本文主要是介绍HPC: perf入门,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
如果你想查看你的程序在cpu上运行时,耗时时如何分布的,那么perf是一个合理的选择。
准备工作
为了支持使用perf,首先你要安装相关的库
sudo apt install linux-tools-5.15.0-67-generic
此外,因为使用perf进行benchmark, 涉及到一些系统权限,所以,你还需要修改权限,将下面文档中对应的参数改为-1
vim /proc/sys/kernel/perf_event_paranoid开始perf
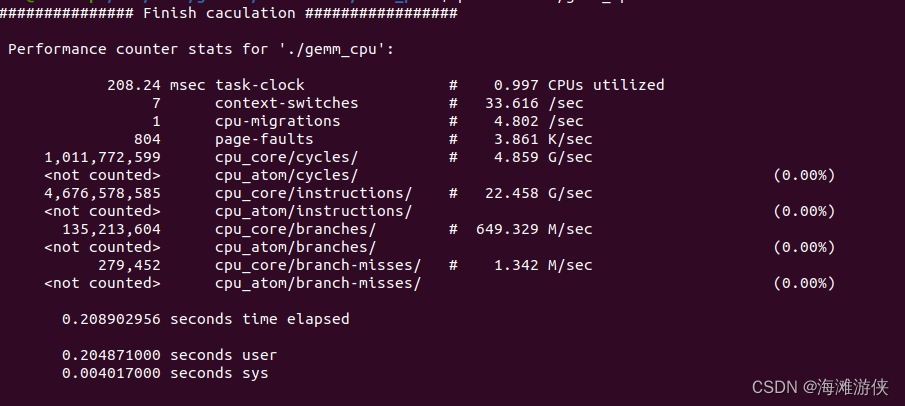
基于stat,我们可以获取程序的统计,包括耗时等。
perf stat ./gemm_cpu如 图
接下来,通过指令
perf record ./matrix_multiplicationperf report
我们可以获取对应的每个模块的耗时。

值得注意的时,如果函数的计算速度非常快,这里可能不会显示。比如Vectoradd, 相比于gemm。复杂度小了两个级别,这里原本不显示。我是通过增加循环的方式,来让它出现在了上面。


#include <stdio.h>
#include <stdlib.h>
#include <time.h>#define SIZE 500void initialize_matrix(int matrix[SIZE][SIZE]) {for (int i = 0; i < SIZE; i++) {for (int j = 0; j < SIZE; j++) {matrix[i][j] = rand() % 100;}}
}void initialize_vector(int vector[SIZE]) {for (int i = 0; i < SIZE; i++) {vector[i] = rand() % 100;}
}void multiply_matrices(int a[SIZE][SIZE], int b[SIZE][SIZE], int result[SIZE][SIZE]) {for (int i = 0; i < SIZE; i++) {for (int j = 0; j < SIZE; j++) {result[i][j] = 0;for (int k = 0; k < SIZE; k++) {result[i][j] += a[i][k] * b[k][j];}}}
}void vectorAdd(int vec1[SIZE], int vec2[SIZE], int vec[SIZE])
{printf("perform vectoAdd\n");for (int i = 0; i < SIZE; i++)for (int i = 0; i < SIZE; i++)for (int i = 0; i < SIZE; i++){vec[i] = vec1[i] + vec2[i];}
}int main() {int a[SIZE][SIZE], b[SIZE][SIZE], result[SIZE][SIZE];int vec_a[SIZE], vec_b[SIZE], vec_result[SIZE];// Initialize random number generatorsrand(time(NULL));// Initialize matricesinitialize_matrix(a);initialize_matrix(b);// Multiply matricesmultiply_matrices(a, b, result);initialize_vector(vec_a);initialize_vector(vec_b);vectorAdd(vec_a, vec_b, vec_result);#ifdef SHOWREULST// Print a part of the result matrix to verify the operationprintf("Result matrix:\n");for (int i = 0; i < 10; i++) {for (int j = 0; j < 10; j++) {printf("%d ", result[i][j]);}printf("\n");}#elseprintf("############### Finish caculation #################\n");
#endifreturn 0;
}这篇关于HPC: perf入门的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






