本文主要是介绍linux驱动K10运算卡,GPU推动HPC普及,Tesla K10性能揭秘,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
拼 命 加 载 中 ...
这两天时值国际超级计算大会,Intel推出了MIC多核架构的商品化品牌Xeon Phi,NVIDIA作为GPU计算阵营的代表也没闲着,也向公众展示了GPU计算在HPC领域的成就,并首次公开了Tesla K10的性能。
Top500的性能排名是基于Linpack Fortran矩阵数学测试而来的,这是一种双精度运算,不过实际应用中基于单精度的运算依然占相当大比例,这正是Tesla K10擅长的地方。
GPU计算卡在HPC中通常扮演协处理器的角色,它可以极大地提高HPC的峰值性能,四年前IBM“走鹃”计算机使用的就是AMD六核Optron处理器加IBM Cell协处理器的方式首次达到Petaflops千万亿级计算性能的。(国内的天河-1A也是处理器+协处理器的方式冲顶的,使用的协处理器就是NVIDIA Fermi架构的M2090计算卡)
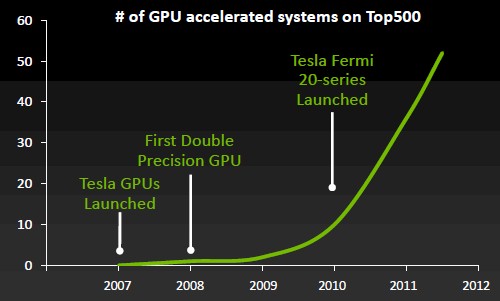
NVIDIA在2007年正式推出Tesla计算卡,不过到2008年Tesla卡才具备基本的双精度计算能力。2010年发布的Tesla 20系列基于Fermi核心,支持GDDR5显存内ECC纠错,双精度性能也大幅提升,相比传统CPU方案,基于Tesla的HPC不仅更便宜,而且功耗更低,在散热和能耗上可以节省大笔投资。
2012年上半年的Top500超级计算机中有58套系统使用了协处理器设计,其中53套基于NVIDIA Tesla计算卡,2套使用AMD显卡,一套使用Intel刚刚定名的Xeon Phi处理器(ps:这才56套,还有2套是什么协处理器没提到)

Top500中使用GPU协助计算的平台越来越多
排名前10的系统中有三套使用了Tesla计算卡,这一数值与一年前相比没有变化,11-50排名中有4套,翻了一倍,51-100的HPC中增加200%,而101-500的系统中数量增加了680%,用NVIDIA Tesla事业部高级产品经理Sumit Gupta的话说,“GPU使得HPC更加大众化,排名后400的系列中使用Tesla计算卡的系统达到前一年的8倍”。
他说实际上NVIDIA更关注的是不在Top500名单上的其他4000套HPC,NVIDIA的Tesla正在驱动HPC走向大众化。借助GPU的能力,一些规模较小的大学也构建Top500级别的小型计算中心。
为此,NVIDIA已经不再像上一代Fermi架构那样追求同步提升Tesla显卡的单精度和双精度性能,其中使用两颗GK104核心的Tesla K10主要面向单精度运算需求,浮点性能可达4.58TFLOPS,搭配8GB GDDR5显存。
基于GK110架构的Tesla K20主要面向双精度运算,双精度性能可达2TFlops,两倍于Intel刚刚宣布的Xeon Phi,二者都将在年底发布。

K10上的每颗GPU都有160GB/s的带宽,整块显卡则有320GB/s的吞吐带宽,与50GB/s带宽的Sandy Bridge架构的Xeon E5-2600相比,K10达到后者的6.4倍之多,即便与前代177.6GB/s带宽的M2090相比也有近一倍提升。
说了这么多,来看看Tesla K10真正的计算性能吧,对比的是上一代的M2090,当然测试基本都是基于单精度运算的。
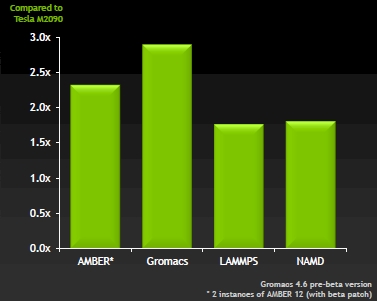
K10展示出了强大的性能,整体大约是M2090的2-3倍。
其中,Amber是分子动力学模型软件,2009年时它在96颗X86处理器组成的服务器上花了一天时间才完成了23558个原子大约46ns(纳秒)的模拟运算,而使用8颗M2050计算卡一天内就可以完成52ns的运算,如果使用M2090则可以完成69ns的运算量。
到了今年,使用两颗K10计算卡就可以完成66ns的运算量,如果也使用8块K10运算的话那就可以完成四倍的运算量。
除了地震预测及分子动力学计算之外,K10同样也适用于卫星图像处理、视频增强、信号处理、计算机视觉、视频转码以及数字处理等领域,前提是对双精度运算要求不高。
这篇关于linux驱动K10运算卡,GPU推动HPC普及,Tesla K10性能揭秘的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







