本文主要是介绍Greenplum-Spark连接器(GSC)简介,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
我司算是Greenplum大户,虽然笔者不负责数仓,但是也少不得和它打交道。除了写pgSQL查询之外,Spark SQL能够使可用性更加丰富。Pivotal官方提供了Greenplum-Spark Connector(GSC)以打通GP和Spark,本文做个概述。
简单架构与配置
极简的架构图如下所示。
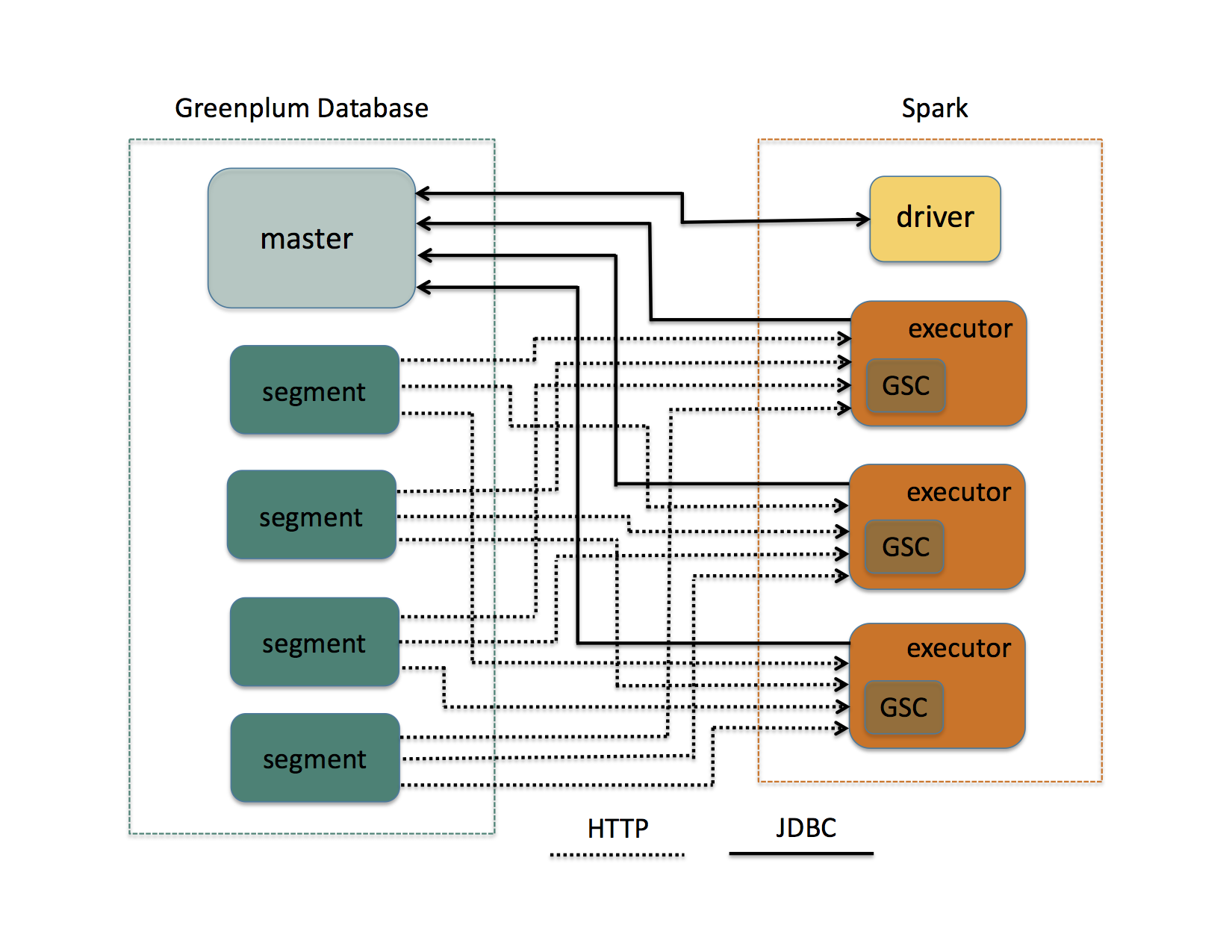
使用GSC访问GP数据库时,Spark Driver首先与GP Master连接,以获取数据库和表的元数据。读取或写入表时,每个GP Segment会对应到一个或多个Spark Task(即Partition),每个Partition会对应建立一个GP外部表(external table)作为传输数据的媒介。Spark Executor与GP Segment之间的HTTP通信是完全并行的。
要放心使用GSC,需要预先配置好Greenplum:
- 配置GSC使用的用户,并在pg_hba.conf中允许Spark集群各个节点与GP集群连接;
- 对GSC用户连接的各GP Schema授予USAGE和CREATE权限:
GRANT USAGE, CREATE ON SCHEMA <schema_name> TO <user_name>;
- 对GSC用户读写的各GP表授予SELECT和INSERT权限:
GRANT SELECT, INSERT ON <schema_name>.<table_name> TO <user_name>;
- 允许GSC用户使用gpfdist协议创建可写外部表(用于卸载表数据到Spark)和可读外部表(用于从Spark装载表数据):
ALTER USER <user_name> CREATEEXTTABLE(type = 'writable', protocol = 'gpfdist');
ALTER USER <user_name> CREATEEXTTABLE(type = 'readable', protocol = 'gpfdist');
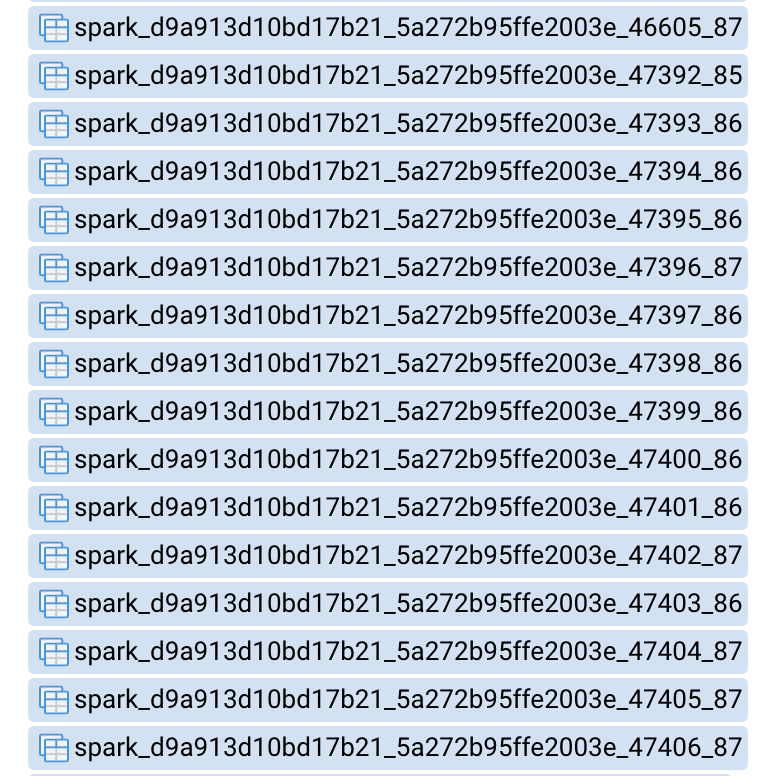
关于gpfdist和外部表的介绍请见这里,GP的外部表和Hive的外部表比较类似。GSC产生的外部表表名格式是spark_<app-specific-id>_<spark-node>_<num>,如下图所示。
在Spark App正常退出时,这些外部表会自动清理。如果App一直不终止(比如Streaming程序)或者异常终止,就需要我们手动drop掉那些不再使用的外部表:
DROP EXTERNAL TABLE <schema_name>.<external_table_name> CASCADE;
引入GSC JAR包到Maven项目
在Pivotal服务器上下载GSC JAR包。当前最新的版本为1.6.2,支持的GP版本为4.3.x、5.x和6.x,支持的Spark版本则为2.1.2及以上。
将下载好的greenplum-spark_2.11-1.6.2.jar放到项目中(如lib目录),然后修改pom文件添加依赖:
<scala.bin.version>2.11</scala.bin.version><gsc.version>1.6.2</gsc.version><dependency><groupId>io.pivotal.greenplum.spark</groupId><artifactId>greenplum-spark_${scala.bin.version}</artifactId><version>${gsc.version}</version><type>jar</type><scope>system</scope><systemPath>${basedir}/lib/greenplum-spark_${scala.bin.version}-${gsc.version}.jar</systemPath></dependency>
从GP读取数据
读取数据需要传入如下参数:
- url:连接GP数据库的JDBC串;
- dbschema:源表所在的Schema;
- dbtable:源表名;
- user:GSC用户名;
- password:用户对应的密码(可选);
- partitionColumn:表内分区列的列名。该列数据用来确定GP表的行如何划分到Spark Partition,所以要尽量保证均匀,防止数据倾斜。这一列的数据类型必须是integer、bigint、serial、bigserial四者之一;
- partitions:手动指定分区数(可选),如果不指定,默认分区数就是GP集群内主Segment的数量,当并行度不够时可以增大。
直接上示例代码吧。
val userInfoReadOptions = Map("url" -> "jdbc:postgresql://gp-master:5432/my_db","user" -> "lmagics","password" -> "changeme","dbschema" -> "cpts","dbtable" -> "app_user_info","partitionColumn" -> "user_id")val userInfoDf = session.read.format("greenplum").options(userInfoReadOptions).load()
然后就可以对产生的DataFrame进行操作了。
向GP写入数据
写入数据需要传入的参数与读取数据基本相同,只是不需要指定partitionColumn和partitions两个域,并多了一个truncate域。示例代码如下。
val userInfoWriteOptions = Map("url" -> "jdbc:postgresql://gp-master:5432/my_db","user" -> "lmagics","password" -> "changeme","dbschema" -> "cpts","dbtable" -> "app_user_info","truncate" -> "false")userInfoDf.write.format("greenplum").mode(SaveMode.Overwrite).options(userInfoWriteOptions).save()
若指定的表不存在,GSC会根据DataFrame中的各个字段名和数据类型自动创建表。Spark与GP数据类型的映射关系详见这里。
写入时建议调用mode()方法指定存储模式:
- Append:向表追加数据;
- Ignore:如果表已经存在,就忽略这批写入数据;
- Overwrite:如果表已经存在,就清空该表并写入目标数据。清空表的动作由上述truncate参数指定,false表示会drop掉表,并重新create之;true则表示执行truncate操作。
The End
民那晚安。
这篇关于Greenplum-Spark连接器(GSC)简介的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




