本文主要是介绍深入浅出:Knowledge Distillation by On-the-Fly Native Ensemble,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简述:
这是一篇关于知识蒸馏的论文,知识蒸馏可有效地训练小型通用网络模型,以满足低内存和快速运行的需求。现有的离线蒸馏方法依赖于训练有素的强大教师,这可以促进有利的知识发现和传递,但需要复杂的两阶段训练程序。作者提出了一种用于一阶段在线蒸馏的动态本地集成(ONE)学习策略。具体来说,ONE只训练一个单一的多分支网络,而同时动态地建立一个强大的教师来增强目标网络的学习。
模型overview

ONE体系结构如上图所示。ONE包含两个组件:
(1)m个具有相同配置的分支。其中每个分支共享低层的网络,并且充当一个独立的分类模型。
(2)门控组件,它学习将所有(m + 1)个分支,并将分支集成在一起以建立更强大的教师模型。
模型分析:
首先对于一个类c的样本x,网络θ输出一个类后验概率p(c|x,θ):

其中z是网络θ输出的logits。每个多类别分类模型采用的是交叉熵(CE)度量作为目标损失函数:
 .
.
其中对于δc,y,如果c是真实标签,则返回1,否则返回0。
此外,采用所有分支的集成可以建立更强大的教师模型。文中通过门控组件进行集成:

接下来就是知识蒸馏部分,在上述的公式得到每个训练样本的教师logits后,再将知识以闭环形式蒸馏回所有分支。采用以下公式:

然后,使用KL散度来实现从教师网络蒸馏回学生网络:
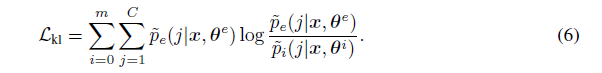
最后,整个ONE网络获得在线蒸馏训练的总体损失函数为:

这篇关于深入浅出:Knowledge Distillation by On-the-Fly Native Ensemble的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!