本文主要是介绍HPC -- 基础理论,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
面九坤的时候被会HPC的面试官吊打了,九坤的面试官给了一个评价:能进面的是合格的程序员,会HPC的才是优秀的程序员。
我对于HPC的了解只有https://www.yuque.com/treblez/qksu6c/nqe8ip59cwegl6rk?singleDoc# 《从微架构到向量化–CPU性能优化指北》这么多,还是要深入学习一下。
本文是https://en.algorithmica.org/hpc/和 https://weedge.github.io/perf-book-cn/zh/的阅读笔记。
现代hpc硬件算法
流水冲突 Pipeline Hazard
Pipeline hazard指的是方案指令并行的因素。
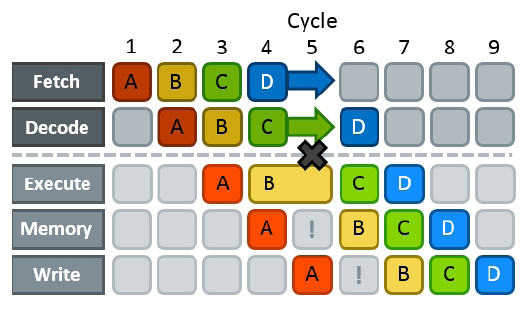
Hazard分为三类:
structural hazard:当两个或多个指令需要CPU的同一部分(例如,执行单元)时,就会发生structural hazard。
data hazard:当必须等待从前一步计算操作数时,就会发生data hazard。
control hazard:当CPU无法判断下一步需要执行哪条指令时,就会发生control hazard。
分支的成本 Cost of Branch
for (int i = 0; i < N; i++)a[i] = rand() % 100;
volatile int s;for (int i = 0; i < N; i++)if (a[i] < 50)s += a[i];
产生的汇编代码如下所示:
mov rcx, -4000000jmp body
counter:add rcx, 4jz finished ; "jump if rcx became zero"
body:mov edx, dword ptr [rcx + a + 4000000]cmp edx, 49jg counteradd dword ptr [rsp + 12], edxjmp counter
这里产生的cost有三个:
第一个是每两个cycles一个control hazards,每个cycle 等于19 cpu cycles;
第二个是mov edx, dword ptr [rcx + a + 4000000]访存,5 cpu cycles;
第三个是命中的时候4 cpu cycles 放到volatile主存
换成变量P:
for (int i = 0; i < N; i++)if (a[i] < P)s += a[i];
这个时候P和每循环周期数的关系如下:
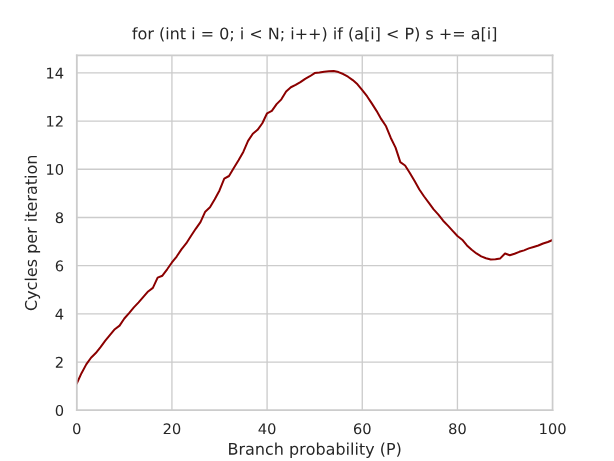
当P = 50的时候,分支预测失败代价很高,就跟上面分析的一样,14个cycles;当 85-90的时候,分支预测失败带来的消耗小于指令执行的消耗,因此有一个低峰。
for (int i = 0; i < N; i++)a[i] = rand() % 100;std::sort(a, a + n);
volatile int s;for (int i = 0; i < N; i++)if (a[i] < 50)s += a[i];
分支预测器可以检测到比“总是左,然后总是右”或“左-右-左-右”更复杂的模式。如果我们只是将数组的大小N减小到1000(不进行排序),那么分支预测器会记住整个比较序列,基准测试再次在大约4个周期进行测量——事实上,甚至比排序数组的情况略少,因为在前一种情况下,分支预测器需要花费一些时间在“总是是”和“总是否”状态之间切换。
使用谓词也就是cmov替换分支是这里的优化方法:
for (int i = 0; i < N; i++)s += (a[i] < 50 ? a[i] : 0);
Perf book
CPU架构
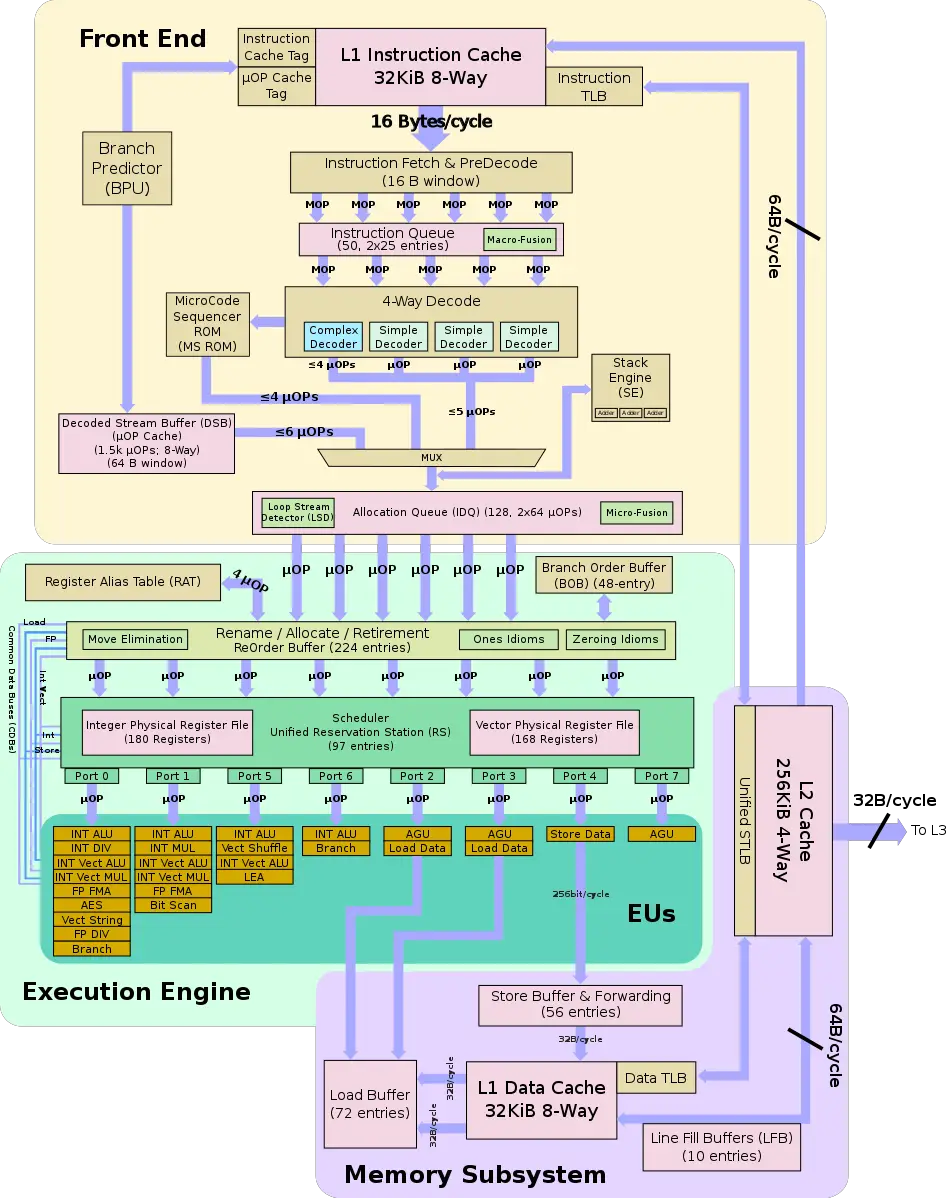
BPU
一旦程序达到稳定状态,分支预测单元(BPU)就会引导CPU前端的工作。这就是从BPU到指令缓存的箭头的原因。BPU预测所有分支指令的方向,并根据这个预测引导下一个指令提取。
BPU的核心是一个包含12K条目的分支目标缓冲区(BTB),其中包含有关分支及其目标的信息。这些信息被预测算法使用。每个周期,BPU生成下一个提取地址,并将其传递给CPU前端。
DSB
前端的一个主要性能提升特性是解码流缓冲区(DSB)或_μ_op缓存。其动机是在与L1 I-cache并行工作的单独结构中缓存宏操作到_μ_ops的转换。当BPU生成一个新地址进行提取时,也会检查DSB,以查看_μ_ops的转换是否已经在DSB中可用。频繁发生的宏操作会命中DSB,流水线将避免为32字节的捆绑重复执行昂贵的预解码和解码操作。DSB每个周期可以提供八个_μ_ops,并且最多可以容纳4K个条目。
ROB
CPU后端的核心是512条目的重排序缓冲区(ROB)。
该单元在图表中被称为"分配/重命名(Allocate / Rename)"。它有几个作用。首先,它提供寄存器重命名。只有16个通用整数寄存器和32个向量/SIMD体系结构寄存器,但是物理寄存器的数量要多得多。物理寄存器位于称为物理寄存器文件(PRF)的结构中。从体系结构可见寄存器到物理寄存器的映射保存在寄存器别名表(RAT)中。
其次,ROB分配执行资源。当一条指令进入ROB时,将分配一个新条目,并为其分配资源,主要是一个执行单元和目标物理寄存器。ROB每个周期可以分配多达6个_μ_ops。
第三,ROB跟踪推测执行。当一条指令完成其执行时,其状态会更新,并且会保留在那里,直到前面的指令也完成。之所以这样做,是因为指令总是按程序顺序退役。一旦一条指令退役,其ROB条目将被释放,并且指令的结果变得可见。退役阶段比分配阶段更宽:ROB每个周期可以退役8条指令。
RS
“调度器/保留站(Scheduler / Reservation Station)”(RS)是跟踪给定_μ_op的所有资源可用性并在准备就绪时将_μ_op分派到分配端口的结构。当一条指令进入RS时,调度器开始跟踪其数据依赖关系。一旦所有源操作数可用,RS尝试将_μ_op分派到空闲的执行端口。RS的条目比ROB少。它每个周期最多可以分派6个_μ_ops。
内存
优化内存访问
- 当数组较小的时候,使用顺序查找替代二分查找
- 使用OAS替代SOA
struct S {int a;int b;int c;// other fields
};
S s[N]; // AOS<=>struct S { // SOAint a[N];int b[N];int c[N];// other fields
};
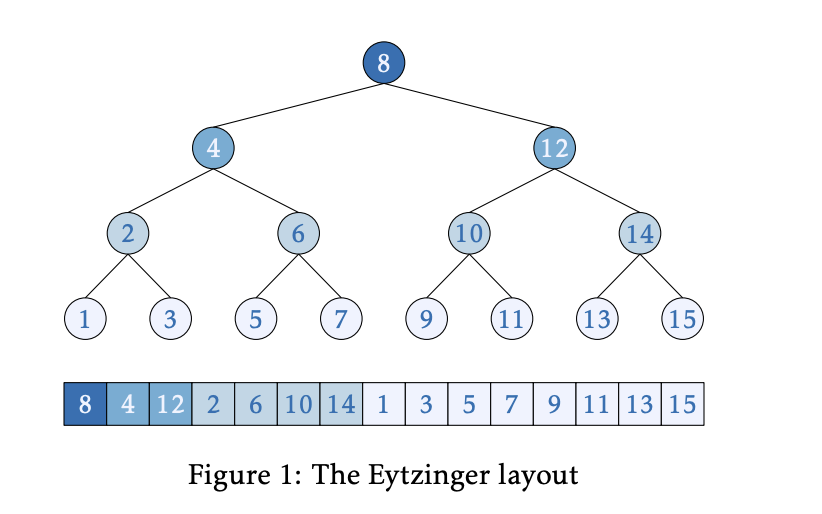
使用Eytzinger优化二分查找
优化结构体大小
使用枚举值
struct S {unsigned a;unsigned b;unsigned c;
}; // S is `sizeof(unsigned int) * 3` bytesstruct S {unsigned a:4;unsigned b:2;unsigned c:2;
}; // S is only 1 byte a占用4位,b和c分别占用2位
使用对齐和填充
// Make an aligned array
alignas(16) int16_t a[N];// Objects of struct S are aligned at cache line boundaries
#define CACHELINE_ALIGN alignas(64)
struct CACHELINE_ALIGN S {//...
};
避免伪共享
struct S {int a; // written by thread Aint b; // written by thread B
};#define CACHELINE_ALIGN alignas(64)
struct S {int a; // written by thread ACACHELINE_ALIGN int b; // written by thread B
};
调整代码适应缓存大小
显式内存预取
如果请求的内存位置不在缓存中,我们将无论如何遭受缓存未命中,因为我们必须访问 DRAM 并提取数据。但是,如果我们在程序需要数据时将该内存位置引入缓存,那么我们实际上可以将缓存未命中惩罚降为零。
现代 CPU 有两种解决这个问题的机制:硬件预取和 OOO 执行。硬件预取器通过对重复内存访问模式发起预取请求来帮助隐藏内存访问延迟。而 OOO 引擎则向前看 N 条指令,并提前发出加载指令,以允许平滑执行未来将需要此数据的指令。
使用显式并且消除依赖的内存预取:
size_t idx = random_distribution(generator);
for (int i = 0; i < N; ++i) {int x = arr[idx]; idx = random_distribution(generator);// prefetch the element for the next iteration__builtin_prefetch(&arr[idx]);doSomeExtensiveComputation(x);
}
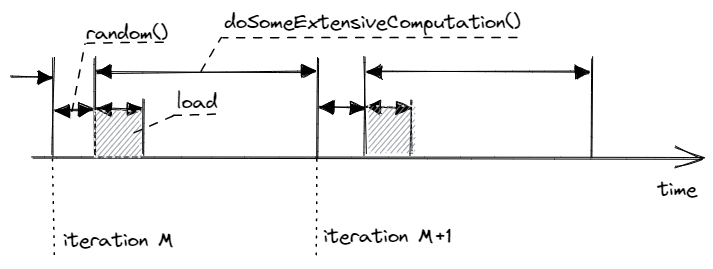
使用EHP和THP
Linux 用户可以使用三种不同的模式使用大页面:
- 显式大页面 (EHP)
- 系统范围透明大页面 (THP)
- 每个进程透明大页面 (THP)
让我们比较一下这些选项。首先,EHP 预先保留在虚拟内存中,而 THP 则没有。这使得使用 EHP 的软件包更难以交付,因为它们依赖于机器管理员所做的特定配置设置。此外,EHP 静态驻留在内存中,占用宝贵的 DRAM 空间,即使它们未使用。
其次,系统范围的透明大页面非常适合快速实验。无需更改用户代码即可测试在您的应用程序中使用大页面的好处。但是,将软件包运送给客户并要求他们启用系统范围的 THP 是不明智的,因为这可能会对该系统上运行的其他程序产生负面影响。通常,开发人员会识别代码中可以从大页面中受益的分配,并在这些位置使用 madvise 提示(每个进程模式)。
每个进程的 THP 没有上述任何一个缺点,但它还有一个缺点。之前我们讨论过,内核分配 THP 对用户来说是透明的。分配过程可能涉及多个内核进程,这些进程负责在虚拟内存中腾出空间,这可能包括将内存换出到磁盘、碎片化或提升页面。透明大页面的后台维护会产生内核在管理不可避免的碎片和交换问题时产生的非确定性延迟开销。EHP 不受内存碎片化影响,也不能换出到磁盘,因此延迟开销要小得多。
总而言之,THP 更易于使用,但会产生更大的分配延迟开销。这正是 THP 在高频交易和其他超低延迟行业不受欢迎的原因,他们更喜欢使用 EHP。另一方面,虚拟机提供商和数据库往往倾向于使用每个进程的 THP,因为要求额外的系统配置会给他们的用户带来负担。
优化计算
critical path关注延迟,非critical path关注吞吐量。
破除数据流依赖
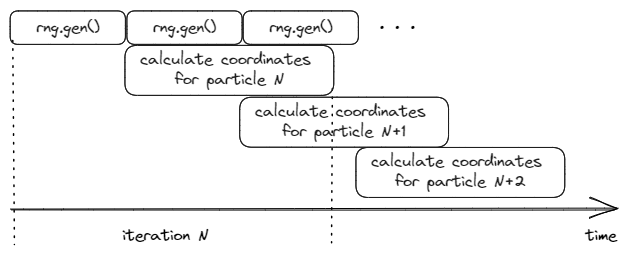
使用并行的代码破解数据流依赖
优化前:
struct Particle { │float x; float y; float velocity; │
}; ││
class XorShift32 { │uint32_t val; │
public: │XorShift32 (uint32_t seed) : val(seed) {} │uint32_t gen() { │val ^= (val << 13); │val ^= (val >> 17); │val ^= (val << 5); │return val; │ .loop:} │ eor w0, w0, w0, lsl #13
}; │ eor w0, w0, w0, lsr #17│ eor w0, w0, w0, lsl #5
static float sine(float x) { │ ucvtf s1, w0const float B = 4 / PI_F; │ fmov s2, w9const float C = -4 / ( PI_F * PI_F); │ fmul s2, s1, s2return B * x + C * x * std::abs(x); │ fmov s3, w10
} │ fadd s3, s2, s3
static float cosine(float x) { │ fmov s4, w11return sine(x + (PI_F / 2)); │ fmul s5, s3, s3
} │ fmov s6, w12│ fmul s5, s5, s6
/* Map degrees [0;UINT32_MAX) to radians [0;2*pi)*/ │ fmadd s3, s3, s4, s5
float DEGREE_TO_RADIAN = (2 * PI_D) / UINT32_MAX; │ ldp s6, s4, [x1, #0x4]│ ldr s5, [x1]
void particleMotion(vector<Particle> &particles, │ fmadd s3, s3, s4, s5uint32_t seed) { │ fmov s5, w13XorShift32 rng(seed); │ fmul s5, s1, s5for (int i = 0; i < STEPS; i++) │ fmul s2, s5, s2for (auto &p : particles) { │ fmadd s1, s1, s0, s2uint32_t angle = rng.gen(); │ fmadd s1, s1, s4, s6float angle_rad = angle * DEGREE_TO_RADIAN; │ stp s3, s1, [x1], #0xcp.x += cosine(angle_rad) * p.velocity; │ cmp x1, x16p.y += sine(angle_rad) * p.velocity; │ b.ne .loop} │
} │
优化后:
void particleMotion(vector<Particle> &particles, uint32_t seed1, uint32_t seed2) {XorShift32 rng1(seed1);XorShift32 rng2(seed2);for (int i = 0; i < STEPS; i++) {for (int j = 0; j + 1 < particles.size(); j += 2) {uint32_t angle1 = rng1.gen();float angle_rad1 = angle1 * DEGREE_TO_RADIAN;particles[j].x += cosine(angle_rad1) * particles[j].velocity;particles[j].y += sine(angle_rad1) * particles[j].velocity;uint32_t angle2 = rng2.gen();float angle_rad2 = angle2 * DEGREE_TO_RADIAN;particles[j+1].x += cosine(angle_rad2) * particles[j+1].velocity;particles[j+1].y += sine(angle_rad2) * particles[j+1].velocity;}// remainder (not shown)}
}
提示总是内联
对于 GCC 和 Clang 编译器,可以使用 C++11 的 [[gnu::always_inline]] 属性作为内联 foo 的提示,如下面的代码示例所示。对于较早的 C++ 标准,可以使用 attribute((always_inline))。对于 MSVC 编译器,可以使用 __forceinline 关键字。
循环优化
循环不变代码移动(Loop Invariant Code Motion,LICM)
大多数编译器可以自动进行。
for (int i = 0; i < N; ++i) for (int i = 0; i < N; ++i) {for (int j = 0; j < N; ++j) => auto temp = c[i];a[j] = b[j] * c[i]; for (int j = 0; j < N; ++j)a[j] = b[j] * temp;}
循环展开
一定要注意循环展开不能引入依赖!!!
for (int i = 0; i < N; ++i) for (int i = 0; i+1 < N; i+=2) {a[i] = b[i] * c[i]; => a[i] = b[i] * c[i];a[i+1] = b[i+1] * c[i+1];}
循环展开是一种众所周知的优化;尽管如此,许多人对此感到困惑,并尝试手动展开循环。我建议没有开发者应该手动展开任何循环。
首先,编译器在这方面做得很好,通常会非常优化地进行循环展开。第二个原因是,由于它们的乱序推测执行引擎(见[@sec:uarch]),处理器具有“嵌入式展开器”。当处理器等待第一次迭代中的长延迟指令完成时(例如加载、除法、微码指令、长依赖链),它会推测性地开始执行第二次迭代的指令,并且只等待循环携带的依赖项。这跨越了多个迭代,有效地在指令重排序缓冲区(ROB)中展开了循环。
循环强度降低
拿gcc测了一下,两个是一样的
for (int i = 0; i < N; ++i) int j = 0;a[i] = b[i * 10] * c[i]; => for (int i = 0; i < N; ++i) {a[i] = b[j] * c[i];j += 10;}
循环取消开关
这个编译器优化不了

循环优化的高级主题
还有一类循环转换会改变循环的结构,通常会影响到多个嵌套循环。我们将探讨循环交换(Loop Interchange)、循环阻塞(Loop Blocking,也称为平铺或Tiling)、以及循环融合和分布(Loop Fusion and Distribution,也称为Fission)。这些转换的目的是改善内存访问,消除内存带宽和内存延迟的瓶颈。从编译器的角度来看,证明这类转换的合法性并证明它们的性能优势是非常困难的。在这个意义上,开发者处于一个更好的位置,因为他们只需要关心他们特定代码片段中转换的合法性,而不需要关心可能发生的每一种情况。不幸的是,这也意味着我们通常需要手动进行这样的转换。
循环交换
交换嵌套循环的顺序的过程。内循环中使用的累加变量切换到外循环,反之亦然。@lst:Interchange展示了交换i和j嵌套循环的例子。循环交换的主要目的是对多维数组的元素进行顺序内存访问。通过遵循元素在内存中布局的顺序,我们可以提高内存访问的空间局部性,使我们的代码更加友好于缓存。
循环分块
这种转换的思想是将多维执行范围分割成更小的块(块或平铺),以便每个块都能适应CPU缓存。如果一个算法处理大型多维数组并对其元素进行跨步访问,那么缓存利用率很可能很低。每一次这样的访问可能会将未来访问请求的数据推出缓存(缓存驱逐)。通过将算法分割成更小的多维块,我们确保循环中使用的数据在被重用之前一直留在缓存中。
循环阻塞是优化通用矩阵乘法(GEMM)算法的广泛已知方法。它增强了内存访问的缓存重用,并改善了算法的内存带宽和内存延迟。
// linear traversal // traverse in 8*8 blocks
for (int i = 0; i < N; i++) for (int ii = 0; ii < N; ii+=8)for (int j = 0; j < N; j++) => for (int jj = 0; jj < N; jj+=8)a[i][j] += b[j][i]; for (int i = ii; i < ii+8; i++)for (int j = jj; j < jj+8; j++)a[i][j] += b[j][i];
循环展开和融合
for (int i = 0; i < N; i++) for (int i = 0; i+1 < N; i+=2)for (int j = 0; j < M; j++) for (int j = 0; j < M; j++) {diffs += a[i][j] - b[i][j]; => diffs1 += a[i][j] - b[i][j];diffs2 += a[i+1][j] - b[i+1][j];}diffs = diffs1 + diffs2;
循环展开和融合可以在没有跨迭代依赖的情况下执行外循环,换句话说,内循环的两次迭代可以并行执行。此外,如果内循环的内存访问在外部循环索引(本例中的i)上是跨步的,那么这种转换也是有意义的,否则其他转换可能更适用。当内循环的迭代次数较低时,例如小于4,展开和融合特别有用。通过进行转换,我们将更多的独立操作打包到内循环中,从而增加了ILP。
展开和融合转换有时对于外循环向量化非常有用,而在编写本文时,编译器无法自动执行。在内循环的迭代次数对编译器不可见的情况下,它仍然可以向量化原始内循环,希望它执行足够多的迭代以触发向量化代码(下一节将详细介绍向量化)。但如果迭代次数较低,程序将使用慢速的标量版本循环。一旦我们进行展开和融合,我们允许编译器以不同的方式向量化代码:现在将内循环中的独立指令“粘合”在一起(也称为SLP向量化)。
使用polly
向量化
向量化的基础(https://www.yuque.com/treblez/qksu6c/nqe8ip59cwegl6rk?singleDoc#)不再赘述,我们来看不能向量化的情况。
向量化是非法的
https://weedge.github.io/perf-book-cn/zh/chapters/9-Optimizing-Computations/9-4_Vectorization_cn.html#VectIllegal
读后写依赖
void vectorDependence(int *A, int n) {for (int i = 1; i < n; i++)A[i] = A[i-1] * 2;
}
浮点数运算顺序问题(使用-ffast-math)
// a.cpp 无法向量化,因为((a + b) + c) != (a + (b + c))
float calcSum(float* a, unsigned N) {float sum = 0.0f;for (unsigned i = 0; i < N; i++) {sum += a[i];}return sum;
}
优化分支预测
使用查找表替换分支

用算数替换分支
用谓词替换分支
见https://www.yuque.com/treblez/qksu6c/gihyheqszownoouf
机器代码布局优化
使用likely和unlikely改变默认布局
比如说异常处理,应该用unlikely改变布局达到更好的局部性
基本块对齐
见https://weedge.github.io/perf-book-cn/zh/chapters/11-Machine-Code-Layout-Optimizations/11-4_Basic_Block_Alignment_cn.html#Loop_better
函数拆分
分割冷热代码

优化ITLB未命中
汇总
低延时优化
避免页错误
主要是缓存预热:
char *mem = malloc(size);
int pageSize = sysconf(_SC_PAGESIZE)
for (int i = 0; i < size; i += pageSize)
mem[i] = 0;
以及mlock:
#include <malloc.h>
#include <sys/mman.h>
mallopt(M_MMAP_MAX, 0);
mallopt(M_TRIM_THRESHOLD, -1);
mallopt(M_ARENA_MAX, 1);
mlockall(MCL_CURRENT | MCL_FUTURE);
char *mem = malloc(size);
for (int i = 0; i < size; i += sysconf(_SC_PAGESIZE))
mem[i] = 0;
//...
free(mem);
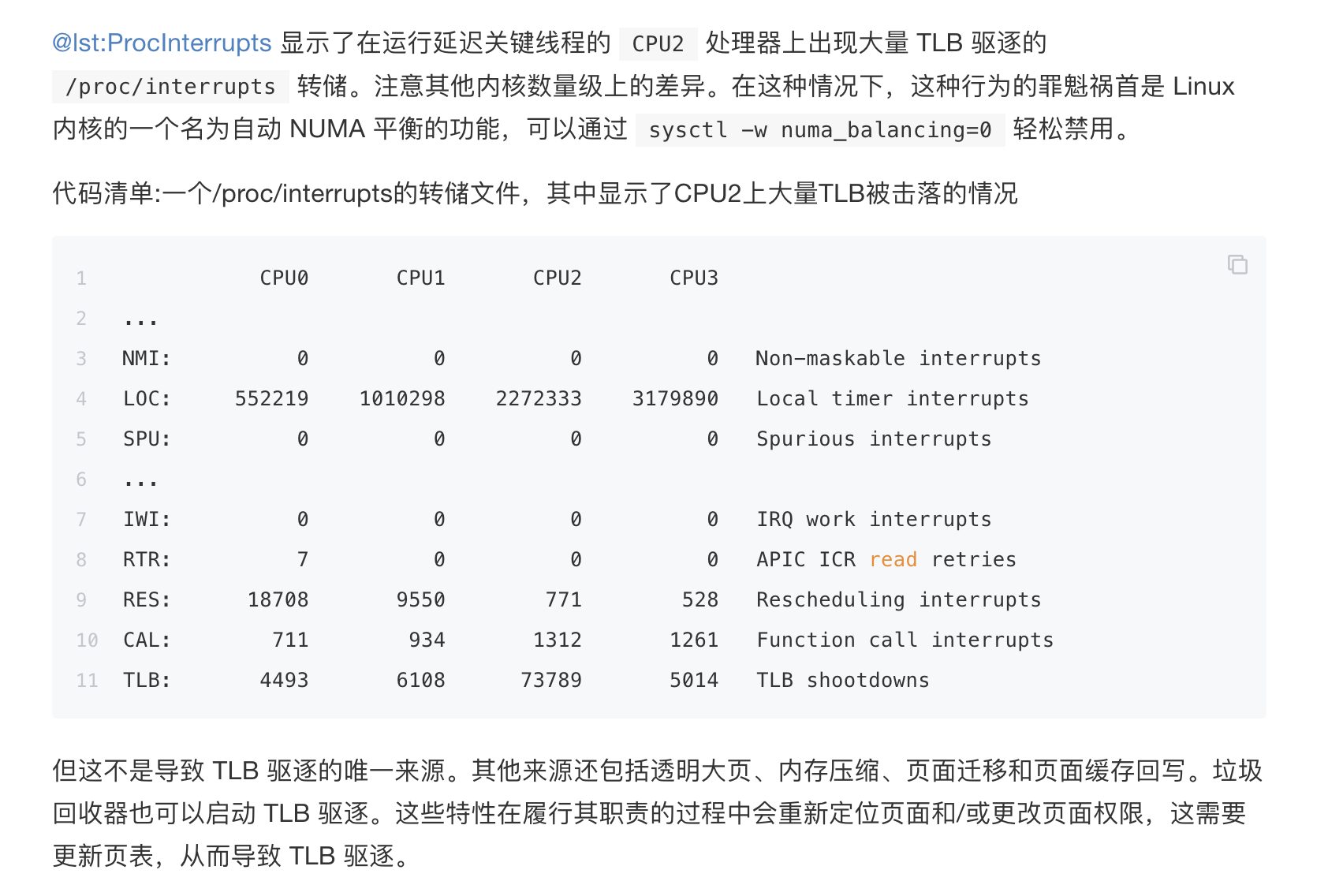
避免TLB驱逐
与基于 MESI 的协议和每个内核的 CPU 缓存(即 L1、L2 和 LLC)不同,硬件本身无法维护核心到核心之间的 TLB 一致性。因此,这项任务必须由内核通过软件来完成。内核通过一种特定的处理器间中断 (IPI) 来实现这个角色,叫做 TLB 驱逐,在 x86 平台上通过 INVLPG 汇编指令实现。
TLB 驱逐是实现多线程应用程序低延迟时最容易忽视的陷阱之一。为什么?因为在多线程应用程序中,进程线程共享虚拟地址空间。因此,内核必须在参与线程运行的内核的 TLB 之间通信特定类型的对该共享地址空间的更新。例如,常用的系统调用,如 munmap(可以禁用 glibc 分配器使用,参见 Section 12.2.1)、mprotect 和 madvise,会影响内核必须在进程的组成线程之间通信的地址空间更改类型。
如何检测多线程应用程序中的 TLB 驱逐?一种简单的方法是检查 /proc/interrupts 中的 TLB 行。一种检测运行时连续 TLB 中断的有用方法是在查看此文件时使用 watch 命令。例如,您可以运行 watch -n5 -d ‘grep TLB/proc/interrupts’, 其中 -n 5 选项每 5 秒刷新视图,而 -d 则突出显示每次刷新输出之间的差异。
缓慢的浮点运算
最后一级缓存敏感性
https://weedge.github.io/perf-book-cn/zh/chapters/12-Other-Tuning-Areas/12-7_Case_Study_-_LLC_sensitivity_cn.html
这篇关于HPC -- 基础理论的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







