hadoop2专题

Hadoop2.x HDFS HA架构部署配置
一、HA简介 在Hadoop2.x之前,HDFS集群中只有一个NameNode,若NameNode出现了故障,则整个集群将无法使用,直到NameNode重新启动。 Hadoop2.x开始支持HA和Federation。HDFS HA功能通过配置Active/Standby两个NameNode实现集群中对NameNode的热备。如果Active出现故障,则Standby可快速替代

hadoop2提交到Yarn: Mapreduce执行过程reduce分析3
原文 问题导读: 1.Reduce类主要有哪三个步骤? 2.Reduce的Copy都包含什么过程? 3.Sort主要做了哪些工作? 4.4 Reduce类4.4.1 Reduce介绍 整完了Map,接下来就是Reduce了。YarnChild.main()—>ReduceTask.run()。ReduceTask.run方法开始和MapTask类似,包括initialize()初

hadoop2提交到Yarn: Mapreduce执行过程分析2
原文 问题导读: 1.hadoop哪些数据类型,是如何与Java数据类型对应的? 2.ApplicationMaster什么时候启动? 3.YarnChild进程什么时候产生? 4.如果在recuece的情况下,map任务完成暂总任务的多少百分比? 5.run的执行步骤是什么? 6.哪个方法来执行具体的map任务? 7.获取配置信息为哪个类? 8.TaskAttemptContextImpl还增
hadoop2提交到Yarn: Mapreduce执行过程分析1
原文 1.为什么会产生Yarn? 2.Configuration类的作用是什么? 3.GenericOptionsParser类的作用是什么? 4.如何将命令行中的参数配置到变量conf中? 5.哪个方法会获得传入的参数? 6.如何在命令行指定reduce的个数? 7.默认情况map、reduce为几? 8.setJarByClass的作用是什么? 9.如果想在控制台打印job(maoreduc
Hadoop2.x配置HA
各节点配置参考表 主机NameNodeDataNodeZookeeperZKFCJournalNodeResourceManagerNodeManagernode11111node2111111node31111node4111 文件配置: core-site.xml <property><name>hadoop.tmp.dir</name><value>/csh/hadoop/h

配置Hadoop2.x的HDFS、MapReduce来运行WordCount程序
主机HDFSMapReducenode1NameNodeResourceManagernode2SecondaryNameNode & DataNodeNodeManagernode3DataNodeNodeManagernode4DataNodeNodeManager 1.配置hadoop-env.sh export JAVA_HOME=/csh/link/jdk 2.配置core-sit
Datax与hadoop2.x兼容部署与实际项目应用工作记录分享
一、概述 Hadoop的版本更新挺快的,已经到了2.4,但是其周边工具的更新速度还是比较慢的,一些旧的周边工具版本对hadoop2.x的兼容性做得还不完善,特别是sqoop。最近,在为hadoop2.2.0找适合的sqoop版本时遇到了很多问题。尝试了多个sqoop1.4.x版本的直接简单粗暴的报版本不兼容问题,其中测了sqoop-1.4.4.bin__hadoop-0.23这个版本,在
Hadoop2.X大数据集群规划与架构设计
卡弗卡大数据 2017-05-07 17:27 第一阶段:先说说伪分布式 不管是HDFS和YARN,在我们之前的文章中已经说过关于伪分布式的部署和安装。也就是我们把HDFS的两个节点NameNode和DataNode,YARN的ResourceManger和NodeManager都放在同一个机器上。 机器1:bigdata-senior01.kfk.com 进程包括: Nam

Hadoop2源码分析-MapReduce篇
1.概述 前面我们已经对Hadoop有了一个初步认识,接下来我们开始学习Hadoop的一些核心的功能,其中包含mapreduce,fs,hdfs,ipc,io,yarn,今天为大家分享的是mapreduce部分,其内容目录如下所示: MapReduce V1MapReduce V2MR V1和MR V2的区别MR V2的重构思路 本篇文章的源码是基于hadoop-2.6.0-s

Hadoop2源码分析-YARN 的服务库和事件库
1.概述 在《Hadoop2源码分析-YARN RPC 示例介绍》一文当中,给大家介绍了YARN 的 RPC 机制,以及相关代码的演示,今天我们继续去学习 YARN 的服务库和事件库,分享目录如下所示: 服务库和事件库介绍使用示例截图预览 下面开始今天的内容分享。 2.服务库和事件库介绍 2.1服务库 YARN对于生命周期较长的对象使用服务的对象模型进行管理,主

Hadoop2源码分析-YARN RPC 示例介绍
我们知道在Hadoop的RPC当中,其主要由RPC,Client及Server这三个大类组成,分别实现对外提供编程接口、客户端实现及服务端实现。如下图所示: 图中是Hadoop的RPC的一个类的关系图,大家可以到《Hadoop2源码分析-RPC探索实战》一文中,通过代码示例去理解他们之间的关系,这里就不多做赘述了。接下来,我们去看Yarn的RPC。 Yar

phoenix实战(hadoop2、hbase0.96)
版本: phoenix:2.2.2,可以下载源码(https://github.com/forcedotcom/phoenix/tree/port-0.96)自己编译,或者从这里下载(http://download.csdn.net/detail/fansy1990/7146479、http://download.csdn.net/detail/fansy1990/7146501)。 h
如何在CentOS6.5下编译64位的Hadoop2.x?
1 安装gcc,执行如下的几个yum命令即可 Java代码 yum -y install gcc yum -y install gcc-c++ yum install make yum install autoconf automake libtool cmake ncurses-devel openssl-devel
hadoop2.x安装文件配置
目录 配置hadoop-env.sh 配置yarn-env.sh 配置core-site.xml 配置hdfs-site.xml 配置mapred-site.xml 配置yarn-site.xml 配置slaves文件 配置hadoop-env.sh 打开配置文件hadoop-env.sh cd etc/hadoopvi hadoop-env.sh 加入配置内容,设置了ha

怎么编译hadoop2.x的eclipse插件
Hadoop2.x之后,已经发布了稳定的版本hadoop2.2.0.但是由于没有eclipse插件工具,辅助,开发调试相对起来,会稍显麻烦,特别是基于Java开发的工程师们,虽然写完MR任务后,也可以采用打成jar包的方式,上传调试,但是这种方式,也有点繁琐,不过网上也好像有一些,使用程序能够自动打包任务的程序,散仙没具体用过,在这里,就不多涉及了,有知道的朋友们,欢迎分享。 下面开始
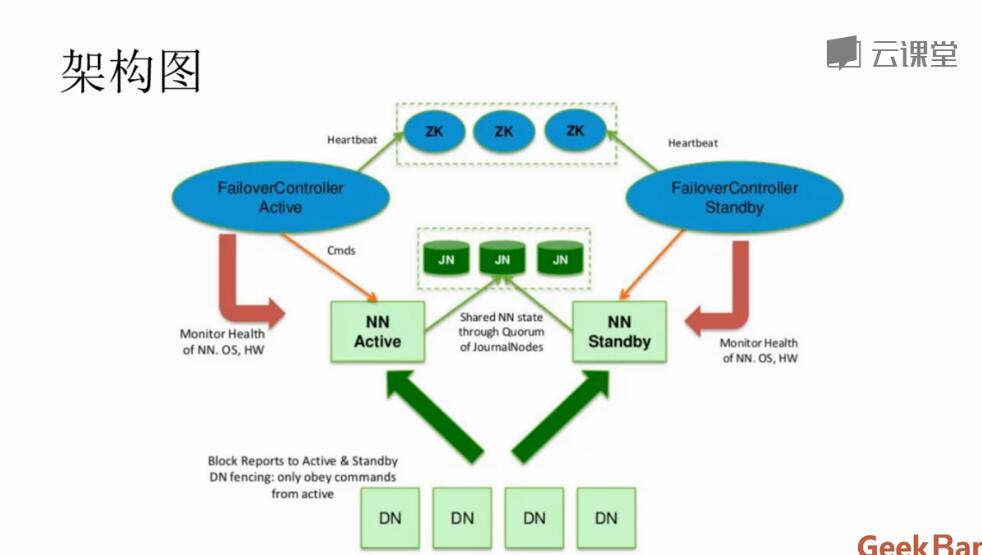
大数据实战(下)-搭建hadoop2 HA
大纲 NameNode高可用整体架构 NameNode的主备切换 NameNode的共享存储 NameNode高可用整体架构 hadoop1.x 两大核心hdfs、mapRedure,这两个都存在一个单点问题。 hadoop2.0的HA 机制有两个namenode,一个是active namenode,状态是active;另外一个是standby namenode,状态是standby
Hadoop2.x eclipse plugin插件编译安装配置
本文主要讲解如何编译安装配置 Hadoop2.x eclipse plugin插件的详细过程: 环境参数编译过程安装配置 详见: http://www.micmiu.com/bigdata/hadoop/hadoop2-x-eclipse-plugin-build-install/
HBase基于Hadoop2的源码编译
本文以HBase0.98.0 为例,演示编译生成适用于Hadoop2.x 版本软件包的过程。 基本环境参数: Mac OSX 10.9.1Maven 3.0.4Java 1.6.0_65Hadoop 2.2.0HBase 0.98.0 源码编译的基本步骤: 详见:http://www.micmiu.com/opensource/hadoop/hbase-build-for-hadoop2
Hadoop2.x介绍与源码编译
1、Hadoop 项目的四大模块 Hadoop Common: The common utilities that support the other Hadoop modules.Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to ap

hadoop2.x linux集群部署
hadoop2.x 集群部署 下载hadoop需要提前准备好jdk1.8 和rsync 和ssl集群信息解压安装配置环境变量配置site配置文件(/hadoop/etc/hadoop目录下)core-site.xmlhdfs-site.xmlyarn-site.xmlmapred-site.xmlhadoop-env.sh要追加java_home!配置节点slaves 配置免密ssh访问没有
hadoop2.x linux集群部署
hadoop2.x 集群部署 下载hadoop需要提前准备好jdk1.8 和rsync 和ssl集群信息解压安装配置环境变量配置site配置文件(/hadoop/etc/hadoop目录下)core-site.xmlhdfs-site.xmlyarn-site.xmlmapred-site.xmlhadoop-env.sh要追加java_home!配置节点slaves 配置免密ssh访问没有
Win7下面安装hadoop2.x插件及Win7/Linux运行MapReduce程序
一、win7下 (一)、安装环境及安装包 win7 32 bit jdk7 eclipse-java-juno-SR2-win32.zip hadoop-2.2.0.tar.gz hadoop-eclipse-plugin-2.2.0.jar hadoop-common-2.2.0-bin.rar (二)、安装 默认已经安装好了jdk、eclipse以及配置好了hadoop伪分布
hadoop2.x通过Zookeeper来实现namenode的HA方案以及ResourceManager单点故障的解决方案
hadoop2.x通过Zookeeper来实现namenode的HA方案以及ResourceManager单点故障的解决方案 参考文章: (1)hadoop2.x通过Zookeeper来实现namenode的HA方案以及ResourceManager单点故障的解决方案 (2)https://www.cnblogs.com/ljy2013/p/4512550.html 备忘一下。
![[Hadoop2.x] Hadoop运行一段时间后,stop-dfs等操作失效原因及解决方法](https://www.oschina.net/img/hot3.png)
[Hadoop2.x] Hadoop运行一段时间后,stop-dfs等操作失效原因及解决方法
为什么80%的码农都做不了架构师?>>> 长时间运行Hadoop之后,如果运行 stop-dfs.sh(或stop-all.sh),会发现有以下类似错误: Stopping namenodes on [localhost] localhost: no namenode to stop localhost: no datanode to stop Stopping secondary n
Hadoop2复安装过程详细步骤
1、在vmware中更改了虚拟机的网络类型,--->NAT方式,(虚拟交换机的ip可以从vmvare的edit-->vertual network editor看到) 2、根据这个交换机(网关)的地址,来设置我们的客户端windows7的ip(Vmnet8这块网卡) 3、启动linux主机,修改linux系统的ip地址(通过图形界面修改),修改完成之后在terminal(命令行终端)中切换到roo