greenplum专题

【python 连接 Greenplum】python 连接Greenplum数据库
Python和PostgrelSQL进行交互,需要安装三方库,PostgrelSQL跟mysql 的用法类似 pip install psycopg2 例子: import psycopg2 import psycopg2.extras conn = psycopg2.connect(host='localhost', port=6432, user='postgres', passwo
Greenplum标量查询及常用示例
标量查询是指仅返回单个值的查询,而不是返回多行或多列的结果集。在Greenplum数据库中,标量查询通常用于获取单个值,以供其他查询、计算或条件判断使用。 以下是几个标量查询的示例: 1. 获取表中的最大值: SELECT MAX(column) FROM mytable; 2. 统计表中的行数: SELECT COUNT(*) FROM mytable; 3. 检查某个条件是否满

Greenplum集群或者Postgresql出现死锁肿么办?
1、Greenplum集群或者Postgresql出现死锁肿么办? 由于Postgresql和Greenplum集群这数据库知识很深的,没有仔细研究,遇到问题真的不知道肿么处理,我遇到死锁,是采取了暴力手段,直接杀锁了。 1 [biehl@cen-gp-master ~]$ sudo su 2 [sudo] password for biehl: 输入密码,看不见的。 3 [root
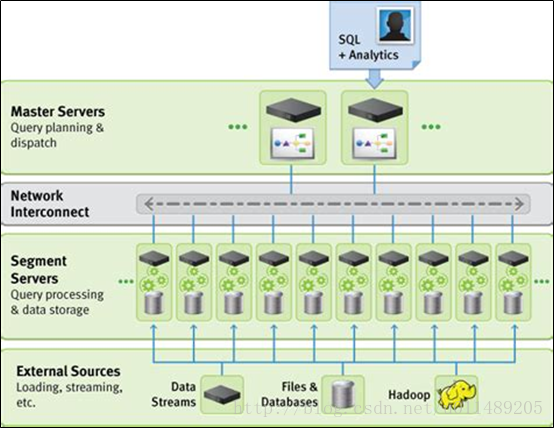
GreenPlum 开源,大规模并行查询平台
本博文主要介绍 GreenPlum 特点,核心组件以及底层架构 简介 世界上第一个开源,大规模并行数据平台。 GreenPlum 数据库是一个高级的,功能齐全的开源数据平台。它提供了PB级数据量上强大而快速的分析能力。GreenPlum 数据库是专为大数据分析业务设计。在大数据量上提供高性能的查询分析性能。 特点 底层基于PostgreSQL,但是GreenPlum数据库增加了大量并行分析

Greenplum 数据库初始化总是出现几个节点实例无法启动的问题
最近搭建GP20台节点环境时,发生初始化总是出现几个节点实例无法启动的问题。折腾两天,才找到问题。 初始化时,设置了最大连接数为100,每台机器运行12个实例,主备就是24个实例,初始化后有一部分实例正常启动,一部分失败。 根据日志找到失败节点目录下的日志,发现失败原因是由于硬件资源问题导致,提示是初始化最大连接数过大。机器的配置都是很高的,会出现这样的问题,很奇怪。 根据

【Greenplum】GP库 too many clients already错误,重启失败问题解决方案
问题描述: 连接数满了后,导致 gp库无法连接了,通过登录服务器,使用gpadmin用户进行重启操作,也报too many clients already,无法重启。 采用 psql -d postgres -U gpadmin 连接库,也报too many clients already,所有情况下都无法正常连接进gp库。 处理方法: 找出并杀死占用连接的进程 在gpadm

Greenplum技术浅析--vs oracle RAC
« 一地鸡毛 Oracle RAC廉价数据仓库解决方案 » Greenplum技术浅析 Published by jacky on 2009-07-24 in 大话技术 . Tags: Greenplum, ORACLE, 数据库. 说起Greenplum这个产品,最早是SUN来推他们的数据仓库产品DWA时接触到的,对这个由PgSQL堆叠出来的数据库

DolphinDB分区与MPP(Greenplum、AWS、Redshift)的区别
数据库架构 目前的商用服务器大体可以分为三类: 对称多处理器结构 (SMP : Symmetric Multi-Processor) ; 非一致存储访问结构 (NUMA : Non-Uniform Memory Access) ; 海量并行处理结构 (MPP : Massive Parallel Processing) 。 数据库架构设计中主要有: 一、Shared Everything Sh
GreenPlum介绍
【建立数据库连接】 只要兼容PostgreSQL client就能连GP。 如: psql 只能连master,segment是不接受连接的 连接参数如下: 连接参数 | 环境变量 | 缺省值 | 描述 ----------------------------------------------------------------------- Applicati
GreenPlum主要的功能和优势
基于软件,并针对商业硬件进行了优化 软件很容易安装到多家一级供应商提供的商业x86服务器上,并在Linux和Solaris上运行。 线性扩展性能 “完全不共享”体系和并行查询优化可以确保线性扩展性能和容量,将其扩展到成本上千个节点和处理器内核。 支持MapReduce MapReduce已经被Google和Yahoo等重要的互连网服务运营商证明是一种可行的大规模数据分析技术。借助
Greenplum缺点
说起Greenplum这个产品,最早是SUN来推他们的数据仓库产品DWA时接触到的,对这个由PgSQL堆叠出来的数据库产品还不是很了解,当时的焦点还在DWA本身的硬件上,当然不可否认,DWA还是有一些特点的。 后来,我们发现普通的PC+SAS磁盘具备非常好的吞吐能力,完全不逊于某些昂贵的存储设备。这样我们就尝试用PC+Greenplum搭建了一个 环境,效果完全超出了我们的预期,吞吐量完全超过了
oracle和greenplum的比较
Oracle RAC是Oracle Real Application Cluster的简写,官方中文文档一般翻译为“真正应用集群”,它一般有两台或者两台以上同构计算机及共享存储设备构成,可提供强大的数据库处理能力,现在是Oracle 10g Grid应用的重要组成部分。RAC(Race Game)指竞速类游戏 Oracle数据库的查询速度要比GP数据库的查询速度慢4倍左右 GP用1分钟查询

Greenplum 数据库架构分析
Greenplum 数据库是最先进的分布式开源数据库技术,主要用来处理大规模的数据分析任务,包括数据仓库、商务智能(OLAP)和数据挖掘等。自2015年10月正式开源以来,受到国内外业内人士的广泛关注。本文就社区关心的Greenplum数据库技术架构进行介绍。Pivotal开源了大规模并行处理数据仓库Greenplum Pivotal中国专区 一. Greenplum数据库简介 大数据是个炙手


greenplum 分布键选择
greenplum是基于postgre的数据库,最大的特征就是分布式,多节点(segment)。保存的数据会根据分布键存储到不同的节点上,用于查询或者关联。如果分布键选择得当,数据散列均匀,各个节点的数据量就会保持平衡,量级基本一致。如果选择不当就是导致数据倾斜,某一个节点数据量特别大。直接影响就是木桶效应,其他节点不工作,一个节点处理所有的数据,再提交给master,效率低下。理想状态下关
Greenplum-表空间笔记
Greenplum表空间 环境:http://blog.csdn.net/sunziyue/article/details/49026913 Greenplum创建表空间时,需要指定filespace。files

Greenplum-cc-web监控软件安装
一环境列表 操作系统 centos6.5 64 Greenplum版本: greenplum-db-4.3.5.3-build-2-RHEL5-x86_64.tar Greenplum集群环境搭建:参考http://blog.csdn.net/sunziyue/article/details/49026913 需求:在已经搭建的集群环境中安装Greenplum-cc-web 二操作步骤
Centos7安装Greenplum 6.13.0和PostGIS
Centos7安装Greenplum 6.13.0和PostGIS PostGIS版本和Greenplum版本配套关系: PostGIS 2.0.5 for Greenplum 4.3.x PostGIS 2.1.5 for Greenplum 5.11.3 PostGIS 2.1.5 for Greenplum 5.13.0? PostGIS 2.1.5 for Greenplum 5.16.
Greenplum-Spark连接器(GSC)简介
前言 我司算是Greenplum大户,虽然笔者不负责数仓,但是也少不得和它打交道。除了写pgSQL查询之外,Spark SQL能够使可用性更加丰富。Pivotal官方提供了Greenplum-Spark Connector(GSC)以打通GP和Spark,本文做个概述。 简单架构与配置 极简的架构图如下所示。 http://greenplum-spark.docs.pivot
Oracle数据迁移到GreenPlum
Oracle端表结构 SQL> select dbms_metadata.get_ddl('TABLE','TAB_ORA','ZWC') from dual;CREATE TABLE "ZWC"."TAB_ORA"( "ID" NUMBER,"OWNER" VARCHAR2(30),"NAME" VARCHAR2(128),CONSTRAINT "PK_ID" PRIMARY KEY

Spark——Spark读写Greenplum/Greenplum-Spark Connector高速写Greenplum
文章目录 问题背景解决方式代码实现Spark写GreenplumSpark读Greenplum 参考 问题背景 通过数据平台上的DataX把Hive表数据同步至Greenplum(因为DataX原生不支持Greenplum Writer,只能采用PostgreSQL驱动的方式),但是同步速度太慢了,<100Kb/s(DataX服务器和Greenplum服务器都在内网,实测服务器间
greenplum分区表查看所占空间大小
在使用greenplum数据库的时候,有的时候想要查看表所占用空间的大小,会使用如下二个函数pg_relation_size和pg_size_pretty. 前者用来查看数据大小,后者是human readable的调整.方法如下: select pg_size_pretty(pg_relation_size('relation_name')) ; select pg_

Greenplum性能优化analyze
为什么需要ANALYZE 首先介绍下RBO和CBO,这是数据库引擎在执行SQL语句时的2种不同的优化策略。 RBO(Rule-Based Optimizer) 基于规则的优化器,就是优化器在优化查询计划的时候,是根据预先设置好的规则进行的,这些规则无法灵活改变。举个例子,索引优先于扫描,这是一个规则,优化器在遇到所有可以利用索引的地方,都不会选择扫描。这在多数情况下是正确的,
Greenplum中的vacuum
vacuum,该选项主要是清理数据库表中的垃圾空间。 对于delete或update操作造成的实际物理空间没有从所对应的表中移除的话,vacuum操作可以将此磁盘释放出来,所以对那些经常性更新的表很有需要来做下vacuum操作。 -- 新建表open.t_ttt(20行数据)select count(1) from open.t_ttt;-- 20select pg_relati
Greenplum分布键选取策略
Greenplum由多个postgres组合而成,因此Greenplum属于分布式数据库,所以在创建数据表的时候需要指定分布键,当然在不指定的时候Greenplum数据库会默认使用使用表的第一个字段作为数据库的分布键。 Greenplum分布策略 (1)hash分布:选择一个列后者多个列作为数据表的分布键,通过hash计算,然后将插入的数据路由到特定的segment上; CREA