本文主要是介绍Python中Pandas基于Groupby可能会产生复合索引的问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在Python中,基于Pandas对数据进行处理时,Groupby能够方便的对数据进行分类统计。但是,groupby操作后可能会产生复合索引,这个问题会导致数据无法提取。
例如以下问题:有一个航班数据,如下图
这个航班数据需要按照年份统计,从而能够得到每年的乘客数量变化情况,因此,我首先读入数据:
import numpy as np import pandas as pd import matplotlib import matplotlib.pyplot as plt
data = pd.read_csv('flights.csv')
紧接着,我基于groupby对数据按照年份进行汇总,并求和,代码如下
year_passengers = data.groupby('year').agg('sum')
这个时候我发现,我分组求和后的数据打印出来如下
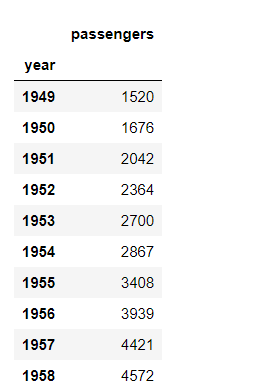
这时明显产生了复合索引,也就是我无法提取单列的数据,无法进行分析
实际上,我为了消除复合索引的影响,我只需要添加一个参数,就是在groupby函数中添加
year_passengers = data.groupby('year', as_index=False).agg('sum')
这样所产生的数据矩阵便可以自由提取数据
同时在知乎上也搜到同样问题:
Pandas如何将Series的复合索引提取为列?
使用Python的Pandas库处理数据,现在有一个DataFrame,比如TMP=DataFrame({'key1':['A','B','A','B'],'key2':['X','X','X','X'],'key3':[1,2,3,4]}),执行TMP=TMP.groupby(['key1','key2']).sum(),之后,会成为
key3
key1 key2
A X 4
B X 6
这样的一个有复合索引的Series,我如果想把它做成一个
key1 key2 key3
0 A X 4
1 B X 6
这样的DataFrame,我应该做什么操作呢?
能够得到答案:
TMP.groupby(['key1','key2'], as_index=False).sum()这篇关于Python中Pandas基于Groupby可能会产生复合索引的问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







