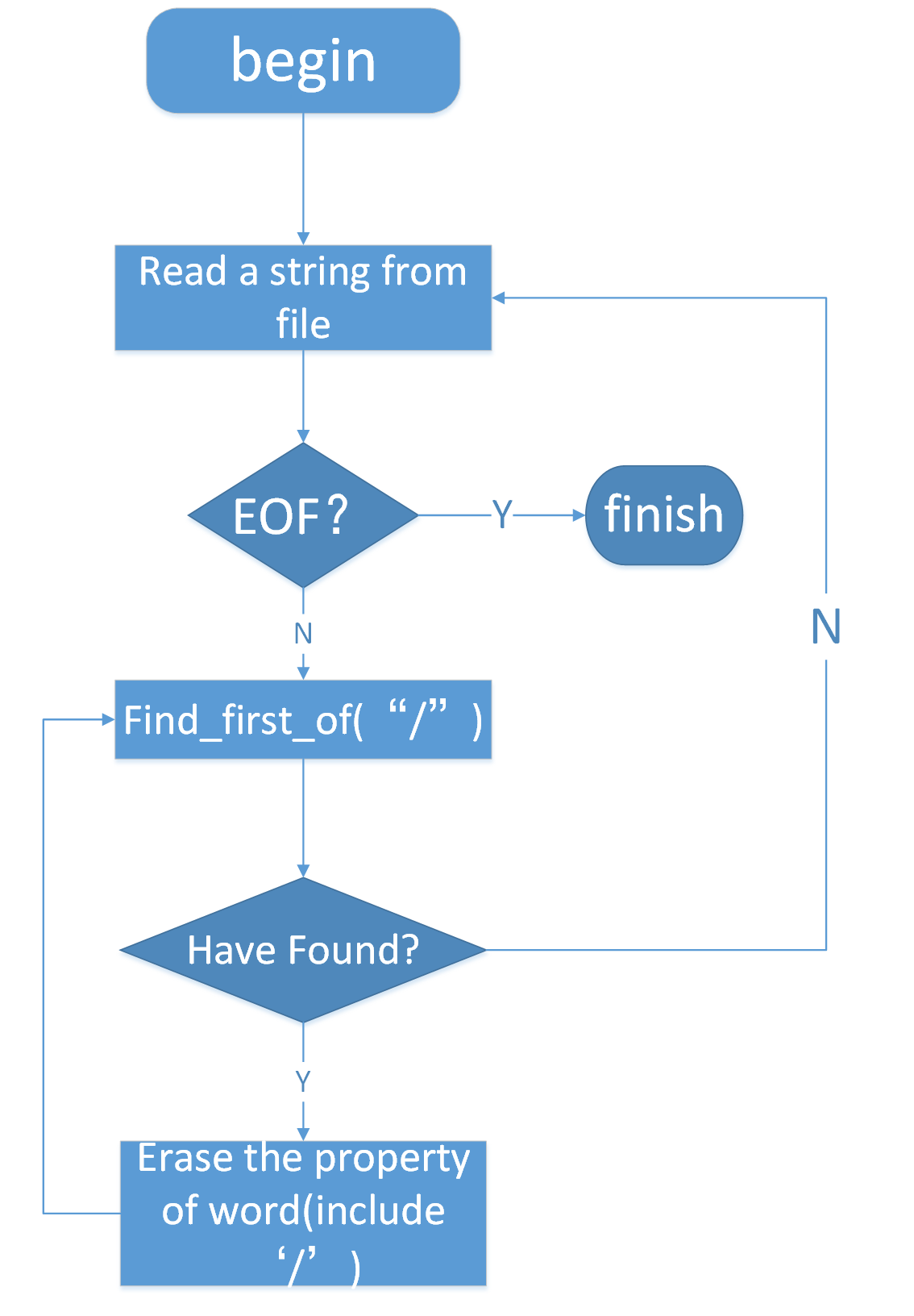
C、处理流程图
(2)统计每个状态中出现的字及其个数
A、设计的数据结构如下:
struct node{string name;//保存单个字int quantity;//字出现的次数bool operator ==(const node & a){return name==a.name;}};struct Word{string name;//状态名long long num;//状态出现次数list<node> chinese;bool operator ==(const Word & a){return name==a.name;}bool findCh(string ch){node temp;temp.name=ch;temp.quantity=1;list<node >::iterator it;it=find(chinese.begin(),chinese.end(),temp);if(it==chinese.end()){chinese.push_back(temp);}else{it->quantity++;}return true;}};
B、处理步骤
a、从语料库读入一行字符串,再遍历字符串获得一个中文字
b、判断字的前后是否是空格,得到字对应的状态(S:前面是空格后面不是;M:前后都不是空格;E:前面不是空格后面是空格;S:前后都是空格)
c、根据字的状态,判断该字是否在该状态下出现过。是,对应字个数加1,否,插入新节点并且个数设置为1)
d、读到文件末尾结束
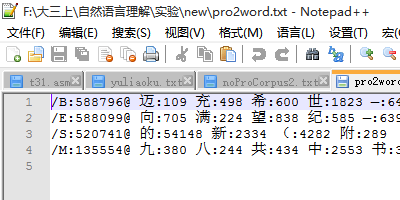
C、结束后得到如下的文件
(3)统计状态间的转换,求得状态转移矩阵
A、统计出各个状态间转换在语料库中出现的次数及状态转换的总次数,计算出对应的概率
B、该步骤的输入语料库如下:

C该过程结束后可以得到4*4的状态转移矩阵
2、viterbi算法解码,求最佳隐含序列
(1)维特比算法是一种动态规划算法。在本工程中,通过当前状态的前一个状态,计算出在前面状态出现的条件下出现当前状态的概率,并取最大值作为当前状态出现的概率。通过迭代可以计算出到最后一个字时,哪个状态出现的概率最大。最后通过回溯得到最佳的隐含状态序列。
(2)算法伪代码如下:

四,系统演示与分析
1、测试样例及结果

2、结果分析
(1)商品和服务->BESBE->商品/和/服务/
(2)中国在比赛中取得了胜利->BESBESBESBE->中国/在/比赛/中/取得/了/胜利/
(3)分词说明:根据维特比算法求得了隐含序列后,顺序输出,当该字是处于E状态或者S状态时,在该字后添加‘/’,输出后即可看到分词的效果。
(4)由于每个字都有一个状态,所以在分词过程中,有可能会把原来是词的分开了,原来不是词的合成了词,造成错误的分词。比如上面的“明天”被拆开了,而“天会”被则被合成起来了。再比如,“和尚”和“尚未”都被分开了,即使词库中有这两个字。
3、改进方案
本工程仅仅依靠HMM实现,因此必然存在一定的缺陷。为了改进该系统,可以结合其他的分词方法,在HMM实现过程中或实现结束后再做进一步分析,以得到更好的分词效果。
五,参考资料
1、http://www.tuicool.com/articles/FRZ77b 利用统计进行中文分词与词性分析
2、基于N最短路径和隐马尔科夫模型的中文POI分词系统的研究 唐霄
3、基于逆向隐马尔可夫模型的中文分词方法研究
4、http://blog.csdn.net/sight_/article/details/43307581 隐马尔科夫模型详解
这篇关于中文分词,c++应用,想到jieba分词,结果还的自己封装。探索中的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





