dpu专题

Vitis AI 综合实践(DPU example: dpu_resnet50.ipynb)
目录 1. 简介 2. 代码解析 2.1 导入库 2.2 图像预处理 2.3 读取标签 2.4 读取图像 2.5 获取IO形状 2.6 申请内存 2.7 运行推理 2.8 后处理 3. 相关类的介绍 3.1 DpuOverlay 类 3.2 Overlay 类 3.3 Bitsteam 类 3.4 Device 类 3.5 DeviceMeta 元类 3.6 ty

算力巅峰对决,一文读懂CPU、GPU、GPGPU、FPGA、DPU、TPU
通俗理解CPU、GPU、GPGPU、FPGA、DPU、TPU 每个处理器都有它的独特之处和擅长领域,它们共同构成了现代计算的多彩世界。 1. CPU - 中央处理单元 CPU,城市的市中心,精通从基础计算到复杂逻辑决策的各项任务。它高效执行操作指令,轻松应对日常任务如网页浏览和文档编辑。尽管多才多艺,面对超复杂或特定任务

网络业务创新驱动下的DPU P4技术,中科驭数在网络开源技术生态大会上分享最新进展
2024年5月25日,由中国通信学会指导,中国通信学会开源技术专业委员会、江苏省未来网络创新研究院主办的第四届网络开源技术生态大会在北京举办,中科驭数产品总监李冬以《合作如兰,扬扬其香 中科驭数助力P4产业发展与生态建设》为主题,分享了中科驭数DPU P4技术的最新研发进展和生态成果,在软件定义框架下,支持P4的DPU对网络数据平面实现了高性能和灵活可编程的融合,从而响应云计算、数据中心、网络安全
VMware vSphere Distributed Services Engine 和利用 DPU 实现网络加速
VMware相关学习专栏:虚拟化技术 vSphere 8.0 通过加速数据处理单元 (DPU) 上的网络功能实现了突破性的工作负载性能。 vSphere 8.0 通过加速 DPU 上的网络功能实现了突破性工作负载性能,从而满足现代分布式工作负载的吞吐量和延迟需求。借助 vSphere Distributed Services Engine,基础架构服务分布在 ESXi 主机上可用的不同

深度践行“IaaS on DPU”理念,中科驭数正式发布“驭云”高性能云异构算力解决方案
5月10日至14日,由国家发展改革委联合国务院国资委、市场监管总局、国家知识产权局共同主办的第八届中国品牌日活动在上海世博展览馆举行。中科驭数高级副总裁张宇在中国品牌日新品首发首秀环节正式发布驭云®高性能云异构算力解决方案,为企业提供更快部署、更强性能和更高吞吐的云算力解决方案。 在发布环节,张宇表示:“驭云®高性能云异构算力解决方案是中科驭数深度洞察算力技术发展趋势,精准把握云平台业务需求,致

【DPU系列之】如何通过带外口登录到DPU上的ARM服务器?(Bluefield2举例)
文章目录 1. 背景说明2. 详细操作步骤2.1 目标拓扑结构2.2 连接DPU带外口网线,并获取IP地址2.3 ssh登录到DPU 3. 进一步看看系统的一些信息3.1 CPU信息:8核A723.2 内存信息 16GB3.3 查看ibdev设备 3.4 使用小工具pcie2netdev查看信息3.5 查看PCIe设备信息 4. 综述 1. 背景说明 本文以BF2为例举例说明如何

【DPU系列之】Bluefield 2 DPU卡的功能图,ConnectX网卡、ARM OS、Host OS的关系?(通过PCIe Switch连接)
核心要点: CX系列网卡与ARM中间有一个PCIe Swtich的硬件单元链接。 简要记录。 可以看到图中两个灰色框,上端是Host主机,下端是BlueField DPU卡。图中是BF2的图,是BF2用的是DDR4。DPU上的Connect系列网卡以及ARM系统之间有一个PCIe的Switch这个PCIe switch是独立于CX网卡和ARM核的。通过PCIe Switch从而可以将BF2

关键技术自主可控,中国移动发布大云磐石DPU芯片,速率达400Gbps
4月28日,中国移动在2024算力网络大会上正式发布大云磐石DPU,该芯片带宽达到400Gbps,为国内领先水平,将应用于移动云新一代大云磐石DPU产品,实现关键技术自主可控。 据介绍,DPU是一种专注于数据处理的处理器,可实现更高效的数据处理。磐石DPU芯片拥有400Gbps的数据传输能力,将国产DPU芯片最高传输速率提升一倍,达到全球顶尖水平。该芯片拥有每秒处理百万个数据包的存储能力,远
Vitis AI 迁移学习并部署在DPU中
目录 1. 本文目的 2. ResNet18介绍 3. 迁移学习 4. 量化配置文件 5. 模型编译: 6. 总结 1. 本文目的 使用迁移学习的方法,将预训练的resnet18模型从原来的1000类分类任务,改造为适应自定义的30类分类任务。 2. ResNet18介绍 ResNet18是一种基于深度残差网络(ResNet)的卷积神经网络模型,由何凯明等人于2015年

CPU、GPU、NPU、VPU和DPU 简介
在SoC(System on Chip)设计中,NPU、GPU、CPU、VPU和DPU是不同类型的处理器单元,它们各自针对不同的计算任务和应用场景进行了优化。下面详细介绍每一种处理器单元的特点、区别以及用途。 CPU (Central Processing Unit) 特点:CPU是通用处理器,负责执行广泛的计算任务和系统管理。它通常包括运算器、控制单元、寄存器和缓存等组件。区别:与其他专用处

GTC 2024 火线评论:DPU 重构文件存储访问
编者按:英伟达2024 GTC 大会上周在美国加州召开,星辰天合 CTO 王豪迈在大会现场参与了 GPU 与存储相关的最新技术讨论,继上一篇《GTC 2024 火线评论:GPU 的高效存储利用》之后,这是他发回的第二篇评论文章。 上一篇文章已经提到,随着 AI 集群规模的提升,数据集的大幅增长,势必要面对集群资源的高效利用和安全问题,其中关键之一就是计算资源对于共享资源(如共享文件存储)的安
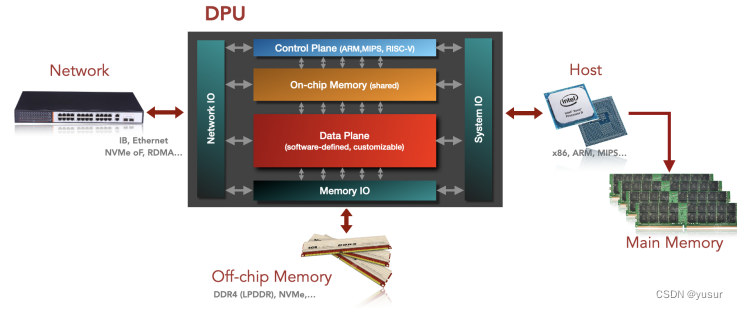
DPU特征结构系列(二)一种DPU参考设计
为了满足“数据为中心”的设计理念,本节给出一个通用的DPU参考设计。目前DPU架构的演化比较快,DPU既可以呈现为一个被动设备作为CPU的协处理器,也可以作为一个主动设备,承接Hypervisor的一些功能。尤其是容器技术、虚拟化技术的广泛采用,DPU的角色已经不仅仅是一个协处理器,而是呈现出更多的HOST的特征,比如运行Hypervisor,做跨节点的资源整合,为裸金属和虚拟机提供虚拟网络,数据
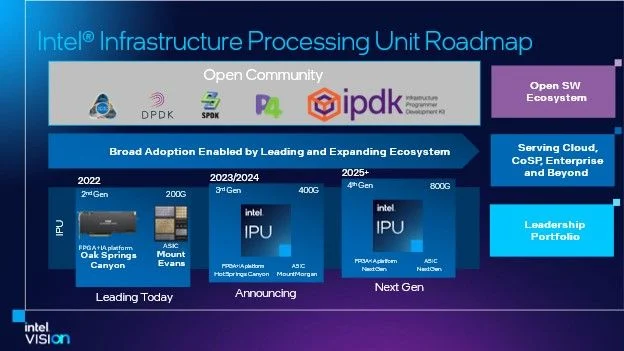
DPU技术的进步:赋予未来创新力量
随着云计算和虚拟化技术的发展,网卡在功能和硬件结构方面也经历了四个阶段,即网卡、智能网卡、基于FPGA的DPU和DPU SoC网卡。本文将重点介绍这些不同类型的网络适配器和处理器,在硬件、可编程能力、开发和应用方面的特点。 网卡的演进和应用 传统的基本网卡,也被称为NIC或网络适配器,在计算机网络中的作用至关重要。它的主要功能是将数据转换为网络设备之间高效传输所需的格式。随着时间的推移,网卡的
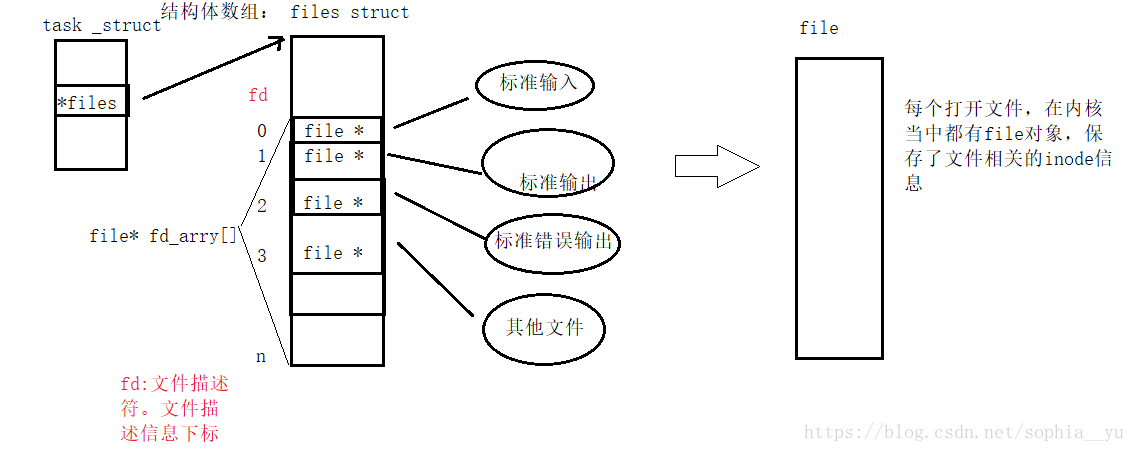
文件描述符fd和重定向(dpu、dpu2)
一:文件描述符 文件描述符是什么? 文件描述符实际是一个数字,进程如何通过一个数组来操作文件? Linux进程默认情况下会有3个缺省打开的文件描述符,分别是标准输入0,标准输出1,错误标准输出2; 0,1,2对应的物理设备一般是:键盘,显示器,显示器。 文件描述符是进程pcb中files _struct这个结构体中文件描述信息的结构体数组的下标,操作系统就可以通过这个数字下标找到对应的文件信息,

双双入选 中科驭数第二代DPU芯片K2和低时延DPU卡荣获2023年北京市新技术新产品新服务认定
北京市新技术新产品(服务)认定是北京市从重点发展的先导技术、战略性新兴产业和现代服务业领域中,选拔出技术先进、产权明晰、质量可靠、市场前景广阔,且符合构建“高精尖”经济结构要求的产品及服务,具有较高权威性和影响力。 近日,北京市科学技术委员会、中关村科技园区管理委员会等五部门公示了北京市第十九批新技术新产品(服务)名单,中科驭数自主研发的“数据专用处理器DPU芯片K2”、“KPU SWIFT®-

中科驭数鄢贵海新年演讲:数字经济下的算力基础先行,DPU自主创新力量大有可为
近日,中科驭数创始人、CEO鄢贵海受邀在北京电视台《金融街午餐会》新年特别活动中发表新年演讲。 鄢贵海在新年演讲中提到,在21世纪头30年,我们不可思议地经历了三次重要的科技变革,分别是互联网的普及、移动互联网的崛起、以及人工智能大模型的剧烈演进。这三次浪潮不仅改变了我们的生产生活方式,还为数字化和智能化奠定了基础。 他指出,在当前通用人工智能的发展中,算力是推动大模型训练和推理的核心,也是数

重磅发布!《天翼云白皮书》+天翼云紫金DPU来了!
12月29日,由中国电信主办的“2022天翼数字科技生态大会”在云端召开。会上,中国电信总经理邵广禄发布了天翼云两项重要成果——《天翼云白皮书》和天翼云紫金DPU。 《天翼云白皮书》阐述了天翼云发展愿景、发展目标、演进路径、关键举措,并在天翼云发展愿景和使命方面这样规划: 面向党政军、央国企、重点行业核心诉求,突破云网融合关键核心技术,深化云网边端协同能力,打造一朵具备科技创新、自主可控、
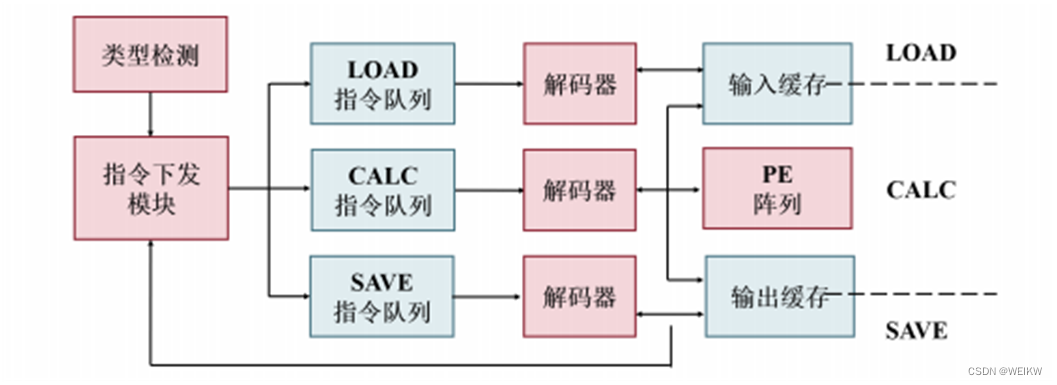
神经网络硬件加速器-DPU分析
一 DPU概述 DPU是专为卷积神经网络优化的可编程引擎,其使用专用指令集,支持诸多卷积神经网络的有效实现。 1、关键模块 卷积引擎:常规CONV等ALU:DepthwiseConvScheduler:指令调度分发Buffer Group:片上数据缓存Data Mover:高速数据通道 2、特性 3、工作流程 阶段一:上电后,DPU将指令从外部DRAM加载到