本文主要是介绍Hadoop2源码分析-YARN RPC 示例介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我们知道在Hadoop的RPC当中,其主要由RPC,Client及Server这三个大类组成,分别实现对外提供编程接口、客户端实现及服务端实现。如下图所示:

图中是Hadoop的RPC的一个类的关系图,大家可以到《Hadoop2源码分析-RPC探索实战》一文中,通过代码示例去理解他们之间的关系,这里就不多做赘述了。接下来,我们去看Yarn的RPC。
Yarn对外提供的是YarnRPC这个类,这是一个抽象类,通过阅读YarnRPC的源码可以知道,实际的实现由参数yarn.ipc.rpc.class设定,默认情况下,其值为:org.apache.hadoop.yarn.ipc.HadoopYarnProtoRPC,部分代码如下:
- YarnRPC:

public abstract class YarnRPC {// ......public static YarnRPC create(Configuration conf) {LOG.debug("Creating YarnRPC for " + conf.get(YarnConfiguration.IPC_RPC_IMPL));String clazzName = conf.get(YarnConfiguration.IPC_RPC_IMPL);if (clazzName == null) {clazzName = YarnConfiguration.DEFAULT_IPC_RPC_IMPL;}try {return (YarnRPC) Class.forName(clazzName).newInstance();} catch (Exception e) {throw new YarnRuntimeException(e);}}}
- YarnConfiguration类:
public class YarnConfiguration extends Configuration {//Configurationspublic static final String YARN_PREFIX = "yarn.";// IPC Configs public static final String IPC_PREFIX = YARN_PREFIX + "ipc.";/** RPC class implementation*/public static final String IPC_RPC_IMPL =IPC_PREFIX + "rpc.class";public static final String DEFAULT_IPC_RPC_IMPL = "org.apache.hadoop.yarn.ipc.HadoopYarnProtoRPC"; }
而HadoopYarnProtoRPC 通过 RPC 的 RpcFactoryProvider 生成客户端工厂(由参数 yarn.ipc.client.factory.class 指定,默认值是 org.apache.hadoop.yarn.factories.impl.pb.RpcClientFactoryPBImpl)和服务器工厂 (由参数 yarn.ipc.server.factory.class 指定,默认值是 org.apache.hadoop.yarn.factories.impl.pb.RpcServerFactoryPBImpl),以根据通信协议的 Protocol Buffers 定义生成客户端对象和服务器对象。相关类的部分代码如下:
- HadoopYarnProtoRPC
public class HadoopYarnProtoRPC extends YarnRPC {private static final Log LOG = LogFactory.getLog(HadoopYarnProtoRPC.class);@Overridepublic Object getProxy(Class protocol, InetSocketAddress addr,Configuration conf) {LOG.debug("Creating a HadoopYarnProtoRpc proxy for protocol " + protocol);return RpcFactoryProvider.getClientFactory(conf).getClient(protocol, 1,addr, conf);}@Overridepublic void stopProxy(Object proxy, Configuration conf) {RpcFactoryProvider.getClientFactory(conf).stopClient(proxy);}@Overridepublic Server getServer(Class protocol, Object instance,InetSocketAddress addr, Configuration conf,SecretManager<? extends TokenIdentifier> secretManager,int numHandlers, String portRangeConfig) {LOG.debug("Creating a HadoopYarnProtoRpc server for protocol " + protocol + " with " + numHandlers + " handlers");return RpcFactoryProvider.getServerFactory(conf).getServer(protocol, instance, addr, conf, secretManager, numHandlers, portRangeConfig);}}
-
RpcFactoryProvider
public class RpcFactoryProvider {// ......public static RpcClientFactory getClientFactory(Configuration conf) {String clientFactoryClassName = conf.get(YarnConfiguration.IPC_CLIENT_FACTORY_CLASS,YarnConfiguration.DEFAULT_IPC_CLIENT_FACTORY_CLASS);return (RpcClientFactory) getFactoryClassInstance(clientFactoryClassName);}//...... }
/** Factory to create client IPC classes.*/public static final String IPC_CLIENT_FACTORY_CLASS =IPC_PREFIX + "client.factory.class";public static final String DEFAULT_IPC_CLIENT_FACTORY_CLASS = "org.apache.hadoop.yarn.factories.impl.pb.RpcClientFactoryPBImpl";
在 YARN 中并未使用Hadoop自带的Writable来做序列化,而是使用 Protocol Buffers 作为默认的序列化机制,这带来的好处主要有以下几点:
- 继承Protocol Buffers的优点:Protocol Buffers已被实践证明其拥有高效性、可扩展性、紧凑性以及跨语言性等特点。
- 支持在线升级回滚:在Hadoop 2.x版本后,添加的HA方案,该方案能够进行主备切换,在不停止NNA节点服务的前提下,能够在线升级版本。
3.YARN的RPC示例
YARN 的工作流程是先定义通信协议接口ResourceTracker,它包含2个函数,具体代码如下所示:
- ResourceTracker:
public interface ResourceTracker {@Idempotentpublic RegisterNodeManagerResponse registerNodeManager(RegisterNodeManagerRequest request) throws YarnException,IOException;@AtMostOncepublic NodeHeartbeatResponse nodeHeartbeat(NodeHeartbeatRequest request)throws YarnException, IOException;}
这里ResourceTracker提供了Protocol Buffers定义和Java实现,其中设计的Protocol Buffers文件有:ResourceTracker.proto、yarn_server_common_service_protos.proto和yarn_server_common_protos.proto,文件路径在Hadoop的源码包的 hadoop-2.6.0-src/hadoop-yarn-project/hadoop-yarn/hadoop-yarn-server/hadoop-yarn-server-common/src/main/proto,这里就不贴出3个文件的具体代码类,大家可以到该目录去阅读这部分代码。这里需要注意的是,若是大家要编译这些文件需要安装 ProtoBuf 的编译环境,环境安装较为简单,这里给大家简要说明下。
首先是下载ProtoBuf的安装包,然后解压,进入到解压目录,编译安装。命令如下:
./configure --prefix=/home/work /protobuf/ make && make install
最后编译 .proto 文件的命令:
protoc ./ResourceTracker.proto --java_out=./
下面,我们去收取Hadoop源码到本地工程,运行调试相关代码。
-
TestYarnServerApiClasses:
public class TestYarnServerApiClasses {// ......// 列举测试4个方法 @Testpublic void testRegisterNodeManagerResponsePBImpl() {RegisterNodeManagerResponsePBImpl original =new RegisterNodeManagerResponsePBImpl();original.setContainerTokenMasterKey(getMasterKey());original.setNMTokenMasterKey(getMasterKey());original.setNodeAction(NodeAction.NORMAL);original.setDiagnosticsMessage("testDiagnosticMessage");RegisterNodeManagerResponsePBImpl copy =new RegisterNodeManagerResponsePBImpl(original.getProto());assertEquals(1, copy.getContainerTokenMasterKey().getKeyId());assertEquals(1, copy.getNMTokenMasterKey().getKeyId());assertEquals(NodeAction.NORMAL, copy.getNodeAction());assertEquals("testDiagnosticMessage", copy.getDiagnosticsMessage());}@Testpublic void testNodeHeartbeatRequestPBImpl() {NodeHeartbeatRequestPBImpl original = new NodeHeartbeatRequestPBImpl();original.setLastKnownContainerTokenMasterKey(getMasterKey());original.setLastKnownNMTokenMasterKey(getMasterKey());original.setNodeStatus(getNodeStatus());NodeHeartbeatRequestPBImpl copy = new NodeHeartbeatRequestPBImpl(original.getProto());assertEquals(1, copy.getLastKnownContainerTokenMasterKey().getKeyId());assertEquals(1, copy.getLastKnownNMTokenMasterKey().getKeyId());assertEquals("localhost", copy.getNodeStatus().getNodeId().getHost());}@Testpublic void testNodeHeartbeatResponsePBImpl() {NodeHeartbeatResponsePBImpl original = new NodeHeartbeatResponsePBImpl();original.setDiagnosticsMessage("testDiagnosticMessage");original.setContainerTokenMasterKey(getMasterKey());original.setNMTokenMasterKey(getMasterKey());original.setNextHeartBeatInterval(1000);original.setNodeAction(NodeAction.NORMAL);original.setResponseId(100);NodeHeartbeatResponsePBImpl copy = new NodeHeartbeatResponsePBImpl(original.getProto());assertEquals(100, copy.getResponseId());assertEquals(NodeAction.NORMAL, copy.getNodeAction());assertEquals(1000, copy.getNextHeartBeatInterval());assertEquals(1, copy.getContainerTokenMasterKey().getKeyId());assertEquals(1, copy.getNMTokenMasterKey().getKeyId());assertEquals("testDiagnosticMessage", copy.getDiagnosticsMessage());}@Testpublic void testRegisterNodeManagerRequestPBImpl() {RegisterNodeManagerRequestPBImpl original = new RegisterNodeManagerRequestPBImpl();original.setHttpPort(8080);original.setNodeId(getNodeId());Resource resource = recordFactory.newRecordInstance(Resource.class);resource.setMemory(10000);resource.setVirtualCores(2);original.setResource(resource);RegisterNodeManagerRequestPBImpl copy = new RegisterNodeManagerRequestPBImpl(original.getProto());assertEquals(8080, copy.getHttpPort());assertEquals(9090, copy.getNodeId().getPort());assertEquals(10000, copy.getResource().getMemory());assertEquals(2, copy.getResource().getVirtualCores());}}
-
TestResourceTrackerPBClientImpl:
public class TestResourceTrackerPBClientImpl {private static ResourceTracker client;private static Server server;private final static org.apache.hadoop.yarn.factories.RecordFactory recordFactory = RecordFactoryProvider.getRecordFactory(null);@BeforeClasspublic static void start() {System.out.println("Start client test");InetSocketAddress address = new InetSocketAddress(0);Configuration configuration = new Configuration();ResourceTracker instance = new ResourceTrackerTestImpl();server = RpcServerFactoryPBImpl.get().getServer(ResourceTracker.class, instance, address, configuration, null,1);server.start();client = (ResourceTracker) RpcClientFactoryPBImpl.get().getClient(ResourceTracker.class, 1,NetUtils.getConnectAddress(server), configuration);}@AfterClasspublic static void stop() {System.out.println("Stop client");if (server != null) {server.stop();}}/*** Test the method registerNodeManager. Method should return a not null* result.* */@Testpublic void testResourceTrackerPBClientImpl() throws Exception {RegisterNodeManagerRequest request = recordFactory.newRecordInstance(RegisterNodeManagerRequest.class);assertNotNull(client.registerNodeManager(request));ResourceTrackerTestImpl.exception = true;try {client.registerNodeManager(request);fail("there should be YarnException");} catch (YarnException e) {assertTrue(e.getMessage().startsWith("testMessage"));} finally {ResourceTrackerTestImpl.exception = false;}}/*** Test the method nodeHeartbeat. Method should return a not null result.* */@Testpublic void testNodeHeartbeat() throws Exception {NodeHeartbeatRequest request = recordFactory.newRecordInstance(NodeHeartbeatRequest.class);assertNotNull(client.nodeHeartbeat(request));ResourceTrackerTestImpl.exception = true;try {client.nodeHeartbeat(request);fail("there should be YarnException");} catch (YarnException e) {assertTrue(e.getMessage().startsWith("testMessage"));} finally {ResourceTrackerTestImpl.exception = false;}}public static class ResourceTrackerTestImpl implements ResourceTracker {public static boolean exception = false;public RegisterNodeManagerResponse registerNodeManager(RegisterNodeManagerRequest request)throws YarnException, IOException {if (exception) {throw new YarnException("testMessage");}return recordFactory.newRecordInstance(RegisterNodeManagerResponse.class);}public NodeHeartbeatResponse nodeHeartbeat(NodeHeartbeatRequest request) throws YarnException, IOException {if (exception) {throw new YarnException("testMessage");}return recordFactory.newRecordInstance(NodeHeartbeatResponse.class);}} }
4.截图预览
接下来,我们使用JUnit去测试代码,截图预览如下所示:
- 对testRegisterNodeManagerRequestPBImpl()方法的一个DEBUG调试

-
testResourceTrackerPBClientImpl()方法的DEBUG调试
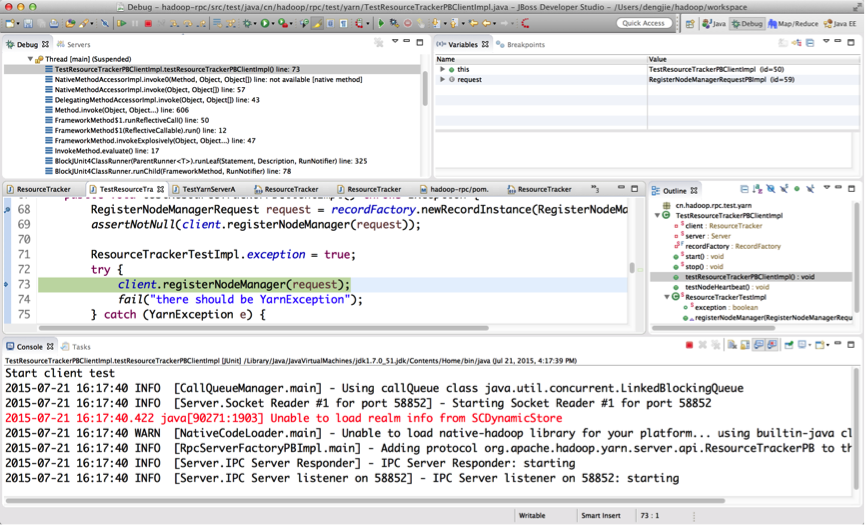
这里由于设置exception的状态为true,在调用registerNodeManager()时,会打印一条测试异常信息。
if (exception) { throw new YarnException("testMessage"); }
5.总结
在学习Hadoop YARN的RPC时,可以先了解Hadoop的RPC机制,这样在接触YARN的RPC的会比较好理解,YARN的RPC只是其中的一部分,后续会给大家分享更多关于YARN的内容。
转自:http://www.cnblogs.com/smartloli/p/4664842.html
这篇关于Hadoop2源码分析-YARN RPC 示例介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





