forests专题

基于Python的机器学习系列(14):随机森林(Random Forests)
简介 在上一节中,我们探讨了Bagging方法,并了解到通过构建多个树模型来减少方差是有效的。然而,Bagging方法中树与树之间仍然可能存在一定的相关性,降低了方差减少的效果。为了解决这个问题,我们引入了随机森林(Random Forests),这是一种基于Bagging的增强技术,通过在每个树的每个分割点上随机选择特征来进一步减少树之间的相关性。 1. Out of Bag

Backtracking Regression Forests for Accurate Camera Relocalization
这种方法其实类似 deep learning,只不过是以森林的方式进行train,森林是由一系列的决策树组成。 每个决策树中的每个节点都是待训练的参数: 决策树的目的是: ,即输入是image,depth(如果有的话),2d pixel位置,输出是3d点的位置x y z + 最终的feature。因此决策树可以认为是一个从2d到3d的映射,这样的话就导致 每个场景就需要

6、随机森林(Random forests)
Random forests started a revolution in machine learning 20 years ago. For the first time, there was a fast and reliable algorithm which made almost no assumptions about the form of the data, an

R语言 random forests 高性能库
最忠实Leo Breiman算法的版本是 randomForest,但是这个库不支持并行,性能也比较差。 有两个优化后的替代版本,都支持并行计算。 rangerrborist
Ensemble Learning(Trees, Forests, Bagging, Boosting)
1.概述 有监督学习任务中,对于一个相对复杂的任务而言,我们的目标是学习出一个稳定且在各个方面表现都较好的模型,但实际情况往往不会如此理想,有时只能得到多个有偏好的模型(弱监督模型或弱可学习weakly learnable模型)。集成学习就是组合这里的多个弱可学习模型得到一个更好更全面的强可学习 strongly learnable模型,集成学习潜在的思想是即便某一个弱学习器得到了错误的预测,其

Deep Neural Decision Forests
Deep Neural Decision Forests 当小w还是一名研一的小学生时,就对所谓的数据挖掘十分感兴趣,当时就想,通过这个玩意就能让机器知道连我都不了解我的东西,确实十分神奇。奈何研二导师离职(是不是很悲剧。。。),就到隔壁组去做深度学习了,哎~,发现深度学习竟然比数据挖掘更吊。。。(因为以前认知的数据挖掘都要自己去提取特征然后扔给RF,SVM等等,但是CNN完全End2End连提

决策树和随机森林(Decision Trees and Random Forests)
1. 基本概念 学习分类:基于树的算法被认为是最好的,最常用的监督学习方法之一优势: 基于树的算法使预测模型具有较高的准确性,稳定性和易解释性与线性模型不同,它们很好地映射了非线性关系 用途 解决分类问题(classification:categorical variables )解决回归问题(regression:continuous variables ) 缩略语 缩写描述含义MSEMea

应用隐类霍夫森林:Latent-Class Hough Forests for 3D Object Detection and Pose Estimation(笔记)——2014
应用隐类霍夫森林进行3D目标检测和姿态估计(笔记)——2014 Latent-Class Hough Forests for 3D Object Detection and Pose Estimation 摘要 文章提出隐类霍夫森林框架,在高杂波和遮挡环境中进行3D目标检测和姿态估计。将LINEMOD法引入一个尺度不变的patch描述符中,并使用一个新的基于模板的分割函数将其集成到回归森林中

Forests of randomized trees
sklearn.ensemble模块包括两个基于随机决策树的算法:随机森林算法和树外方法。这些算法是特别对于树的扰动与结合技术。这就意味着多种分类器的集合通过在分类器构建过程中引入随机项而被构建。这种集成的预测通过个体的分类的平均预测。 像其它分类器一样,森林分类器必须拟合两个矩阵:大小为[n_samples, n_features]的X(包含训练样本),大小为[n_samples]的Y,包含训

Bagging决策树:Random Forests
1. 前言 随机森林 Random Forests (RF) 是由Breiman [1]提出的一类基于决策树CART的集成学习(ensemble learning)。论文 [5] 在121数据集上比较了179个分类器,效果最好的是RF,准确率要优于基于高斯核SVM和多项式LR。RF自适应非线性数据,不易过拟合,所以在Kaggle竞赛大放异彩,大多数的wining solution都用到了RF。


2020牛客暑期多校训练营Valuable Forests(动态规划,组合数学,prufer序列)
Valuable Forests 题目描述 输入描述: 输出描述: 示例1 输入 5 1000000007 2 3 4 5 107 输出 2 24 264 3240 736935633 题目大意 给定 n n n个节点,求这些节点组成的森林的所有可能中每个点的度的平方和。 要求答案 m o d mod mod给定的模数 M M M。 分析 分析这题,发现难点在于
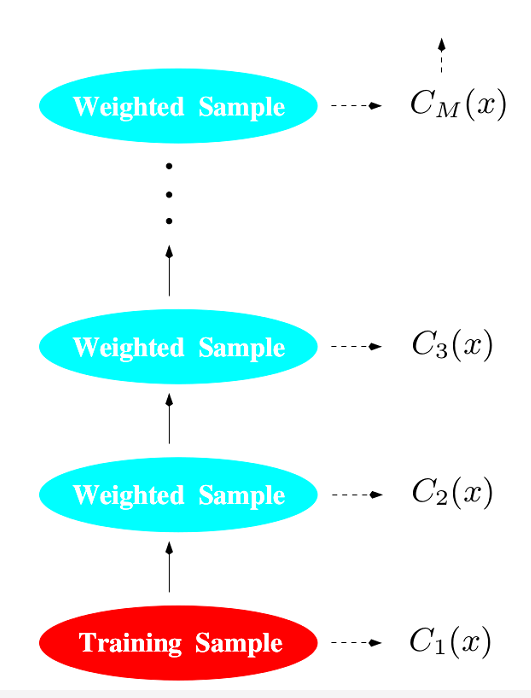
Bagging,Random Forests以及Boosting
前面讲到,决策树(决策树(Decision Tree))可以用来解决分类或回归问题,它们统称为分类回归树(Classification and Regression Tree,CART)。并且,分类回归树有一个显著的缺点,那就是对噪音十分敏感,稍微改变数据,树的形状很有可能发生较大的改变。 为了防止分类回归树陷入过拟合,我们有一系列改善措施来提高树的性能,常见的有Bagging和Rando

机器学习之异常检测--孤立森林(Isolation Forests)
机器学习之异常检测–孤立森林(Isolation Forests, iForests) 异常检测在机器学习领域内的应用场景广泛。比如帮助银行参与检测是否洗钱,识别金融欺诈,帮助保险领域识别是否可能骗保以及监测网络入侵等等。 iForests是异常检测中的一种离群检测方法,可以明确地分离异常样本。与随机森林由大量决策树组成一样,iForests也由大量的树组成。iForest算法是一种基于相似度