本文主要是介绍GreenPlum 开源,大规模并行查询平台,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本博文主要介绍 GreenPlum 特点,核心组件以及底层架构
简介
世界上第一个开源,大规模并行数据平台。
GreenPlum 数据库是一个高级的,功能齐全的开源数据平台。它提供了PB级数据量上强大而快速的分析能力。GreenPlum 数据库是专为大数据分析业务设计。在大数据量上提供高性能的查询分析性能。
特点
底层基于PostgreSQL,但是GreenPlum数据库增加了大量并行分析的创新设计。
(1) 大规模并行处理架构
GreenPlum 数据库架构提供了横向扩展,无共享体系结构的数据和查询并行化设计。
(2) PB规模数据加载
高性能加载使用MPP技术。加载速度随着增加节点而增加,每个机架每小时10TB以上
(3) 创新的查询优化器
GreenPlum 数据库提供的查询优化器是业界首个针对大数据工作负载而设计的基于成本的查询优化器。可以将交互式和批处理模式应用到PB级别的大型数据集上,但是不会降低查询性能和吞吐量
(4) 多态数据存储和执行
表或者分区存储,执行和压缩设置可以按照数据访问方式进行配置。用户为每个表或者分区选择面向行或者列的存储和处理。
(5) 高级的机器学习
由Apache MADlib提供,这是一个可扩展的数据库内分析库,通过用户定义的函数扩展了Greenplum 数据库的SQL功能
(6) 外部数据访问
通过外部表语法访问和查询所有数据, 支持传统的内部部署和下一代公共数据湖。
GreenPlum数据库是一个大规模并行处理(MPP)数据库服务器。其架构设计专门应用于管理大型分析数据仓库和商业BI工作。
核心概念
(1) MPP, Greenplum and Postgresql
MPP(也称为无共享体系架构)是指具有两个或者更多处理器的系统,它们协作执行操作,每个处理器都有各自的处理器,操作系统和磁盘。GreenPlum使用这种高性能系统架构来分配多TB数据仓库的负载,并且可以并行使用系统资源来处理查询操作。
GreenPlum数据库基于PostgreSQL开源技术。基本上是有几个PostgreSQL数据库实例组合在一起作为一个数据库管理系统。它基于PostgreSQL8.2.15,在大多数情况下,在SQL支持程度,功能和配置选项以及最终用户功能方面和PostgreSQL相似。数据库用户与普通PostgreSQL数据库管理系统交互和与GreenPlum数据库交互方式一致。
GreenPlum数据库底层的PostgreSQL内部已被修改或者补充来支持GreenPlum数据库的并行结构。例如,系统目录,优化器,查询执行器以及书屋管理器组件已被修改和增强,以便能够跨所有并行PostgreSQL数据库实例来同时执行查询操作。GreenPlum互联(网络层)支持不同PostgreSQL数据库实例之间的通讯,因为互联层的存在,系统可以作为一个逻辑数据库对外提供服务。
GreenPlum数据库还包括一些专为BI工作提供的优化设计,例如,GreenPlum添加了并行数据加载(外部表),资源管理,查询优化和存储增强,然而这些设计在标准的PostgreSQL数据库中并不存在。
(2) GreenPlum Architecture
GreenPlum数据库通过在多台服务器或者主机上分发数据和处理工作负载来存储和处理大量数据。GreenPlum由一组基于PostgreSQL8.2数据库实例协同工作对外提供单个数据库镜像。Master是GreenPlum数据库系统的入口,客户端连接Master数据库实例来提交SQL语句。Master节点协调系统中其他的数据库实例(称为段)来存储和处理数据。
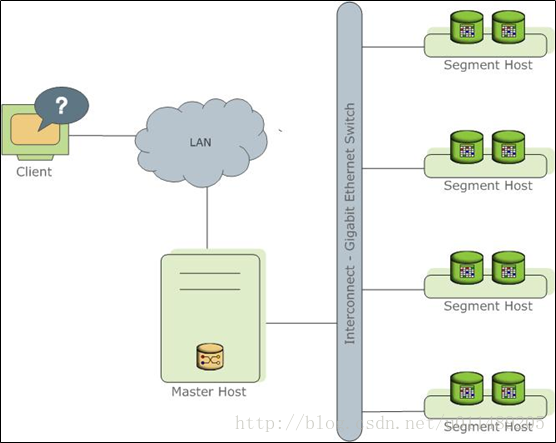
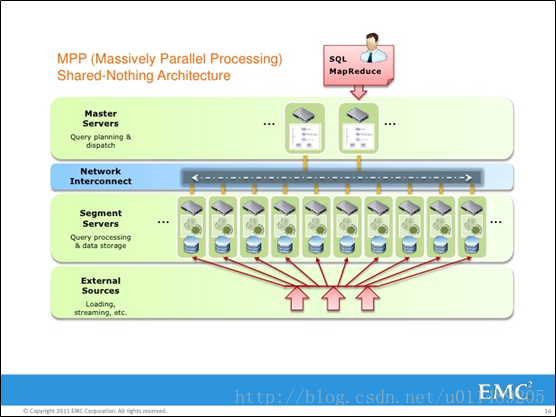
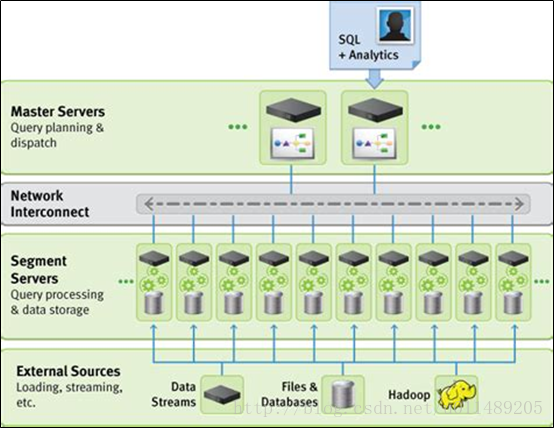
(3) GreenPlum Master
GreenPlum 数据库主节点是整个数据库系统的入口,接受客户端的连接和SQL查询,并将工作分配给别的数据库实例(这里指段数据库)
客户端通过Master访问GreenPlum数据库系统和连接PostgreSQL数据库一样。可以使用客户端程序(psql)或者应用程序编程接口(API)连接到数据库,比如如JDBC或者ODBC。
Master节点存储整个数据库系统的系统目录。系统目录包含有关Greenp数据库系统本身的元数据的系统表。Master节点不包含任何用户数据,数据只保存在段节点上。Master节点负责对客户端连接进行身份验证,处理接受的SQL命令,在段节点之间均衡负载,协调每个段节点返回的结果数据,并将最终结果呈现给客户端程序。
客户端通过Master访问GreenPlum数据库系统和连接PostgreSQL数据库一样。可以使用客户端程序(psql)或者应用程序编程接口(API)连接到数据库,比如如JDBC或者ODBC。
Master节点存储整个数据库系统的系统目录。系统目录包含有关Greenp数据库系统本身的元数据的系统表。Master节点不包含任何用户数据,数据只保存在段节点上。Master节点负责对客户端连接进行身份验证,处理接受的SQL命令,在段节点之间均衡负载,协调每个段节点返回的结果数据,并将最终结果呈现给客户端程序。
(4) GreenPlum Segments
GreenPlum 数据库段实例是独立的PostgreSQL数据库,每个数据库存储一部分数据并执行大部分查询处理。
当用户通过GreenPlum主服务器连接到数据库并发出查询时,每个段数据库会创建进程并处理基于自己本身数据集上的查询工作。
用户定义的表格及其索引分布在GreenPlum数据库系统的可用段中。每个段都包含数据的一个特定部分。段数据服务进程在相应的段节点实例中运行,用户通过Master与GreenPlum数据库系统进行交互。
段数据库服务运行在段主机上。一个段主机通常运行2-8个GreenPlum段,具体取决于CPU内核,RAM,存储和网络接口以及工作负载。段主机最好是相同的配置。将数据和工作负载均匀的分发到大量同等能力的段上,使得它们可以同时开始工作并同时完成工作,可以使得GreenPlum数据库系统的性能达到最佳状态。
当用户通过GreenPlum主服务器连接到数据库并发出查询时,每个段数据库会创建进程并处理基于自己本身数据集上的查询工作。
用户定义的表格及其索引分布在GreenPlum数据库系统的可用段中。每个段都包含数据的一个特定部分。段数据服务进程在相应的段节点实例中运行,用户通过Master与GreenPlum数据库系统进行交互。
段数据库服务运行在段主机上。一个段主机通常运行2-8个GreenPlum段,具体取决于CPU内核,RAM,存储和网络接口以及工作负载。段主机最好是相同的配置。将数据和工作负载均匀的分发到大量同等能力的段上,使得它们可以同时开始工作并同时完成工作,可以使得GreenPlum数据库系统的性能达到最佳状态。
(5) GreenPlum Interconnect
GreenPlum Interconnect是GreenPlum数据库体系结构的网络层。
互联是指段和网络基础设施之间通信依赖的进程间通信,GreenPlum互联使用标准的万兆以太网交换结构。
默认情况下,互联使用UDP协议通过网络发送消息。GreenPlum提供的数据库校验超过了UDP默认提供的,这就意味着可靠性等同于TCP,性能和扩展性超过了TCP。如果互联使用TCP,GreenPlum数据库系统只能最大支持1000个分段实例。使用UDP作为互联目前默认的协议,这样段实例的数量不受限制。
互联是指段和网络基础设施之间通信依赖的进程间通信,GreenPlum互联使用标准的万兆以太网交换结构。
默认情况下,互联使用UDP协议通过网络发送消息。GreenPlum提供的数据库校验超过了UDP默认提供的,这就意味着可靠性等同于TCP,性能和扩展性超过了TCP。如果互联使用TCP,GreenPlum数据库系统只能最大支持1000个分段实例。使用UDP作为互联目前默认的协议,这样段实例的数量不受限制。
(6) Pivotal 查询优化器
和其他查询优化器不同的是,Pivotal查询优化器为GreenPlum提供了比较高级的查询优化框架。具体表现在以下几个方面:
模块化
Pivotal查询优化器使用并不局限于单个关系型数据库中。目前在GreenPlum数据库和Pivotal的HAWQ中都有使用,Pivotal的查询优化器可以作为独立的组件运行,在对应新的后端系统以及将优化器作为服务部署而言极具灵活性。这也使得我们可以绕过数据库栈其他组件对优化器进行精确测试。
可扩展性
Pivotal的查询优化器被设计为独立组件的集合,可以分别替换,配置和扩展。这显著降低了添加新功能的开发成本,而且可以快速采用新兴技术。在查询优化器内部,查询元素的表示和查询优化的方式是分开的,这使得优化程序可以平等的对待所有元素,这样可以避免在多优化任务中因为优化步骤的强制顺序带来的问题。
性能
Pivotal查询优化器利用多喝跳读程序,可以将优化任务分配给多个核执行来加速优化过程。
这允许查询优化器同时应用所有可能的优化,从而产生更多可以选择的计划以及更广的优化查询的范围。比如,当Pivotal查询优化器和TPC-H Query21一起使用的时候,它可以在250ms内产生12亿个可能的计划。这在大数据分析中尤为重要,极大提升了大数据处理的性能,不理想的优化选择可能会导致一个查询永远被执行下去。
模块化
Pivotal查询优化器使用并不局限于单个关系型数据库中。目前在GreenPlum数据库和Pivotal的HAWQ中都有使用,Pivotal的查询优化器可以作为独立的组件运行,在对应新的后端系统以及将优化器作为服务部署而言极具灵活性。这也使得我们可以绕过数据库栈其他组件对优化器进行精确测试。
可扩展性
Pivotal的查询优化器被设计为独立组件的集合,可以分别替换,配置和扩展。这显著降低了添加新功能的开发成本,而且可以快速采用新兴技术。在查询优化器内部,查询元素的表示和查询优化的方式是分开的,这使得优化程序可以平等的对待所有元素,这样可以避免在多优化任务中因为优化步骤的强制顺序带来的问题。
性能
Pivotal查询优化器利用多喝跳读程序,可以将优化任务分配给多个核执行来加速优化过程。
这允许查询优化器同时应用所有可能的优化,从而产生更多可以选择的计划以及更广的优化查询的范围。比如,当Pivotal查询优化器和TPC-H Query21一起使用的时候,它可以在250ms内产生12亿个可能的计划。这在大数据分析中尤为重要,极大提升了大数据处理的性能,不理想的优化选择可能会导致一个查询永远被执行下去。
参考:GreenPlum 官网
这篇关于GreenPlum 开源,大规模并行查询平台的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






