extract专题

MySQL数据库函数之JSON_EXTRACT示例代码
《MySQL数据库函数之JSON_EXTRACT示例代码》:本文主要介绍MySQL数据库函数之JSON_EXTRACT的相关资料,JSON_EXTRACT()函数用于从JSON文档中提取值,支持对... 目录前言基本语法路径表达式示例示例 1: 提取简单值示例 2: 提取嵌套值示例 3: 提取数组中的值注意

【译】PCL官网教程翻译(19):从深度图像中提取NARF特征 - How to extract NARF Features from a range image
英文原文阅读 从深度图像中提取NARF特征 本教程演示如何从深度图像中提取位于NARF关键点位置的NARF描述符。可执行文件使我们能够从磁盘加载点云(如果没有提供,也可以创建点云),从中提取感兴趣的点,然后在这些位置计算描述符。然后,它在图像和3D查看器中可视化这些位置。 代码 首先,在您喜欢的编辑器中创建一个名为narf_feature_extract .cpp的文件,并在其中放置以下代

PDF-Extract-Kit提取PDF数据
链接: https://github.com/opendatalab/PDF-Extract-Kit 记录一下 首先是clone该项目, 然后新建一个虚拟环境 进入环境,进入项目 https://github.com/opendatalab/PDF-Extract-Kit?tab=readme-ov-file#installation-guide 如果报错没有PIL.Image.LINEAR
FFmpeg源码:ff_h2645_extract_rbsp函数分析
一、ff_h2645_extract_rbsp函数的声明 ff_h2645_extract_rbsp函数的声明放在FFmpeg源码(本文演示用的FFmpeg源码版本为5.0.3,该ffmpeg在CentOS 7.5上通过10.2.1版本的gcc编译)的头文件libavcodec/h2645_parse.h中。 /*** Extract the raw (unescaped) bitstrea

关于pg的EXTRACT(8:00-10:00)
今天同事忽然问我,怎么获取数据库中的时间段(比如:8:00-10:00),愁死我了,赶紧问朋友问百度,好在朋友告诉了我EXTRACT这个函数! 工具:postgresSQL EXTRACT(field FROM source) 比如: select * from news where extract(hour from create_date) between 8 and 10;
assign() 功能的实现 数组分配到模板。使用 extract() 函数。 变量分配到模板。使用 compact()
extract($arr); //extract 的作用:从数组中将变量导入到当前的符号表,键做变量,值做值!compact(); // — 建立一个数组,包括变量名和它们的值 class base{public $array;public $key;public $val;public function assign($key,$val){if(array($val)){$this->ar

【知识】pycolmap.Sift.extract的参数和返回格式
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,请不吝给个[点赞、收藏、关注]哦~ import pycolmap# 比较推荐的参数options = {"peak_threshold": 0.0066667,"edge_threshold": 10,"first_octave": -1,"num_octaves": 4,"normalization
sql extract
定义和用法 EXTRACT() 函数用于返回日期/时间的单独部分,比如年、月、日、小时、分钟等等。 语法 EXTRACT(unit FROM date) unit可以是MONTH,WEEK,DAY,HOUR,MINUTE,SECOND等
Hive中正则表达式替换函数 regexp_replace和正则表达式解析函数 regexp_extract的用法总结
Hive中 正则表达式替换函数 regexp_replace和正则表达式解析函数 regexp_extract的用法总结 Hive中有很多字符串相关的函数,其中有两个与正则表达式相关的比较特殊,近期使用的时候做了较多的测试,做个笔记,鼓励一下自己,每天进步一点点。 正则表达式替换函数 regexp_replace 正则替换是常用的字符串替换函数 语法:regexp_replace(stri
问题,sql中extract函数返回的不是int类型
环境:pgsql 在使用extract函数获取月份,然后计算季度,作为2个表连接条件的时候,发现查不到数据,后来发现extract函数返回的并不是int类型数据。 具体去查pgsql官方文档,没看到有说extract函数返回的是什么类型,下面举个例子说一下。 select (11 + 2)/3 -- 结果:4 上面的结果是4,可以认为,整除运算,int/int结果也是int。
scrapy的extract() 、extract_first()方法,get() 、getall() 方法
1.extract()方法: 结果如下: 结论:说明了extract()方法返回的是符合要求的所有的数据,存在一个列表里。 2.extract_first()方法: def parse(self, response): sel = Selector(response) hrefs = sel.xpath(r'//*[@class="c1 ico2"]/li/a/@href

Extract Interface (提炼接口)
Summary:若干客户使用类接口中的同一子集,或者两个类的接口有相同部分。将相同的子集提炼到一个独立接口中。 动机: 类之间彼此相互用的方式有若干种。“使用一个类”通常意味用到该类的所有责任区。另一种情况是,某一组客户只使用类责任区中的一个特定子集。再一种情况则是,这个类需要与所有协助处理某些特定请求的类合作。 对于后两种情况,
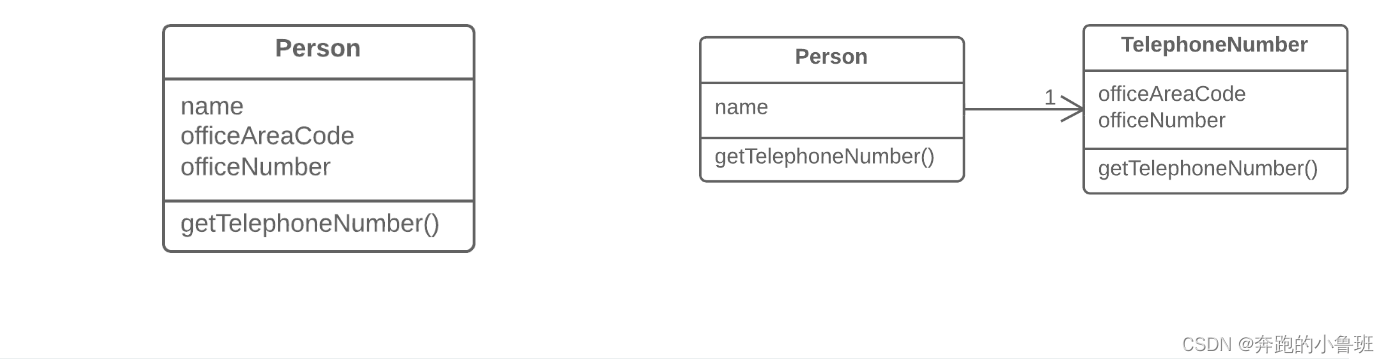
【代码重构】提炼类法(Extract Class)-- 拆解类使得类的职责明确且单一
●适用场景 当一个类做了本该由两个类实现的工作,就会导致类显得笨拙。 ●解决方案 取而代之的,创建一个新的类,并将旧的类中负责某相关功能的字段和方法放在这个类中。 重构前类图 重构后类图 ●为何需要重构 类最开始总是清晰并且容易被理解的。他们只做自己的工作也只关心自己的工作,不会插手其它类的工作。然而随着程序的扩展,新的方法被加入其中,接着又新加
机器人视觉行人跟随中的extract+match feature
机器人行人跟随ros包中加入图像特征提取和特征匹配,提取surf特征,匹配方法是快速最近邻近似搜索flann。 直接上代码:(有问题可以交流~) /******************************************************************************** The MIT License (MIT)** Copyright (c) 2
flinksqlbug : AggregateFunction udf Could not extract a data type from
org.apache.flink.table.api.ValidationException: SQL validation failed. An error occurred in the type inference logic of function ‘default_catalog.default_database.CollectSetSort’. org.apache.flink.tab
GoldenGate 配置extract,replicat进程自启动
在GoldenGate中主进程是manager进程,使用start mgr启动。可以在mgr进程中添加一些参数用来在启动mgr进程的同时启动extract和replicat进程 GGSCI (gg01) 130> VIEW params mgr--mgr主进程端口号PORT 7809--动态端口,当指定端口不可用时,会从以下列表中选择一个可用端口DYNAMICPORTLIST 780
IDEA使用快捷键提炼函数(Extract Method)
IDEA使用快捷键提炼函数(Extract Method) 1、快捷键 ------ctrl+alt+M 2、右击操作--------选中待提炼代码 --> 右击 --> Refactor --> Extract --> Method. 3、举例 提炼前: public void printOwing(double amount) {printBanner();System.out.pr

BUGKU------extract变量覆盖
首先给了我们一串php代码 <?php$flag='xxx';extract($_GET);if(isset($shiyan)){$content=trim(file_get_contents($flag));if($shiyan==$content){echo'flag{xxx}';}else{echo'Oh.no';}}?> 首先需要了解一些函数 extrr

nuxt项目:css相关插件加载顺序问题【extract-css-chunks-webpack-plugin】
一、warning信息 chunk pages/channelManagement/qualification/create/pages/channelManagement/qualification/detail/pages/chan/c61aa583 [extract-css-chunks-webpack-plugin] Conflicting order. Following mo
webpack 4+使用了extract-text-webpack-plugin插件后,编译出错
出现的问题:DeprecationWarning: Tapable.plugin is deprecated. Use new API on `.hooks` instead 解决的方法:npm install extract-text-webpack-plugin@next
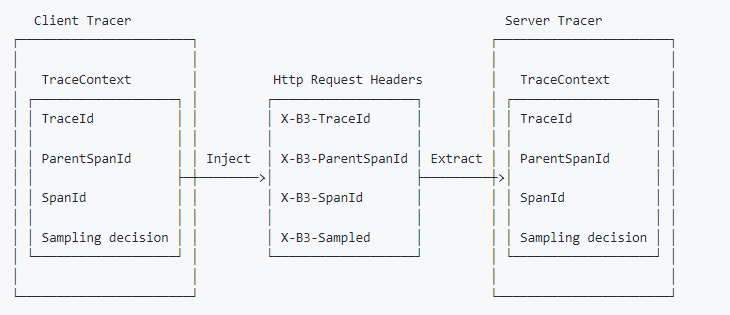
使用 extract + TextMapAdapter 实现了自定义 traceId
前言 某些特定的场景,需要我们通过代码的方式实现自定义 traceId。 实现思路:通过 tracer.extract 能够构造出 SpanContext ,将构造出来的 SpanContext 作为上层节点信息,通过 asChildOf(SpanContext) 能够构造出当前的 span。 TraceId 如何参数定义 对于 tracer.extract 构建 SpanContext,
oracle Extract 函数
oracle Extract 函数 //oracle中extract()函数从oracle 9i中引入,用于从一个 date 或者interval类型中截取到特定的部分 //语法如下: EXTRACT ( { YEAR | MONTH | DAY | HOUR | MINUTE | SECOND }

HttpRunner自动化测试工具之获取响应数据extract提取值到变量
获取响应数据 extract: 提取 注:extract 应与request保持同一层级 1、响应行,响应头;通过 extract 提取响应的数据并存储到变量中,如下图: 注:变量名的前面要有 - # 获取响应数据: 响应行(200,ok)\响应头 - config: name: 测试百度网站 base_url: https://www.baidu.com - tes
![[mini-css-extract-plugin]Conficting order between告警warning(vue构建打包)](https://img-blog.csdnimg.cn/412283acd48f4deabec0419d6ca65b9b.png)
[mini-css-extract-plugin]Conficting order between告警warning(vue构建打包)
问题: npm run build打包时发现项目出现了黄色的 warning 信息 [mini-css-extract-plugin] Conflicting order between 解读 从字面意思为,mini-css-extract-plugin在加载组件时顺序冲突了。 我在查看组件时发现,后面的组件CommonSearch使用时在前,但在加载时顺序import写在后面,所以

FFmpeg 提取运动矢量表extract_mvs方法
FFmpeg提供了获取编码的运动矢量的方法。 打开解码器的时候设置参数:av_dict_set(&opts, “flags2”, “+export_mvs”, 0)。 使用av_frame_get_side_data(frame, AV_FRAME_DATA_MOTION_VECTORS)来获取解码frame中的运动矢量。 av_frame_get_side_data返回的数据类型为AVFra
利用Minidx Extract-Text Com组件从Word,Xls,Pdf……等文件中读取文本内容
利用Minidx Extract-Text Com组件从Word,Xls,Pdf……等文件中读取文本内容 By Minidxer | December 31, 2007 不少人对Google,Baidu等搜索引擎可以“找到”你放在服务器上的Word的Doc,Excel的xls以及Pdf等各种文件而感到惊叹不已,也有不少人发来邮件询问我Minidx文件管理器中从各种格式的文件中读