ensemble专题

one model / ensemble method /meta-algorithm 迁移学习算不算ensemble method
鉴于object detection COCO数据集的论文经常出现 single-model 也就是说,这是一个对网络的分类,呢它是什么意思,有什么特点。相对应的另一类是什么。就是下面介绍的ensemble learning。 不过比如说网络初值是用别人的网络训练好的数值,一定意义来讲是在优化空间找到一个初值,对于自己网络的结果的影响究竟有多大,也就是说,用随机初始网络得到的结果是否有不同,有多

集成学习 Ensemble Learning
目录 一、集成学习概览1、介绍2、学习器3、boosting和bagging比较1、样本选择2、样例权重3、预测函数4、计算5、其他 4、结合策略 二、Adaboost1、介绍2、运行过程3、特点4、代码示例 三、随机森林1、介绍2、随机森林生成3、特点4、优缺点5、代码示例6、参数介绍 四、GBDT1、介绍2、回归树算法流程3、GBDT加法模型:前向分布算法4、加法模型算法过程5、Shri

【量化课堂】决策树及其主要 Ensemble 算法的区别和联系 【记录我的学习】
引言: 本文大致讲讲决策树和它的两种主要优化分支 --Bagging 和 Boosting 下的一些重要算法,对于各个算法的详细知识感兴趣的可以看论坛其他文章:《【量化课堂】随机森林入门》,《【量化课堂】决策树入门及 Python 应用》。本文是小编随笔, 例子不恰当之处请大家不要打小编。-_-#-_-# 本文由 JoinQuant 量化课堂推出 。难度标签为入门,理解深度标签:level-0作

【机器学习实战】第7章 集成方法 ensemble method
第7章 集成方法 ensemble method 集成方法: ensemble method(元算法: meta algorithm) 概述 概念:是对其他算法进行组合的一种形式。 通俗来说: 当做重要决定时,大家可能都会考虑吸取多个专家而不只是一个人的意见。 机器学习处理问题时又何尝不是如此? 这就是集成方法背后的思想。 集成方法: 投票选举(bagging: 自举汇聚法 b


【AdaSeq论文解读系列】ACL 21-自动组合各种BERT模型,在实体抽取、观点抽取、句法分析等六大结构预测任务20+个数据集获SOTA,比ensemble更强!
作者:落叶 链接:https://zhuanlan.zhihu.com/p/593364152 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 本文介绍了一项研究工作,提出了在结构预测问题上自动拼接word embedding(word embedding)以提高模型准确度的方法。该论文已被ACL2021接收为长文。 论文标题: Automated Conca

李宏毅机器学习课程笔记10:Ensemble、Deep Reinforcement Learning
台湾大学李宏毅老师的机器学习课程是一份非常好的ML/DL入门资料,李宏毅老师将课程录像上传到了YouTube,地址:NTUEE ML 2016 。 这篇文章是学习本课程第27-28课所做的笔记和自己的理解。 Lecture 27: Ensemble Ensemble类似于“打群架”“大家一起上”,在Kaggle中是重要的方法。 Ensemble的Framework是: 先找到若干分
![[机器学习入门] 李宏毅机器学习笔记-36(Ensemble part 2;集成方法 part 2)](https://img-blog.csdn.net/20170803224330324?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvc291bG1lZXRsaWFuZw==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)
[机器学习入门] 李宏毅机器学习笔记-36(Ensemble part 2;集成方法 part 2)
[机器学习入门] 李宏毅机器学习笔记-35(Ensemble;集成方法) PDFVIDEO 上接part 1 Ensemble Ensemble Boosting AdaBoost Algorithm for AdaBoost 上面 空白处为+1或-1,由下式决定。 于是:
![[机器学习入门] 李宏毅机器学习笔记-35(Ensemble part 1;集成方法 part 1)](https://img-blog.csdn.net/20170802220515835?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvc291bG1lZXRsaWFuZw==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)
[机器学习入门] 李宏毅机器学习笔记-35(Ensemble part 1;集成方法 part 1)
[机器学习入门] 李宏毅机器学习笔记-35(Ensemble;集成方法) PDFVIDEO Ensemble 俗称打群架,想要得到很好的performance,基本都要用这一手。 You already developed some algorithms and codes.Lazy to modify them.Ensemble: improving your machin

Patch-Based 3D Unet for Head and Neck Tumor Segmentation with an Ensemble of Conventional and Dilate
Patch-Based 3D Unet for Head and Neck Tumor Segmentation with an Ensemble of Conventional and Dilated Convolutions 总结: 普通的3D Unet通过超参数(patch size、loss、convolution)的调整,创建了五个模型(也就是使用不同超参数的五个3D Unet),将总体
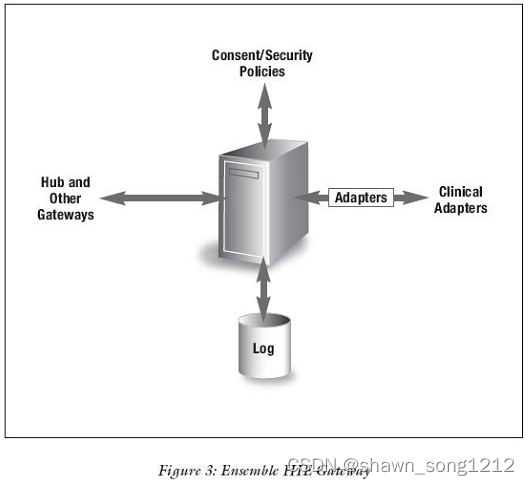
医院信息系统集成平台—Ensemble集成平台中间件
Ensemble HIE(健康信息交换)是InterSystems公司一个新的产品,它采用了一种全新的解决方案,是一个强大的应用软件整合平台,它包括了为医疗信息交换预先开发好的组件,使用Ensemble可以快速地整合和开发复合应用程序。Ensemble在增强现有软件功能、协调新的商业过程和集中企业数据等方面非常出色。 为了满足每一个交换系统的实际需要,它还提供了一个为客户化和扩展这些组件功能的完

《Ensemble deep learning: A review》阅读笔记
论文标题 《Ensemble deep learning: A review》 集成深度学习: 综述 作者 M.A. Ganaie 和 Minghui Hu 来自印度理工学院印多尔分校数学系和南洋理工大学电气与电子工程学院 本文写的大而全。 初读 摘要 集成学习思想: 结合几个单独的模型以获得更好的泛化性能。 目前,深度学习架构与浅层或传统模型相比表现更好。深度集成学习模型结
【医学+深度论文:F33】2017Glaucoma detection using entropy sampling and ensemble learning for automatic optic
33 2017 Computerized Medical Imaging and Graphics Glaucoma detection using entropy sampling and ensemble learning for automatic optic cup and disc segmentation Method : 分割 Dataset: DRISHTI-GS Arch

视频教程-机器学习之集成学习(Ensemble Learning)视频教学-机器学习
机器学习之集成学习(Ensemble Learning)视频教学 乐川科技有限公司CEO,人工智能培训讲师,专业从事机器学习与深度学习培训。参与多个人工智能领域项目,专注于机器学习与计算机视觉领域,长期参与无人驾驶汽车项目,专注研究无人驾驶领域的目标识别与跟踪,善于人脸识别、物体识别、轨迹跟踪、点云识别分析等方向的新算法。 王而川 ¥117.00 立即订阅

ZooKeeper学习之配置【7】ensemble配置
quorum这个概念深深嵌入了ZooKeeper的设计中,尤其是当处理请求和在replicate模式中进行选举leader时尤为相关。如果ZooKeeper的各个server的quorum起来(up)时,ensemble才能继续(make progress)。 [b]Majority Rules[/b] 当一个ensemble有足够的Zookeeper server时,便能够开始处理请求,
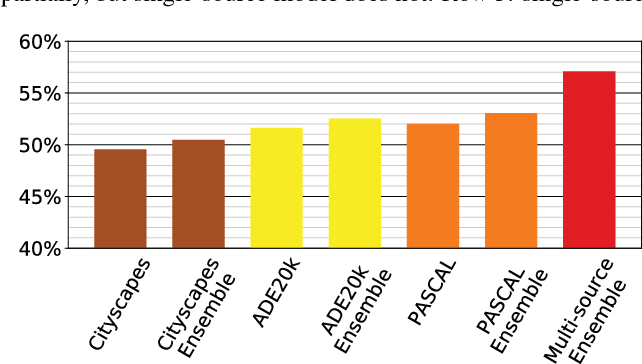
论文阅读:Ensemble Knowledge Transfer for Semantic Segmentation
论文地址:https://ieeexplore.ieee.org/document/8354272 项目及数据地址:https://github.com/ishann/aeroscapes 发表时间:2018年5月7日 语义分割网络通常以严格监督的方式学习,即它们在相似的数据分布上进行训练和测试。在域转移的存在下,性能急剧下降。在本文中,我们探索了在场景结构、视点和对象统计数据上存在显著不同的训
论文阅读:Ensemble Knowledge Transfer for Semantic Segmentation
论文地址:https://ieeexplore.ieee.org/document/8354272 项目及数据地址:https://github.com/ishann/aeroscapes 发表时间:2018年5月7日 语义分割网络通常以严格监督的方式学习,即它们在相似的数据分布上进行训练和测试。在域转移的存在下,性能急剧下降。在本文中,我们探索了在场景结构、视点和对象统计数据上存在显著不同的训
MNIST1_sklearn.ensemble集成模型训练
针对MNIST数据集进行sklearn中的集成模型的训练和测试 部分脚本如下: 完整脚本见笔者github import pandas as pd import numpy as npfrom sklearn.datasets import fetch_mldataimport warningswarnings.filterwarnings(action='ignore')def get

Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks
文章目录 概主要内容Auto-PGDMomentumStep Size损失函数AutoAttack Croce F. & Hein M. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. In International Confe

深入浅出:Knowledge Distillation by On-the-Fly Native Ensemble
简述: 这是一篇关于知识蒸馏的论文,知识蒸馏可有效地训练小型通用网络模型,以满足低内存和快速运行的需求。现有的离线蒸馏方法依赖于训练有素的强大教师,这可以促进有利的知识发现和传递,但需要复杂的两阶段训练程序。作者提出了一种用于一阶段在线蒸馏的动态本地集成(ONE)学习策略。具体来说,ONE只训练一个单一的多分支网络,而同时动态地建立一个强大的教师来增强目标网络的学习。 模型overvie

Deep Reinforcement Learning for Automated Stock Trading An Ensemble Strategy
Deep Reinforcement Learning for Automated Stock Trading An Ensemble Strategy 论文 股票交易策略在投资中起着关键作用。然而,在复杂多变的股票市场上设计一个有利可图的策略是很有挑战性的。在本文中,我们提出了一种采用深度强化方案的集合策略,通过最大化投资收益来学习股票交易策略。我们训练了一个深度强化学习代理,并使用三种ac
Ensemble Learning(Trees, Forests, Bagging, Boosting)
1.概述 有监督学习任务中,对于一个相对复杂的任务而言,我们的目标是学习出一个稳定且在各个方面表现都较好的模型,但实际情况往往不会如此理想,有时只能得到多个有偏好的模型(弱监督模型或弱可学习weakly learnable模型)。集成学习就是组合这里的多个弱可学习模型得到一个更好更全面的强可学习 strongly learnable模型,集成学习潜在的思想是即便某一个弱学习器得到了错误的预测,其

【论文笔记】Ensemble Augmented-Shot Y-shaped Learning
【论文笔记】EASY – Ensemble Augmented-Shot Y-shaped Learning: State-Of-The-Art Few-Shot Classification with Simple Ingredients IntroductionRELATED WORKMETHODOLOGYSTEPS 参考资料 文章链接 :EASY – Ensemble Au
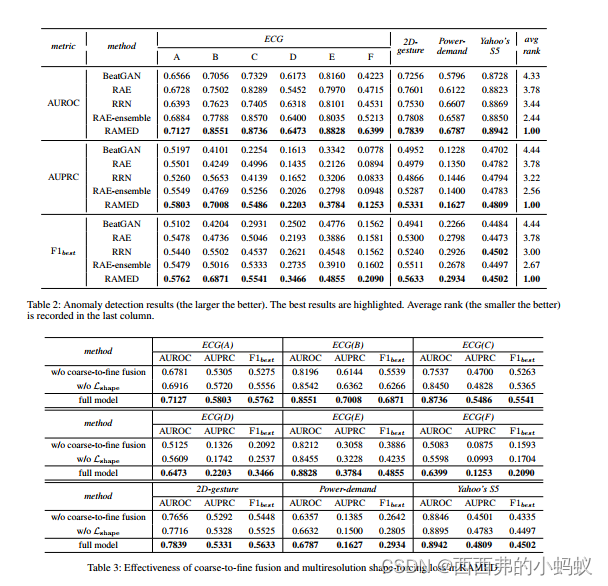
Time Series Anomaly Detection with Multiresolution Ensemble Decoding(AAAI2021)
循环自编码器是一种常用的时间序列异常检测模型,它利用异常点或异常段的高重建误差来识别异常点或异常段。然而,现有的循环式自动编码器由于序贯解码,容易出现过拟合和错误累积的问题。在本文中,我们提出了一种简单而有效的循环网络集成,称为多分辨率集成译码循环自编码器(RAMED)。通过使用不同译码长度的译码器和一种新的粗到细融合机制,较低分辨率的信息可以帮助译码器实现高分辨率输出的长距离译码。进一步引入多分

【迁移攻击笔记】2019.11分批次集成攻击A New Ensemble Adversarial Attack Powered by Long-term Gradient Memories
0.总览 上交和阿里巴巴团队的一篇我觉得是把集成迁移攻击研究透了的文章。每个trcik都有很复杂的数学支撑, 1.Introduction ①目前主流的迁移方法:ensemble-based 和 GAN, 对算力和内存要求高。 ②因此提出SMBEA(Serial Mini-Batch Ensemble Attack),基于俩个先验:模型迁移相当于网络泛化;边界相似度比扰动大小的限制更重要。