int4专题

通义千问-VL-Chat-Int4
Qwen-VL 是阿里云研发的大规模视觉语言模型(Large Vision Language Model, LVLM)。Qwen-VL 可以以图像、文本、检测框作为输入,并以文本和检测框作为输出。Qwen-VL 系列模型性能强大,具备多语言对话、多图交错对话等能力,并支持中文开放域定位和细粒度图像识别与理解。 安装要求 (Requirements) python 3.8及以上版本pytor
实战之快速完成 ChatGLM3-6B 在 GPU-8G的 INT4 量化和本地部署
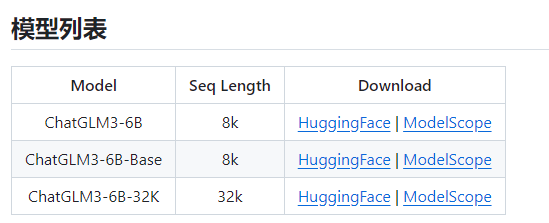
ChatGLM3 (ChatGLM3-6B) 项目地址 https://github.com/THUDM/ChatGLM3 大模型是很吃CPU和显卡的,所以,要不有一个好的CPU,要不有一块好的显卡,显卡尽量13G+,内存基本要32GB+。 清华大模型分为三种(ChatGLM3-6B-Base,ChatGLM3-6B,ChatGLM3-6B-32K) 从上图也可以看到,ChatGLM3-

Windows PC上从零开始部署ChatGML-6B-int4量化模型
引言 ChatGLM-6B是清华大学知识工程和数据挖掘小组(Knowledge Engineering Group (KEG) & Data Mining at Tsinghua University)发布的一个开源的对话机器人。6B表示这是ChatGLM模型的60亿参数的小规模版本,约60亿参数。 ChatGML-6B-int4量化模型是针对ChatGML-6B做的优化版本,占用更少的资源,

通义千问-7B-Chat-Int4
通义千问-7B-Chat-Int4 安装 克隆我们的仓库并跳转到相应目录 git clone https://www.modelscope.cn/qwen/Qwen-7B-Chat-Int4.gitcd Qwen-7B-Chat-Int4 2. 创建 conda 环境 conda create -n qweni

FP16、BF16、INT8、INT4精度模型加载所需显存以及硬件适配的分析
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法行业就业。希望和大家一起成长进步。 本文主要介绍了FP16、INT8、INT4精度模型加载占用显存大小的分析,希望对学
Int4:Lucene 中的更多标量量化
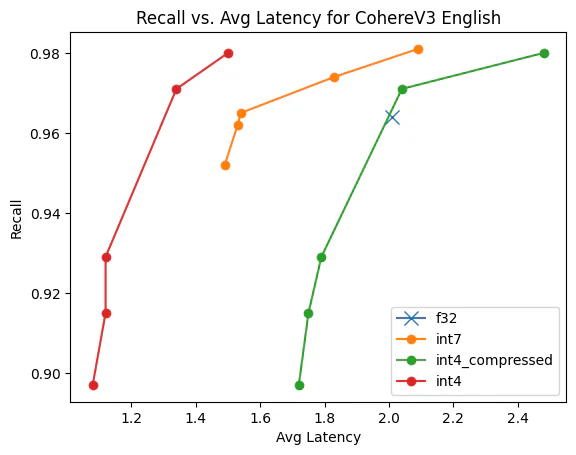
作者:来自 Elastic Benjamin Trent, Thomas Veasey 在 Lucene 中引入 Int4 量化 在之前的博客中,我们全面介绍了 Lucene 中标量量化的实现。 我们还探索了两种具体的量化优化。 现在我们遇到了一个问题:int4 量化在 Lucene 中是如何工作的以及它是如何排列的? 存储量化向量并对其进行评分 Lucene 将所有向量存储在一个

AI大模型量化格式介绍(GPTQ,GGML,GGUF,FP16/INT8/INT4)
在 HuggingFace 上下载模型时,经常会看到模型的名称会带有fp16、GPTQ,GGML等字样,对不熟悉模型量化的同学来说,这些字样可能会让人摸不着头脑,我开始也是一头雾水,后来通过查阅资料,总算有了一些了解,本文将介绍一些常见的模型量化格式,因为我也不是机器学习专家,所以本文只是对这些格式进行简单的介绍,如果有错误的地方,欢迎指正。 What 量化 量化在 AI 模型中,特别是在深度
![[大模型]Qwen1.5-7B-Chat-GPTQ-Int4 部署环境](https://img-blog.csdnimg.cn/direct/b8c9ed143e85437fbbad7832cc8b3b8a.png#pic_center)
[大模型]Qwen1.5-7B-Chat-GPTQ-Int4 部署环境
Qwen1.5-7B-Chat-GPTQ-Int4 部署环境 说明 Qwen1.5-72b 版本有BF16、INT8、INT4三个版本,三个版本性能接近。由于BF16版本需要144GB的显存,让普通用户忘却止步,而INT4版本只需要48GB即可推理,给普通用户本地化部署创造了机会。(建议使用4×24G显存的机器) 但由于Qwen1.5-72B-Chat-GPTQ-Int4其使用了GPTQ量化
Windows环境下搭建chatGLM2-6B-int4量化版模型(图文详解-成果案例)
目录 一、ChatGLM2-6介绍 二、环境准备 1. 硬件环境 2. TDM-GCC安装 3.git安装 4.Anaconda安装 三、模型安装 1.下载ChatGLM2-6b和环境准备 方式一:git命令 方式二:手动下载 2.下载预训练模型 在Hugging Face HUb下载(挂VPN访问) (1)git命令行下载: (2)手动下载(建议) 3.模型使用(
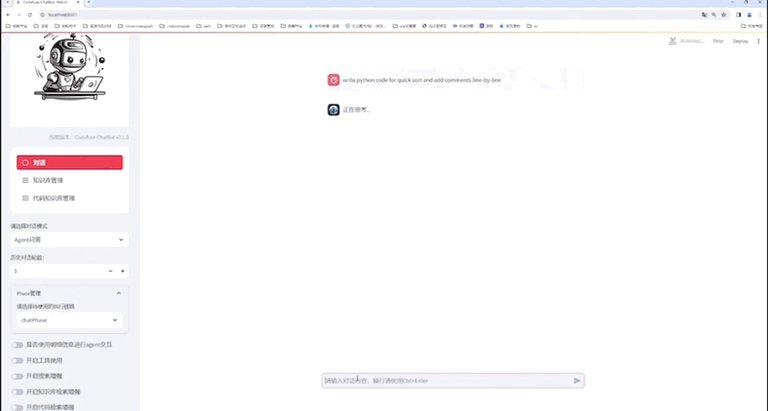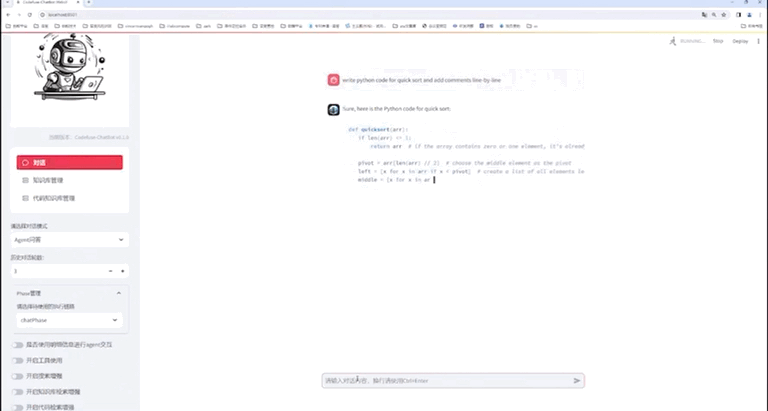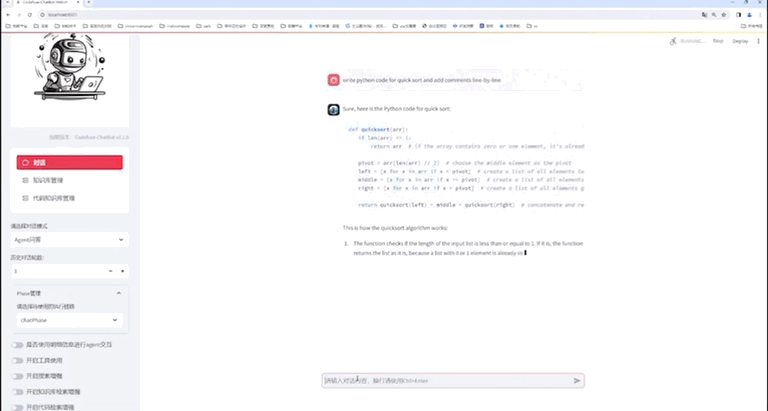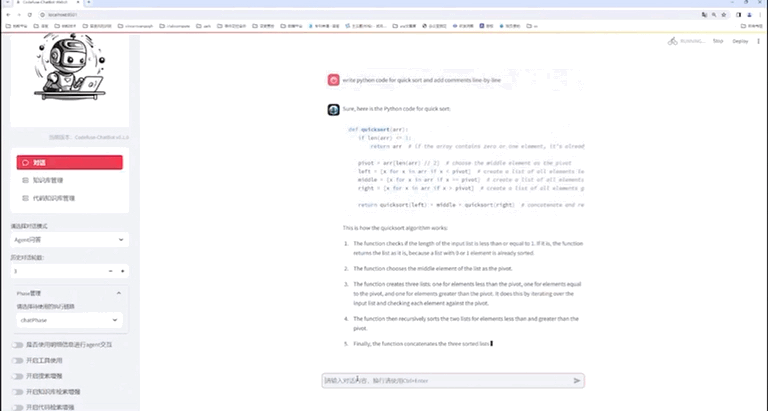
使用NVIDIA TensorRT-LLM支持CodeFuse-CodeLlama-34B上的int4量化和推理优化实践
本文首发于 NVIDIA 一、概述 CodeFuse(https://github.com/codefuse-ai)是由蚂蚁集团开发的代码语言大模型,旨在支持整个软件开发生命周期,涵盖设计、需求、编码、测试、部署、运维等关键阶段。 为了在下游任务上获得更好的精度,CodeFuse 提出了多任务微调框架(MFTCoder),能够解决数据不平衡和不同收敛速度的问题。 通过

使用autodl服务器,在A40显卡上运行, Yi-34B-Chat-int4模型,并使用vllm优化加速,显存占用42G,速度18 words/s
1,演示视频 https://www.bilibili.com/video/BV1gu4y1c7KL/ 使用autodl服务器,在A40显卡上运行, Yi-34B-Chat-int4模型,并使用vllm优化加速,显存占用42G,速度18 words/s 2,关于A40显卡,48GB 显存,安培架构 2020年,英伟达发布 A40 专业显卡,配备 48GB 显存。 采用了