本文主要是介绍Bagging,Random Forests以及Boosting,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
为了防止分类回归树陷入过拟合,我们有一系列改善措施来提高树的性能,常见的有Bagging和Random Forests以及Boosting算法。首先来了解一下什么是Bootstrap。
Bootstrap是一种数据抽样方法,最普通的单一树的生成过程是利用所有训练数据进行划分然后产生决策枝干,而Bootstrap的做法是在训练数据中去抽样数据重新获得训练数据集,即从原始训练数据集去可重复地抽样n个样本来作为新的训练数据集,从而训练得到一个决策树。
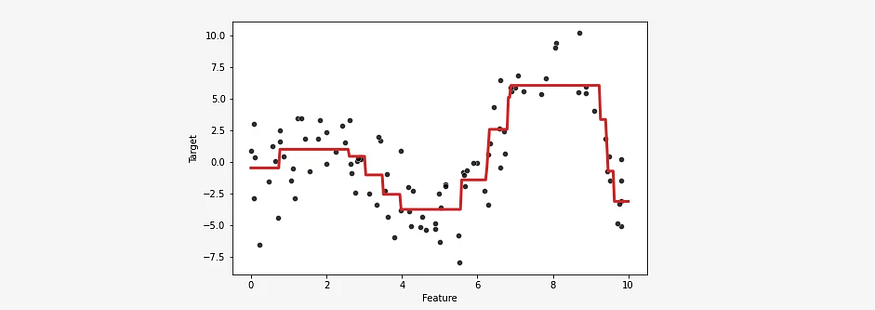
通过Bootstrap抽样方法产生B个新的训练集,从而可以运用不同的数据集训练得到B个不同的决策树,然后对于输入数据x,我们可以由这B个不同的决策树去投票来决定最终的分类结果。这种算法称为Bagging或Bootstrap aggregation,Bagging算法可以显著地提高单一决策树的性能,Bagging是很多树的投票结果,因此可以使得决策边界变得更加平滑了。例如下面一组Bagging的结果与单一决策树形状对比。
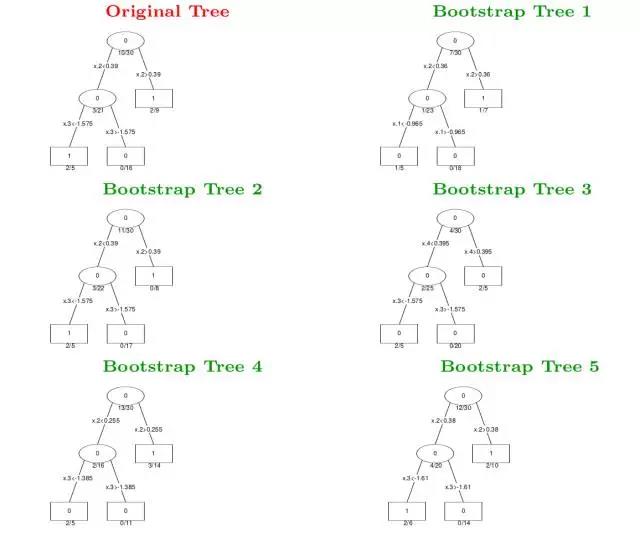
值得注意的是,在Bagging中,由于Bootstrap抽样会使得一些样本无法抽到,那么这些样本将作为测试样本得到测试误差,该误差又称为”out-of-bagging”误差。
随机森林(Random Forests,简称RF)算法是在Bagging算法的基础上再做修正的,RF的做法是在每一步划分时,假设一共有m个特征属性,只从中随机挑选log2(m)或sqrt(m)个特征来计算划分熵,而其他的步骤和Bagging是一样的。
Boosting算法是在Bagging的基础上引入权重因子,即对每个决策树加一个修正权重,最终的分类器是所有分类器的权重和。
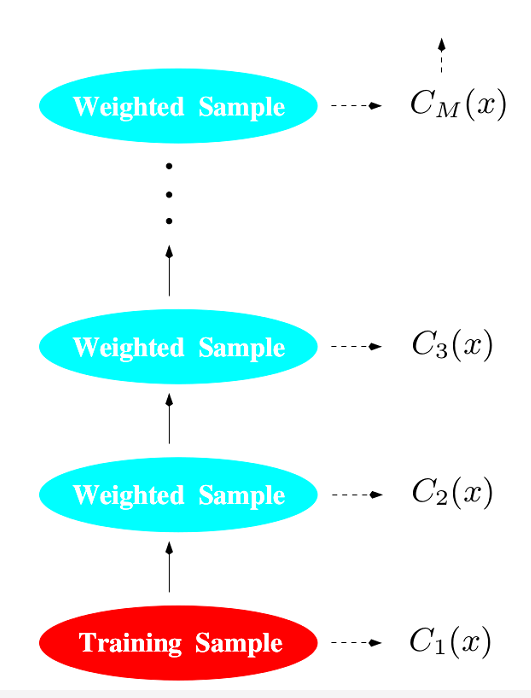
Boosting算法具体流程如下:
1、首先,假设有N个观察样本(即测试样本,或out-of-bagging样本),初始化权重为w_i=1/N;
2、对于M个分类器,重复以下四步:
(1)训练一个树分类器C_m;
(2)计算该树分类器的权重误差
Err_m=SUM(w_i*I(y_i!=C_m(x_i)))/SUM(w_i);
(3)计算alpha_m=log[(1-Err_m)/Err_m];
(4)更新N个权重
w_i=w_i*exp[alpha_m*I(y_i!=C_m(x_i))]
并且归一化所有w,得到新的w_i;
3、计算分类树的最终输出C(x)=sign[SUM(alpha_m*C_m(x))];
这里的SUM是指对下标进行求和,I是误差函数。
这篇关于Bagging,Random Forests以及Boosting的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!