hpc专题

新一代车载(E/E)架构下的中央计算载体---HPC软件架构简介
老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 屏蔽力是信息过载时代一个人的特殊竞争力,任何消耗你的人和事,多看一眼都是你的不对。非必要不费力证明自己,无利益不试图说服别人,是精神上的节能减排。 无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事.而不是让内心的烦躁、焦虑、毁掉你本就不多的热情和定力。 时间不知不觉中,快要来到夏末秋初。一年又过去了一大半,成

HPC集群是什么?百度智能云CHPC给出答案
高性能计算(HPC)集群指运行高性能计算的节点集合,一个 HPC 集群可能包含数十到数千台计算节点。HPC 集群可以提供单节点不能提供的强大计算能力,拥有高性能、弹性扩展、稳定可靠等优点。HPC集群能够提供远超单个计算机的处理能力,因此非常适合需要大量计算资源和数据处理的任务。 本文将简单介绍集群涉及的基本概念和百度智能云 CHPC 的功能。 一. 集群类型 集群可以根据其部署和管理方式

飞速(FS)InfiniBand解决方案构建HPC网络
面对HPC领域的不断发展,未来HPC业务核心在于HPC网络和基础设施。随着高性能计算应用的复杂性和数据量的增长,对弹性、可扩展和高效网络的需求变得日益迫切。HPC网络架构作为HPC系统运行的基础,在数据处理、管理和大规模存储方面至关重要。本文详细探讨了飞速(FS)HPC网络架构关键组成部分,阐述HPC数据中心网络的优势,并深入介绍飞速(FS)针对高性能计算(HPC)网络架构不同分区提供的全面解决方

【HPC】MIC和GPU在高性能计算中的使用
******************************************************************** ** 欢迎转发,注明原文:blog.csdn.net/clark_xu 徐长亮的专栏 ** 谢谢您的支持,欢迎关注微信公众号:clark_blog *************************************************

HPC: perf入门
如果你想查看你的程序在cpu上运行时,耗时时如何分布的,那么perf是一个合理的选择。 准备工作 为了支持使用perf,首先你要安装相关的库 sudo apt install linux-tools-5.15.0-67-generic 此外,因为使用perf进行benchmark, 涉及到一些系统权限,所以,你还需要修改权限,将下面文档中对应的参数改为-1 vim /proc/sys/
解决方案:昇腾aarch64服务器安装CUDA+GCC+CMake,编译安装Pytorch,华为昇腾HPC服务器深度学习环境安装全流程
目录 一、安装CUDA和cudnn1.1、下载CUDA驱动1.2、安装CUDA驱动1.3、配置环境变量1.4、安装cudnn1.5、安装magma-cuda 二、安装gcc编译器三、安装CMake四、安装NCCL五、编译安装Pytorch5.1、前提准备5.2、下载pytorch源码5.3、配置环境变量5.4、Pytorch编译安装5.5、测试Pytorch 特别鸣谢以下博客 最近

IC设计企业致力于解决的HPC数据防泄漏,到底该怎么做?
对于半导体IC设计企业来说,芯片设计、验证、仿真使用HPC环境现在已逐渐成为趋势,主要原因在于原来的工作流程存在较多的缺陷: 性能瓶颈:仿真、设计、验证、生产过程中,前端仿真需要小文件高并发低时延的读写和巨量元数据处理能力,后端仿真存储需要提供很大的读写带宽满足大量数据的实时写入要求。 周期长:整个芯片设计流程非常长,一颗芯片的时间从数月到数年不止,仿真、设计流程耗时,芯片的上市周期是赢得
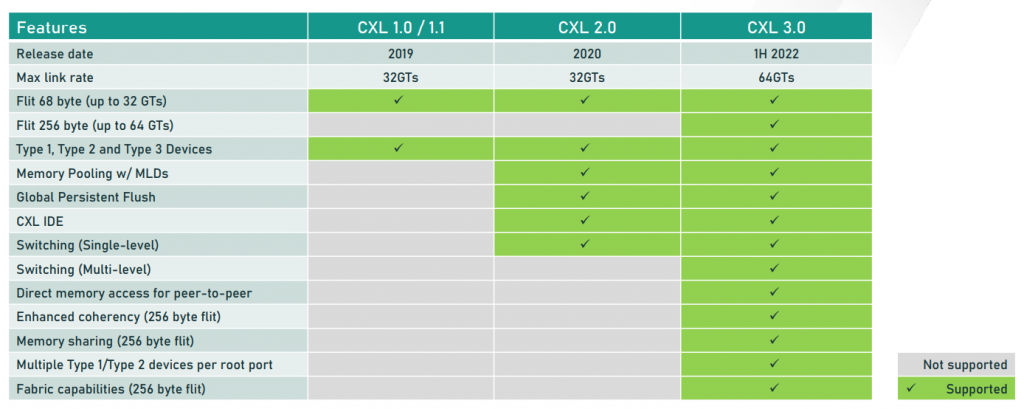
数据中心、HPC、AI等应用场景互联协议混战哪家强?
生成式人工智能快速发展对算力与存力呈指数需求增长,进一步加剧了算力与存力之间既有矛盾,时代在呼唤更大的运力(即计算与存储之间的数据传输)--AIGC时代需要更大带宽,更为快速的数据传输路径。 众所周知,PCIE是目前所知最为常见的高性能I/O通信协议,但受限于PCIE总线的树形拓扑以及有限的设备标识ID号码范围,致使其无法形成一个大规模网络。尤其在NVMe大规模使用时占用大量的PCIe线路,
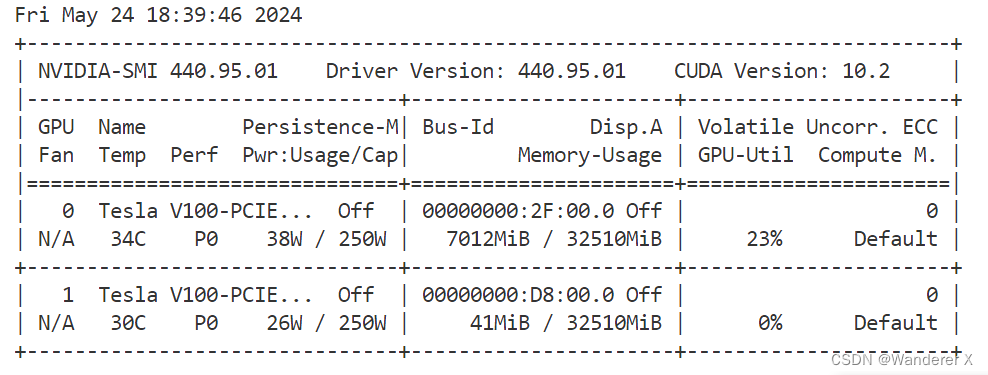
hpc中查看显存占用,等效nvidia-smi
nvidia-smi在hpc中无法使用, 但是可以通过以下方法查看应用程序占用的显存 先执行程序,之后 bjobs 输出 可以看到使用的是gpu01节点 之后 ssh gpu01

5款采用AMD Instinct MI300芯片的超酷AI和HPC服务器
我们收集了戴尔科技、联想、超微和技嘉的五款超酷人工智能和高性能计算服务器,这些服务器使用 AMD 的 Instinct MI300 芯片,该芯片于几个月前推出,旨在挑战 Nvidia 在人工智能计算领域的主导地位。 AMD 正在凭借其 Instinct MI300 加速器芯片向 Nvidia 在人工智能计算领域的主导地位发起迄今为止最大的挑战。推出几个月后,多款 MI300 服务器现已上

想看明白太湖之光处理器HPC系统么?
基于国产申威CPU的国产HPC系统最近登顶HPC TOP500。看看新闻赞叹一下之余,是不是总得获取点营养才行?怎么获取?关注大话存储公众号啊。 冬瓜哥留意到, 那些之前看过冬瓜哥“【冬瓜哥手绘】大话众核心处理器体系结构”这篇文章的朋友们,在一些群里可以非常愉快的装逼,并且开始给人布道了,讲述申威这套体系的结构。而那些认为“平时看冬瓜哥这么深刻文章有

高性能计算(HPC)和智能计算理解
1.现代终端设备一般都跟云端服务器相连,但只要可能,我们都希望计算可以在本地终端解决,这样做的好处是多方面的:既可以减小网络带宽的压力,又可以避免网络传输产生的时延,还可以让用户的数据更安全。现代终端设备一般用一个片上系统 (SoC)做计算,上面部署了通用的CPU和集成显卡。对于日益增多的卷积神经网络推理计算来说,在移动端的CPU(多数ARM,少数x86)上虽然优化实现相对简单(参见我们对CPU的
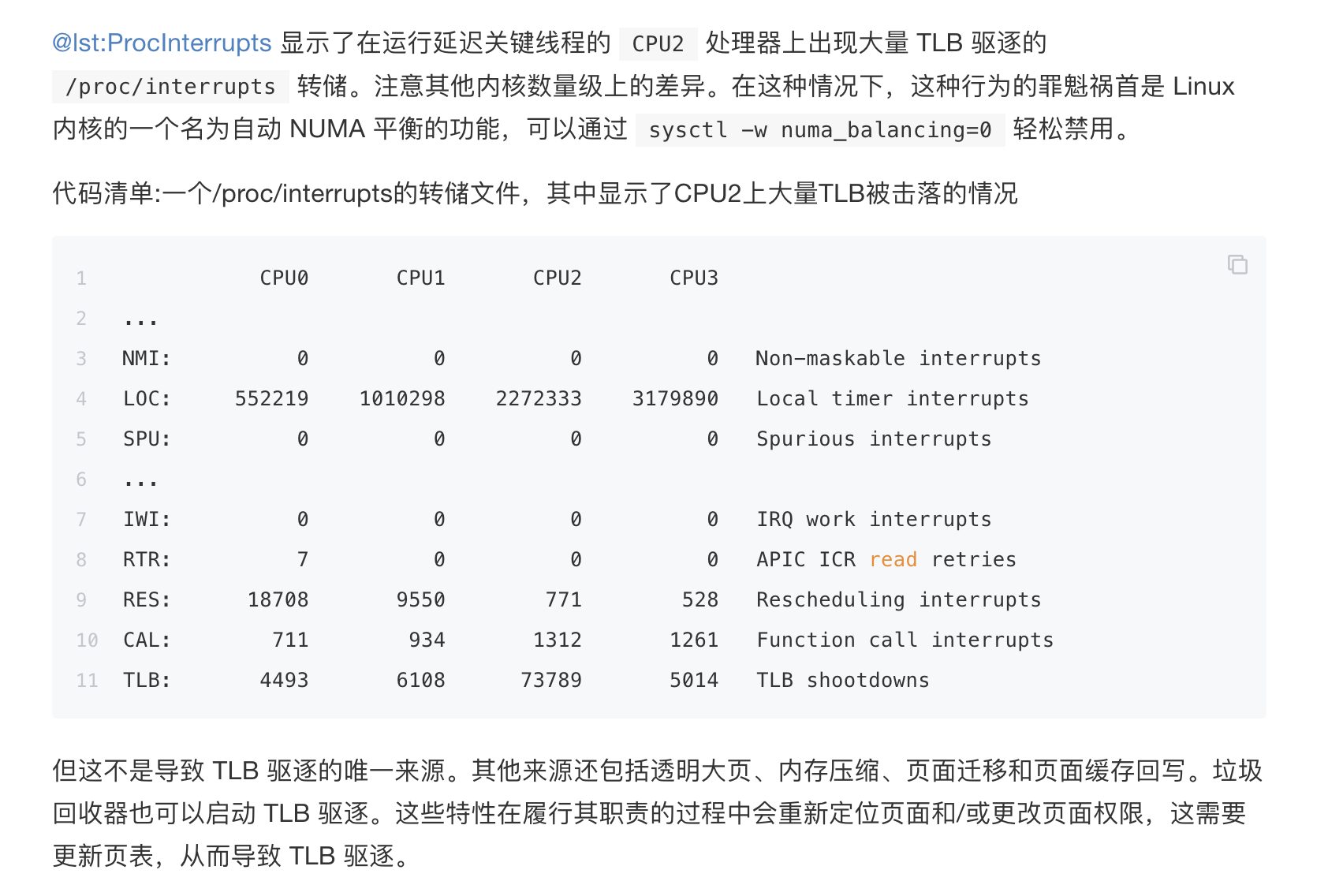
HPC -- 基础理论
面九坤的时候被会HPC的面试官吊打了,九坤的面试官给了一个评价:能进面的是合格的程序员,会HPC的才是优秀的程序员。 我对于HPC的了解只有https://www.yuque.com/treblez/qksu6c/nqe8ip59cwegl6rk?singleDoc# 《从微架构到向量化–CPU性能优化指北》这么多,还是要深入学习一下。 本文是https://en.algorithmica.org
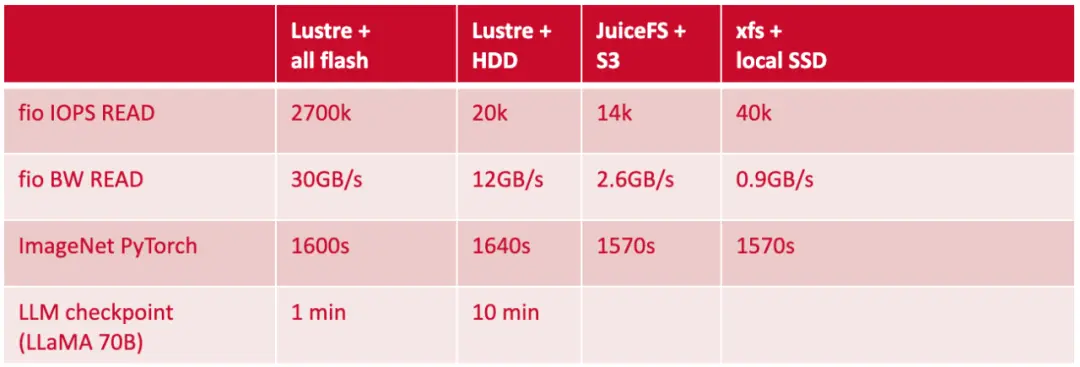
从 HPC 到 AI:探索文件系统的发展及性能评估
随着 AI 技术的迅速发展,模型规模和复杂度以及待处理数据量都在急剧上升,这些趋势使得高性能计算(HPC)变得越来越必要。HPC 通过集成强大的计算资源,比如 GPU 和 CPU 集群,提供了处理和分析大规模数据所需的算力。 然而,这也带来了新的挑战,尤其是在存储系统方面,包括如何有效处理大量数据、确保数据访问的高效性以及如何控制成本和运维管理。分布式文件系统,作为一种高成本效益高的解决方案,正
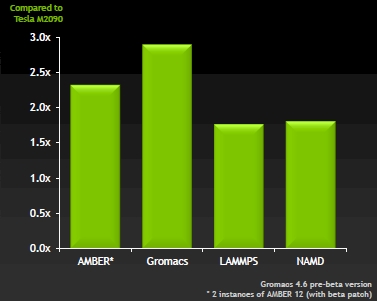
linux驱动K10运算卡,GPU推动HPC普及,Tesla K10性能揭秘
拼 命 加 载 中 ... 这两天时值国际超级计算大会,Intel推出了MIC多核架构的商品化品牌Xeon Phi,NVIDIA作为GPU计算阵营的代表也没闲着,也向公众展示了GPU计算在HPC领域的成就,并首次公开了Tesla K10的性能。 Top500的性能排名是基于Linpack Fortran矩阵数学测试而来的,这是一种双精度运算,不过实际应用中基于单精度的运算依然占相当大比例,这正是
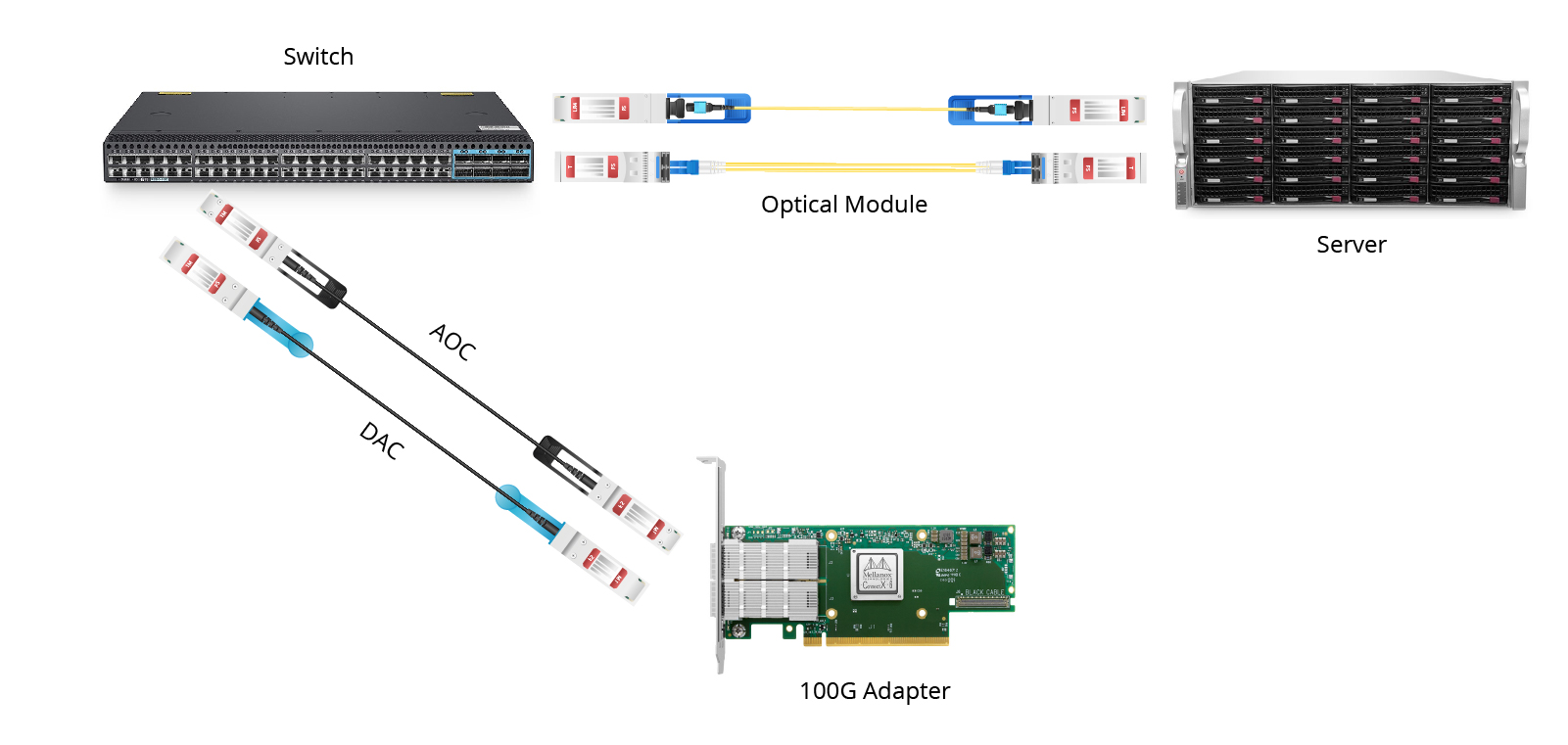
数据中心在高性能计算(HPC)中的作用
高性能计算(HPC)已成为解决复杂问题、推动科学研究、人工智能和其他各种应用领域的关键工具。要确保高性能计算系统的高效运行,需要专门的基础设施和支持。数据中心在满足高密度计算、管理散热和提供强大带宽方面起着关键作用。本文探讨了数据中心如何支持高性能计算(HPC),重点关注HPC的关键组成部分、冷却设施、必要设备以及选择合适产品的重要性。 高性能计算的应用 高性能计算已成为各个领域中不可
Intel放弃Lustre,停止发行企业版HPC文件系统
作者:孙斌 ZD至顶网 结合此前解散OpenStack研究团队以及取消英特尔开发者论坛的行为,我们似乎发现了一种模式。本文摘自:ZD至顶网。 英特尔选择这样的标题公布Lustre取消事宜 英特尔公司已经决定不再提供自有版本的Lustre文件系统——这套系统专门面向高性能计算场景,能够高效管理跨越庞大Linux集群的超级规模数据存储集合。 英特尔公司技术计算项目(即英特尔旗下的高性能计算
Burst Buffer技术为何在HPC如此盛行
Burst Buffer是什么技术,它跟HPC有什么关系?首先我们一起来了解一个美国超算中心NERSC(国家能源研究科学计算中心),然后通过NERSC超算系统对Burst Buffer的应用来说说Burst Buffer技术。 NERSC一直与Cray(克雷)合作,为Cori (Cori 是 NERSC最新的大型计算系统) 的用户带来Burst Buffer技术。 NERSC Burst B
HPC使用 - 解决source activate无法激活anaconda虚拟环境
问题描述 准备用sh脚本提交任务到HPC,但是发现sh脚本中source activate无法激活anaconda虚拟环境,所以导致一直报错 某些package没有安装。 通过比对package的版本,发现anaconda虚拟环境 其实并没有被激活。 sh脚本代码如下: python -Vconda -Vsource activate your_envpython -Vconda -V


在云计算的另一面,HPC+正在带来新的联想
全国高性能计算学术年会创办于2005年,到2017年已成功举办13届,会议吸引近千人参会,40家科研院所、厂商参展。每次年会围绕高性能计算技术的研究进展与发展趋势、高性能计算的重大应用等主题展开,为相关领域的学者提供交流合作、发布最前沿科研成果的平台,促进信息化与工业化的深度融合,推动中国高性能计算的发展。 2018年10月18日到20日,第十四届全国高性能计算学术年会(HPC Chi
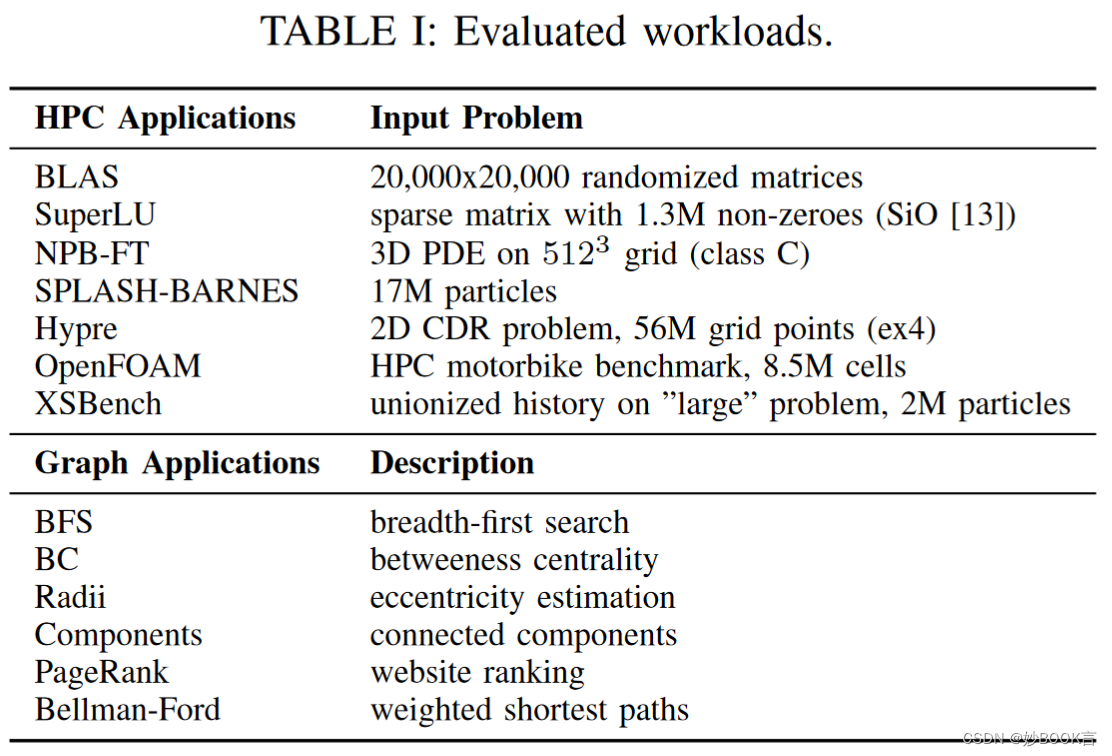
Evaluating Emerging CXL-enabled Memory Pooling for HPC Systems——论文泛读
MCHPC@SC 2022 Paper CXL论文阅读汇总 问题 当前的高性能计算(HPC)系统提供的内存资源是静态配置的,并与计算节点紧密耦合。然而,HPC系统上的工作负载正在演变。多样化的工作负载导致对可配置内存资源的需求,以实现高性能和高利用率。 现有方法局限性 CXL是用于互连处理器、加速器和内存的开放标准。符合CXL标准的硬件提供了对应用程序代码透明的低延迟、高带宽数据访问。一些

HPC在精神分裂症和帕金森症的个性化非侵入性临床治疗中的应用
本文源自HPC365官网:HPC365——超算的云桌面 工程师们通过了解印度国立卫生研究院治疗精神分裂症以及潜在的帕金森病、抑郁症和其他脑部疾病的方法,利用HPC创新技术取代目前高风险的脑侵入手术程序,而采用非侵入性低风险治疗,同时还能节省治疗成本。 精神分裂症是一种严重的精神疾病。其特征是思想不合逻辑,行为语言奇怪,以及会产生妄想或幻觉,科学家们利用计算机模拟中人类大脑的非侵入性经颅电刺激。这

【观察】从EasyOP到先进计算服务平台,曙光HPC价值使命的全新飞跃
申耀的科技观察 读懂科技,赢取未来! 众所周知,中国HPC经过近四十年的发展,尤其最近十五年时间的快速崛起,已经从跟跑、并跑,进入到部分关键技术领跑的新时代。近期,中国HPC产学界共同努力,逐渐打破国外硬件制约,部分实现自主研发,软硬件协同支撑应用高速发展,迈向由应用引领机器研制的新时代。 但也要看到,一方面相比硬件领域取得的成绩,中国整体HPC的应用发展还有待发展,软硬件之间发展
Northern Data:人工智能领导者Innoplexus选择Northern Data HPC解决方案来加快针对COVID-19的药物研究和开发
德国法兰克福--(美国商业资讯)--全球最大的高性能计算(HPC)解决方案提供商之一Northern Data AG (XETRA: NB2, ISIN: DE000A0SMU87)今日宣布与Innoplexus AG缔结战略合作关系,以加快针对COVID-19及其他疾病的药物研究和开发。 Innoplexus是基于全球领先的人工智能(AI)的药物研究和开发平台,

汽车仿真效率30%、药物研发效率20倍,阿里云获HPC CHINA 2020“最佳行业应用奖”
在本届 HPC CHINA 2020 大会上,阿里云凭借弹性高性能计算平台 E-HPC 和神龙超级计算集群 SCC 的优异表现及其在行业的广泛应用,获得了中国计算机学会高性能计算专业委员会颁发的“高性能计算最佳行业应用奖”。 阿里云获 HPC CHINA 2020 “高性能计算最佳行业应用奖” 作为国内首个推出云超算的云服务商,阿里云弹性高性能计算平台通过自研神龙云服务器,实现了高性能计算