groupby专题

谈谈分组:sql的group by+聚集函数 和 python的groupby+agg
直接举例子+分析例子+总结来说,我先给几个表: 学生表:student(学号,姓名,年龄,院系); 课程表:course(课程号,课程名,学分); 学生选课表:sc(学号,课程号,分数); 啥时候用分组呢? 我由简至深来谈。 1、比如让我们查询各个课程号及相应的选课人数。 首先定位到sc表上,“各个”很明显就是要按课程分组,group by出场了,分组后对每组去统计选课人数,聚集函数出场了。

Pandas-高级处理(四):分组与聚合【分组:groupby、聚合统计:max/min/mean...、分组转换:transform、一般化Groupby方法:apply】【抛开聚合只谈分组没意义】
df.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs) 分组统计 - groupby功能 ① 根据某些条件将数据拆分成组 ② 对每个组独立应用函数 ③ 将结果合并到一个数据结构中 应用groupby和聚合函数实现数据的分组与聚合

MP条件构造器之常用功能详解(in、notIng、groupBy)
文章目录 in使用范围方法签名参数说明示例使用集合的 `in` 设置指定字段的 IN 条件使用可变参数的 `in` 设置指定字段的 IN 条件动态根据条件设置 `in` 条件 notIn使用范围方法签名参数说明示例使用 `notIn` 设置指定字段的 NOT IN 条件使用可变参数的 `notIn` 设置指定字段的 NOT IN 条件动态根据条件设置 `notIn` 条件 groupBy

Python数据分析利器之groupby和pivot_table使用详解
概要 在数据分析的过程中,数据聚合与数据透视是两项非常重要的操作。Python的Pandas库提供了强大的工具——groupby和pivot_table,帮助我们高效地进行数据聚合和透视分析。本文将详细介绍如何使用这两个功能,并结合示例代码展示它们的实际应用,帮助更好地掌握数据分析的技巧。 数据聚合 groupby groupby 是Pandas中用于对数据进行分组并进行聚合操作

利用Pandas的groupby和矢量化运算,减少显式循环,提高处理速度
目录 1. **`groupby` 机制****传统循环的缺点:****`groupby` 提高效率的方式:** 2. **矢量化运算****传统循环的缺点:****矢量化运算的优势:** 3. **结合`groupby`与矢量化运算**4. **对比示例****传统循环:****使用`groupby`和矢量化运算:** 5. **性能提升原因**6. **实际代码示例**结论

【Pandas驯化-11】一文搞懂Pandas中的分组函数groupby与qcut、fillna使用
【Pandas驯化-11】一文搞懂Pandas中的分组函数groupby与qcut、fillna使用 本次修炼方法请往下查看 🌈 欢迎莅临我的个人主页 👈这里是我工作、学习、实践 IT领域、真诚分享 踩坑集合,智慧小天地! 🎇 相关内容文档获取 微信公众号 🎇 相关内容视频讲解 B站 🎓 博主简介:AI算法驯化师,混迹多个大厂搜索、推荐、广告、数据分析、数据挖掘岗位 个人申
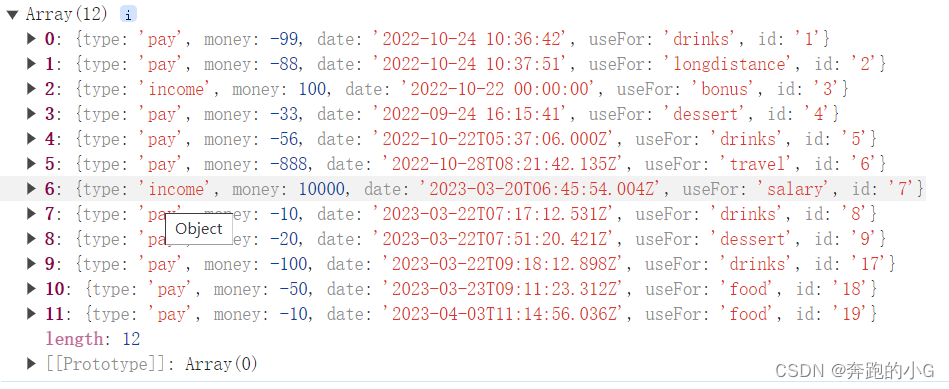
【React】Lodash---groupBy() 分组
例子 _.groupBy([6.1, 4.2, 6.3], Math.floor);// => { '4': [4.2], '6': [6.1, 6.3] }// The `_.property` iteratee shorthand._.groupBy(['one', 'two', 'three'], 'length');// => { '3': ['one', 'two'], '5
javascript Array groupBy javascript中如何根据列表元素中的某个字段对列表进行分组操作?
文章目录 Introdemo参考 Intro 完整描述:SQL中有 group by xxx 的筛选方式。而在 javascript 中,如何实现以下需求? 根据某个列表元素中的某个条件(可能是多个字段),将列表中的元素分成几组。 目前(2024-06-09) javascript 的 Array 类型还没有对外提供类似于 groupby 的方法。 所以我们只能自己实现了。
Python基础操作之模块 -- pandas之groupby函数
groupby函数是pandas库中一个非常强大的功能,它允许你根据一个或多个列的值对DataFrame或Series进行分组,并对每个组执行各种聚合操作。 目录 示例详解 1. 导入必要的库和创建DataFrame 2. 使用groupby函数进行分组 3. 遍历分组并查看内容 4. 对分组执行聚合操作 5. 同时对多个列进行聚合操作 总结 示例详解
Flink DataSet first groupBy sortGroup 用法 实例
public class CoGroupDataSetTest {public static void main(String[] args) throws Exception {ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();//注意:可启用这行代码看区别//env.setParallelism

【数据分析面试】34.填充NaN值 (Python:groupby/sort_value/ffill)
题目:填充NaN值 (Python) 给定一个包含三列的DataFrame:client_id、ranking、value 编写一个函数,将value列中的NaN值用相同client_id的前一个非NaN值填充,按升序排列。 如果不存在前一个client_id,则返回前一个值。 输入: print(clients_df) client_idrankingvalue10011100
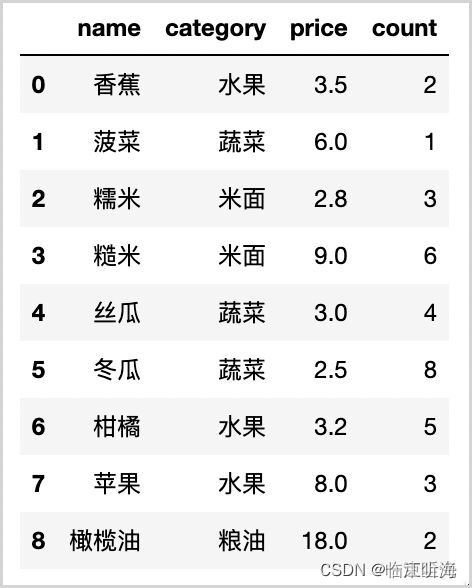
深入理解 Pandas 中的 groupby 函数
groupby 函数是 pandas 库中 DataFrame 和 Series 对象的一个方法,它允许你对这些对象中的数据进行分组和聚合。下面是 groupby 函数的一些常用语法和用法。 对于 DataFrame 对象,groupby 函数的语法如下: DataFrame.groupby(by=None, axis=0, level=None, as_index=True,sort=Tru
Hive - hive.groupby.skewindata环境变量与负载均衡
HiveQL 去重操作 和SQL一样,HiveQL中同样支持DISTINCT操作,如下示例: (1) SELECT count(DISTINCT uid) FROM log (2) SELECT ip, count(DISTINCT uid) FROM log GROUP BY ip (3) SELECT ip, count(DISTINCT uid, uname) FROMlog
pandas.dataframe.groupby做量化知道这些就够了
pandas.DataFrame.groupby官方文档 DataFrame.groupby(by=None, axis=0, level=None, as_index= True, sort=True, group_keys=True, squeeze=False, observed=False, **kwargs)# return DataFrame

ibatis resultMap groupBy属性使用
最近开始转用j2ee做开发,使用的数据持久层是iBatis。 在iBatis中要解决1:N、M:N问题必须要使用到resultMap,但使用过程中会遇到一个问题,就是groupBy的不能继承问题。现在举个例子向大家介绍一下这个问题和解决方法。 问题描述: 考虑一下这种情况,假如一家公司为了员工福利决定搞业余运动俱乐部,员工可以自由报名。运动的种类根据部门决定,这样就有了四个实体,公司,部门,
pandas中Groupby对象的agg()方法和apply()方法之decimal对象的聚合处理
DataFrame对象的groupby()方法是很有用的分组方法,其返回一个Groupby对象,Groupby对象有两个比较常用的用以传入聚合运算的方法,agg()和apply(),一般来说,agg()方法是比apply()方法更全面有效的,因为agg()方法中的参数更多样化,可以对不用的列指定不同的聚合函数,以字典的形式传入就行,即agg(dict),dict={‘column_n
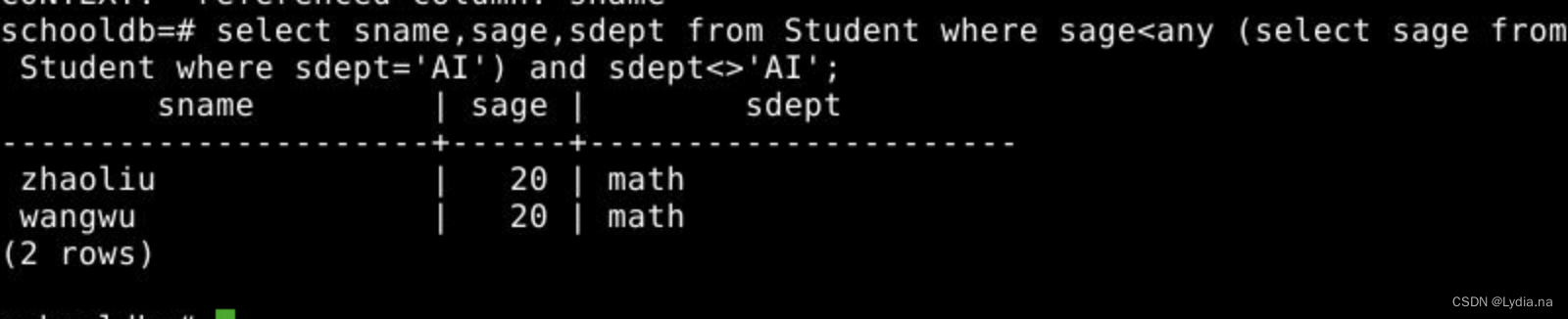
【数据库】实验五 数据库综合查询|多表查询、聚集函数、orderby、groupby
文章目录 参考文章 本文在实验四的基础上增加了orderby、聚集函数、groupby、多表查询的知识点,相较于上一次实验的难度变大了,嵌套表达更多了,逐渐开始套娃…… 其实可以看成一个偏正短语来拆分,再写成SQL语句,比如查询一个年龄大于20的学生成绩,那么学生成绩就为中心语,年龄大于20则作为修饰语,将中心语放至select ...from之间,依次类推进行分析。 查询‘
【Python】进阶学习:pandas--groupby()用法详解
📊【Python】进阶学习:pandas–groupby()用法详解 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程👈 希望得到您的订阅和支持~ 💡 创作高质量博文(平均质量分92+),分享更多关于深度学习、PyTorch、Python领域的优质内容!(希望得到您的关注~)
hive.groupby.skewindata与负载均衡
Group By 语句 1.Map 端部分聚合: 并不是所有的聚合操作都需要在 Reduce 端完成,很多聚合操作都可以先在 Map 端进行部分聚合,最后在 Reduce 端得出最终结果。 基于 Hash 参数包括: hive.map.aggr = true 是否在 Map 端进行聚合,默认为 True hive.groupby.mapaggr.checkinterval = 1
【附代码】Python Excel合并单元格(OpenPyXL) Pandas.DataFrame groupby样式保存xlsx
文章目录 相关文献Excel合并单元格并居中Pandas.DataFrame groupby样式保存Excel 作者:小猪快跑 基础数学&计算数学,从事优化领域5年+,主要研究方向:MIP求解器、整数规划、随机规划、智能优化算法 如有错误,欢迎指正。如有更好的算法,也欢迎交流!!!——@小猪快跑 相关文献 openpyxl - A Python library to
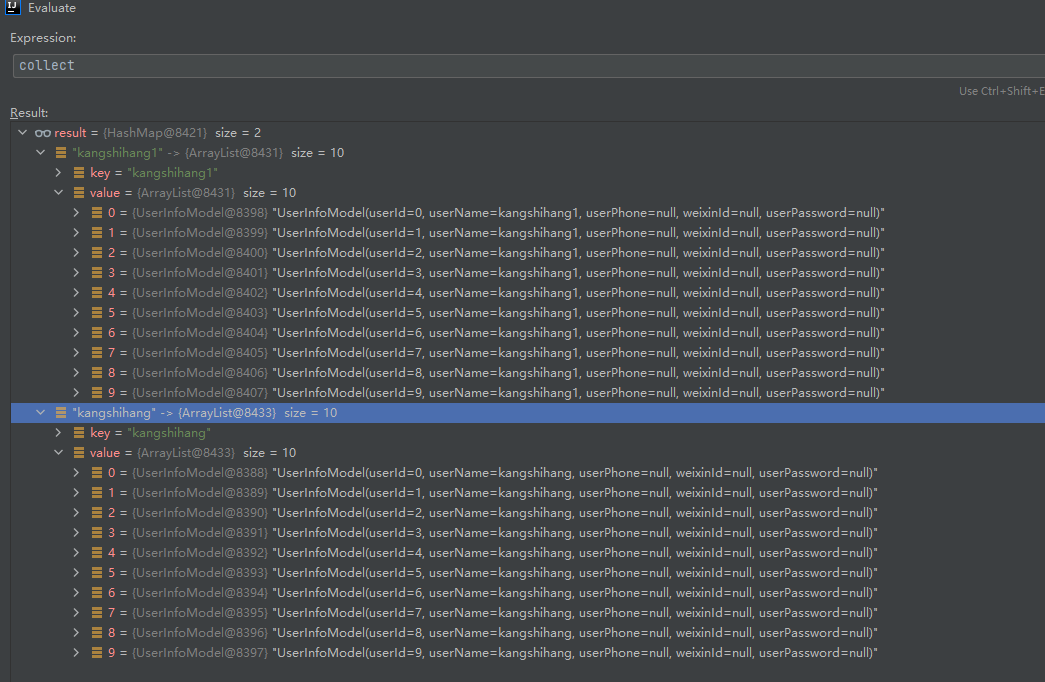
Java8-Stream 流基本应用-groupBy进行分组
groupBy进行分组 @Testpublic void testStreamGroupBy(){List<UserInfoModel> result=new ArrayList<>();for (int i = 0; i < 10; i++) {UserInfoModel user=new UserInfoModel();user.setUserId(i+"");user.setUserNam
lodash 的 _.groupBy 函数是怎么实现的?
说在前面 🎈lodash的_.groupBy函数可以将一个数组按照给定的函数分组,返回一个新对象。该函数接收两个参数:第一个参数是要进行分组的数组,第二个参数是用于分组的函数。该函数会对数组中的每个元素进行处理,返回一个值作为分组依据。最终返回的对象中,每个键代表一组,对应的值则是符合该组的元素组成的数组。 .groupBy函数的主要作用是方便对数组中的元素进行分类或分组,并且在分组
pandas中groupby分组后常用操作
groupby对象转化为DataFrame类型 将groupby的某个特征赋给一个新的groupby对象group,用group.values得到一个数组,再将数组用array.tolist()方法转化为列表,再用列表作为参数传入pd.Series()方法中 ` datarqq=datar[‘distance_div’].groupby(datar[‘消费者编号’]) datarqqq=dat
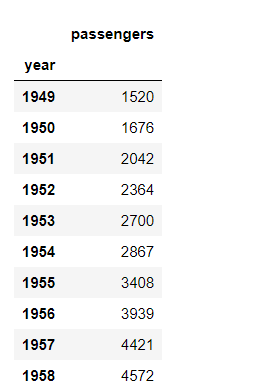
Python中Pandas基于Groupby可能会产生复合索引的问题
在Python中,基于Pandas对数据进行处理时,Groupby能够方便的对数据进行分类统计。但是,groupby操作后可能会产生复合索引,这个问题会导致数据无法提取。 例如以下问题:有一个航班数据,如下图 这个航班数据需要按照年份统计,从而能够得到每年的乘客数量变化情况,因此,我首先读入数据: import numpy as npimport pandas as pdimport