gbdt专题

机器学习学习--Kaggle Titanic--LR,GBDT,bagging
参考,机器学习系列(3)_逻辑回归应用之Kaggle泰坦尼克之灾 http://www.cnblogs.com/zhizhan/p/5238908.html 机器学习(二) 如何做到Kaggle排名前2% http://www.jasongj.com/ml/classification/ 一、认识数据 1.把csv文件读入成dataframe格式 import pandas as

集成学习之GBDT、XGBOOST、RF
GBDT&&XGBOOST 都属于GBM(GradientBoosting Machine)方法,传统GBDT以CART(分类回归树)作为基分类器,利用损失函数的负梯度方向在当前模型的值作为残差的近似值,可以说在RF的基础上又有进一步提升,能灵活的处理各种类型的数据,在相对较小的调参时间下,预测的准确度较高。 XGBOOST基学习器除了树,还支持线性分类器;XGBOOST在代价函数中加入了

GBDT与LR融合方案
GBDT与LR融合方案--CTR预估 转载原文:https://blog.csdn.net/lilyth_lilyth/article/details/48032119 1、 背景 CTR预估(Click-Through Rate Prediction)是互联网计算广告中的关键环节,预估准确性直接影响公司广告收入。CTR预估中用的最多的模
对比分析:GBDT、XGBoost、CatBoost和LightGBM
对比分析:GBDT、XGBoost、CatBoost和LightGBM 梯度提升决策树(GBDT)是当前机器学习中常用的集成学习方法之一,它通过集成多个弱学习器(通常是决策树)来构建强学习器。GBDT在分类和回归任务中表现优异,并在许多机器学习竞赛中频频获胜。随着算法的发展,GBDT衍生出了多种实现,其中以XGBoost、CatBoost和LightGBM最为知名。本文将详细介绍这四种算法的特点

Random Forest GBDT XGBOOST LightGBM面试问题整理
一.知识点 二.特征重要性评估 基于树的集成算法有一个很好的特性,就是模型训练结束后可以输出模型所使用的特征的相对重要性,便于理解哪些因素是对预测有关键影响,有效筛选特征。 Random Forest 袋外数据错误率评估 由于RF采用bootstrapping有放回采样, 一个样本不被采样到的概率为 limm→∞(1−1m)m=1e≈0.368 lim m → ∞
决策树算法系列——GBDT
参考链接: http://blog.csdn.net/dark_scope/article/details/24863289 http://blog.csdn.net/w28971023/article/details/8240756

手推 GBDT与xgboost
先说结论: GBDT与xgboost的主要区别是GBDT利用的一阶导数的思想去拟合每棵树,xgboost利用二阶导数思想去拟合每棵树。 另外xgboost还加入了其他许多技巧,比如xgboost加入和正则项是模型泛化能力更强;同时xgboost还支持并行计算(每棵树还是串行,并行是特征维度的并行);xgboost在训练完一棵树后都会为其叶子节点的分数乘以一个缩减权重(shrinkage)。来给后
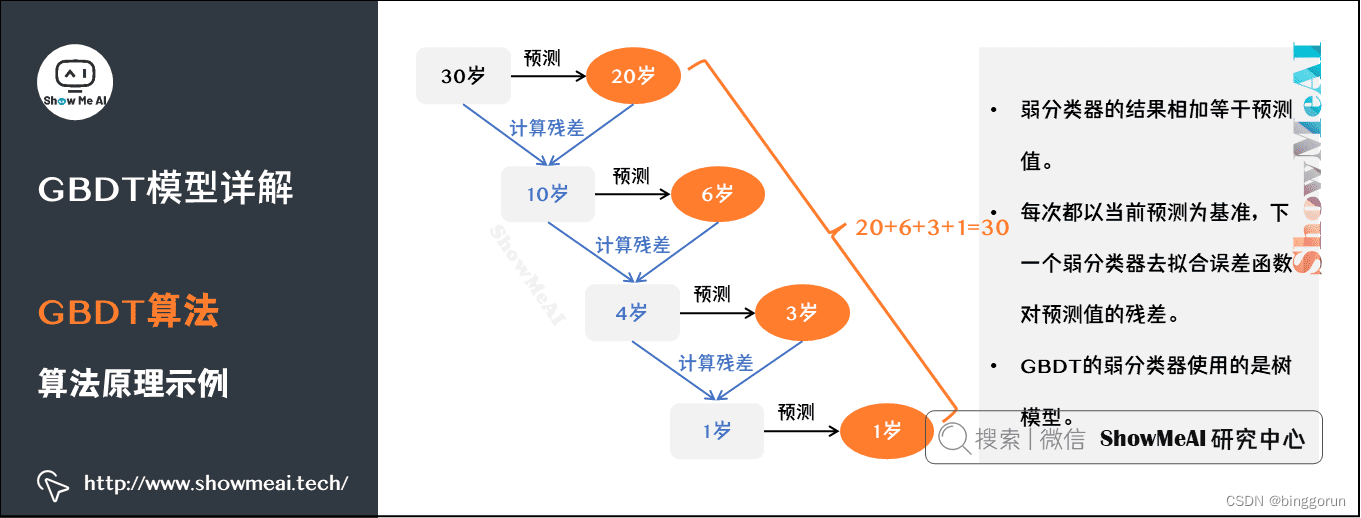
梯度提升决策树(GBDT)
GBDT(Gradient Boosting Decision Tree),全名叫梯度提升决策树,是一种迭代的决策树算法,又叫 MART(Multiple Additive Regression Tree),它通过构造一组弱的学习器(树),并把多颗决策树的结果累加起来作为最终的预测输出。该算法将决策树与集成思想进行了有效的结合。 原理 GBDT的核心思想是将多个弱学习器(通常是决策树)组合成一

GBDT的优势:为什么选择梯度提升决策树
GBDT的优势:为什么选择梯度提升决策树 在机器学习的众多算法中,GBDT(Gradient Boosting Decision Tree,梯度提升决策树)因其在各类回归和分类任务中的卓越表现而备受关注。GBDT不仅在各种竞赛中屡获佳绩,还被广泛应用于实际业务中,如推荐系统、搜索排序和金融风险评估等。本文将深入解析GBDT的工作原理、实现方法及其在实际中的应用。 1. GBDT简介 GBDT
深度理解梯度提升树GBDT
1.什么是提升树? 提升树核心思想是使用残差使损失函数最小,每一次使用树模型拟合残差。最终预测值y是M个树模型的累加和 提升树模型如下 是决策时,是决策树的参数,M是决策树的个数 提升树通用算法过程如下: 输入: i=1...N 样本数据,L(y,f(x)) 损失函数 输出:提升树 算法流程 1.初始化 2.对m=1,2...M (遍历M个提升树)

《机器学习技法》学习笔记11——GBDT
http://blog.csdn.net/u011239443/article/details/77435463 Adaptive Boosted Decision Tree 关于AdaBoost、提升树可先参阅:http://blog.csdn.net/u011239443/article/details/77294201 这里仅对其做一定的补充。 对提升决策树桩的模型中,我们对树的节点

CART,GBDT,XGBoost
回归树=》GBDT=》XGBoost 回归树(Reression Decision Tree) 一个例子 训练数据中臂长,年龄,体重为特征变量X,身高为标签值Y,下面开始种树 臂长(m)年龄(岁)体重(kg)身高(m)(标签值)0.55201.10.77301.30.921701.7 回归树算法流程 补充: 梯度提升树( Gradient Boosting Deci
GBDT中残差和梯度的关系
采用Square loss为损失函数时,负梯度和残差相等。不过,当我们采用Absolute loss/Huber loss等其它损失函数时,负梯度只是残差的近似。 转自 http://aandds.com/blog/ensemble-gbdt.html

GBDT调参--贝叶斯调参
随机抽特征和随机抽样本 n_estimators 是控制森林中树木的数量,即基评估器的数量。这个参数对随机森林模型的精确性影响是单调的,n_estimators越 大,模型的效果往往越好。但是相应的,任何模型都有决策边 n_estimators达到一定的程度之后,随机森林的 精确性往往不在上升或开始波动,并且,n_estimators越大,需要的计算量和内存也越大,训练的时间也会越来越
【机器学习】集成学习:一文弄懂GBDT算法原理和实现
GBDT是一种集成学习算法,属于Boosting类型,通过叠加多个决策树的预测结果得出最终的预测结果。这个算法是很多算法的基石,比如生产中常用的XGBoost算法和LightGBM算法。GBDT算法的原理和实现比较简单,本文接下来将进行详细阐述。 文章目录 一、名词解释二、GBDT算法原理详解1 GBDT算法原理理解简单案例2 GBDT算法原理公式推导2.1 基学习器2.2 损失函数3.3
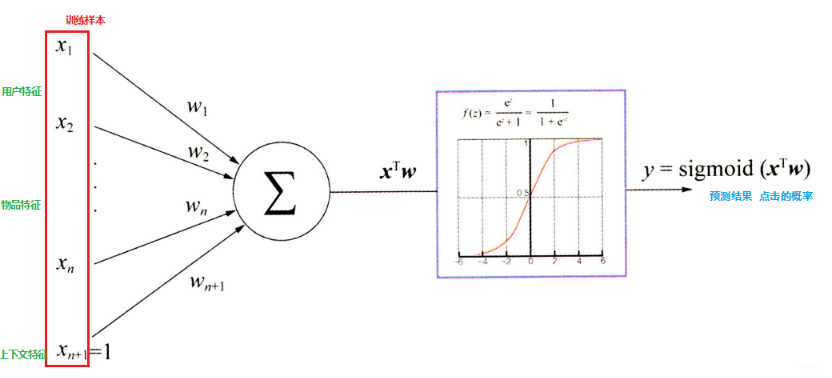
逻辑回归模型与GBDT+LR——特征工程模型化的开端
随着信息技术和互联网的发展, 我们已经步入了一个信息过载的时代,这个时代,无论是信息消费者还是信息生产者都遇到了很大的挑战: 信息消费者:如何从大量的信息中找到自己感兴趣的信息?信息生产者:如何让自己生产的信息脱颖而出, 受到广大用户的关注? 为了解决这个矛盾, 推荐系统应时而生, 并飞速前进,在用户和信息之间架起了一道桥梁,一方面帮助用户发现对自己有价值的信息, 一方面让信息能够展现在对它感
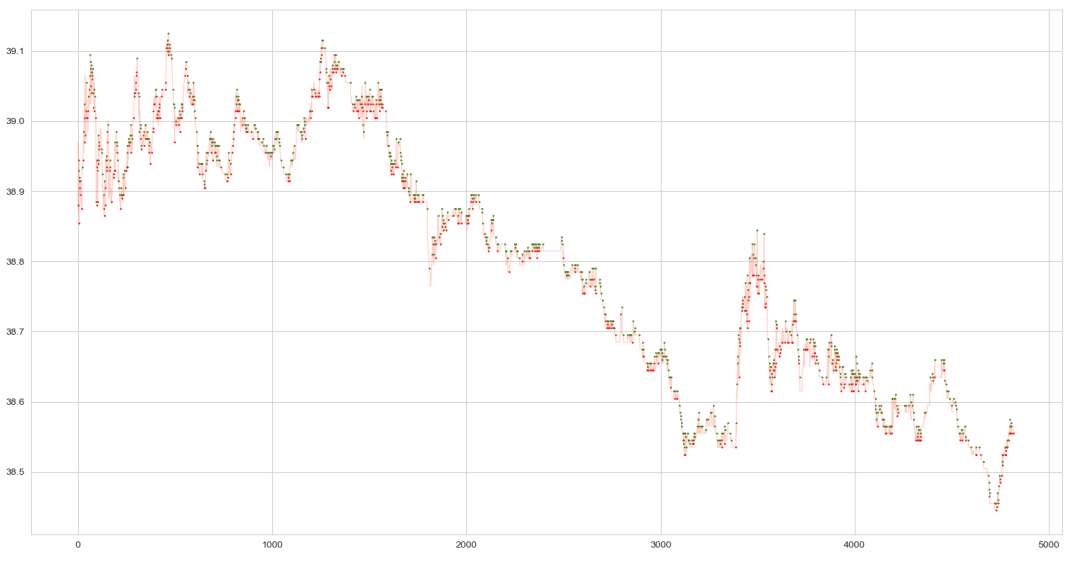
【高频】基于GBDT-FM模型的level-2高频数据实证研究(二)
【高频】基于GBDT-FM模型的level-2高频数据实证研究(二) 原创 Yud. 2AMquant 2024-04-04 11:30 广东 上一篇中初步提及了Level2数据中常见变量指标的构建方式,以及其带来的价格冲击。此篇将使用GBDT-LM模型对短程价格走势进行简单预测。 ps:此篇创作内容已于2020年10月9日发布在https://zhuanlan.zhihu
scikit-learn 梯度提升树(GBDT) 参数
1. scikit-learn GBDT类库概述 在sacikit-learn中,GradientBoostingClassifier为GBDT的分类类, 而GradientBoostingRegressor为GBDT的回归类。两者的参数类型完全相同,当然有些参数比如损失函数loss的可选择项并不相同。这些参数中,类似于Adaboost,我们把重要参数分为两类,第一类是Boosting框
[机器学习] 第八章 集成学习 1.Boosting(GBDT Adaboost Xgboost) Bagging(随机森林)
https://www.cnblogs.com/techflow/p/13445042.html 文章目录 一、Boosting ↓bias1. GBDT回归(划分结点:mse)1.1 Regression Decision Tree:回归树1.2 Boosting Decision Tree:提升树算法1.3 Shrinkage (避免GBDT过拟合,学习率) 2. GBDT分类(划分结点
![[转载]决策树模型组合之随机森林与GBDT](https://pic.xiahunao.cn/getimgs/?img=http://images.cnblogs.com/cnblogs_com/LeftNotEasy/201103/20110307235312285.png)
[转载]决策树模型组合之随机森林与GBDT
本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使用,但请注明出处,如果有问题,请联系wheeleast@gmail.com。也可以加我的微博: @leftnoteasy 前言: 决策树这种算法有着很多良好的特性,比如说训练时间复杂度较低,预测的过程比较快速,模型容易展示(容易将得到的决策树做成图片展示出来)等
LR+GBDT的工作原理
简介 因为梯度提升树训练过于复杂,而逻辑回归过于简单,只能发现线性简单,而对于交互项和非线性关系没有辨识度。 于是用梯度提升树训练模型,基于树模型,就有了交叉和非线性,然后把叶子节点放到逻辑回归模型里,解决了逻辑回归算法的缺点。 简单来说,就是将梯度提升树的输出作为逻辑回归的输入,最终得到逻辑回归模型。 如梯度提升树中有三棵树, T 1 T_1 T1、 T 2 T_2 T2和 T 3 T

经典机器学习模型(八)梯度提升树GBDT详解
经典机器学习模型(八)梯度提升树GBDT详解 Boosting、Bagging和Stacking是集成学习(Ensemble Learning)的三种主要方法。 Boosting是一族可将弱学习器提升为强学习器的算法,不同于Bagging、Stacking方法,Boosting训练过程为串联方式,弱学习器的训练是有顺序的,每个弱学习器都会在前一个学习器的基础上进行学习,最终综合所有学习器的预测

机器学习模型——GBDT和Xgboost
GBDT基本概念: GBDT(Gradient Boosting Decision Tree,简称GBDT)梯度提升决策树,是Gradient Boost 框架下使用较多的一种模型,且在GBDT中,其基学习器是分类回归树也就是CART,且使用的是CART树中的回归树。 GBDT这个算法还有一些其他的名字, MART(Multiple Additive Regression Tree),GBRT

机器学习算法GBDT总结上
机器学习算法GBDT的面试要点总结-上篇 1.简介 网址: https://www.cnblogs.com/ModifyRong/p/7744987.html gbdt全称梯度下降树,在传统机器学习算法里面是对真实分布拟合的最好的几种算法之一,在前几年深度学习还没有大行其道之前,gbdt在各种竞赛是大放异彩。原因大概有几个,一是效果确实挺不错。二是即可以用于分类也可以用于回归。

机器学习——GBDT算法
机器学习——GBDT算法 在机器学习领域,梯度提升决策树(Gradient Boosting Decision Trees,简称GBDT)是一种十分强大且常用的集成学习算法。它通过迭代地训练决策树来不断提升模型性能,是一种基于弱学习器的提升算法。本文将详细介绍梯度提升树算法的原理,并与随机森林进行对比,最后给出Python实现的示例代码和总结。 1. 提升树模型 提升树模型是一种基于决策树的
梯度提升算法(GBDT)
GBDT(Gradient Boosting Decision Tree)算法是集成算法中的一种,它的最基本分类器为CART二分类回归树,集成方式为梯度提升。 CART二分类回归树 CART回归树是GBDT算法的最基本分类器,CART回归树决定了每次分类时,叶子结点只能分出两个树枝,它与ID3,C4.5是不同的。 CART回归树经常涉及到的一些问题: 选择哪个特征作为最优分裂特征? 怎么去切分一