本文主要是介绍Vitis AI 迁移学习并部署在DPU中,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1. 本文目的
2. ResNet18介绍
3. 迁移学习
4. 量化配置文件
5. 模型编译:
6. 总结
1. 本文目的
使用迁移学习的方法,将预训练的resnet18模型从原来的1000类分类任务,改造为适应自定义的30类分类任务。
2. ResNet18介绍
ResNet18是一种基于深度残差网络(ResNet)的卷积神经网络模型,由何凯明等人于2015年提出。ResNet的核心思想是通过引入残差块(Residual Block),解决了深度网络中的梯度消失和退化问题,使得网络可以更深更有效地学习特征。
ResNet18是ResNet系列中最简单的一个模型,共有18层,其中包括:
- 一个7×7的卷积层,输出通道数为64,步幅为2,后接批量归一化(Batch Normalization)和ReLU激活函数。
- 一个3×3的最大池化层(Max Pooling),步幅为2。
- 四个由残差块组成的模块,每个模块包含两个或三个残差块,每个残差块由两个3×3的卷积层、批量归一化和ReLU激活函数组成。每个模块的第一个残差块可能会改变输入输出的通道数和步幅,以适应下一个模块。这四个模块的输出通道数分别为64、128、256、512,步幅分别为1、2、2、2。
- 一个全局平均池化层(Global Average Pooling),将最后一个模块的输出转换为一个一维向量。
- 一个全连接层(Fully Connected),将一维向量映射到最终的类别数1000类上。
3. 迁移学习
根据不同的任务和数据集,迁移学习有以下几种常见的方法:
- 微调网络:这种方法是在预训练模型的基础上,修改最后一层或几层,并且对整个网络进行微调训练。这种方法适用于新数据集和原数据集相似度较高,且新数据集规模较大的情况。
- 特征提取:这种方法是将预训练模型看作一个特征提取器,冻结除了最后一层以外的所有层,只修改和训练最后一层。这种方法适用于新数据集和原数据集相似度较高,但新数据集规模较小的情况。
- 模型蒸馏:这种方法是将预训练模型看作一个教师模型,用它来指导一个更小的学生模型,使学生模型能够学习到教师模型的知识。这种方法适用于新数据集和原数据集相似度较低,或者需要减少模型大小和计算量的情况。
首先导入所需的模块:
#!pip install -i <https://pypi.tuna.tsinghua.edu.cn/simple> torchsummary
# torchsummary是一个用于查看网络结构,非必须from torchsummary import summary
import torch, torchvision, random
from pytorch_nndct.apis import Inspector, torch_quantizer
import torchvision.transforms as transforms
from torchvision import models
from tqdm import tqdm
然后导入预训练模型,并查看网络结构:
model = models.resnet18(pretrained=True) # 载入预训练模型
summary(model, (3, 224, 224))---以下为执行结果
----------------------------------------------------------------Layer (type) Output Shape Param #
================================================================Conv2d-1 [-1, 64, 112, 112] 9,408BatchNorm2d-2 [-1, 64, 112, 112] 128ReLU-3 [-1, 64, 112, 112] 0MaxPool2d-4 [-1, 64, 56, 56] 0Conv2d-5 [-1, 64, 56, 56] 36,864BatchNorm2d-6 [-1, 64, 56, 56] 128ReLU-7 [-1, 64, 56, 56] 0Conv2d-8 [-1, 64, 56, 56] 36,864BatchNorm2d-9 [-1, 64, 56, 56] 128ReLU-10 [-1, 64, 56, 56] 0BasicBlock-11 [-1, 64, 56, 56] 0Conv2d-12 [-1, 64, 56, 56] 36,864BatchNorm2d-13 [-1, 64, 56, 56] 128ReLU-14 [-1, 64, 56, 56] 0Conv2d-15 [-1, 64, 56, 56] 36,864BatchNorm2d-16 [-1, 64, 56, 56] 128ReLU-17 [-1, 64, 56, 56] 0BasicBlock-18 [-1, 64, 56, 56] 0Conv2d-19 [-1, 128, 28, 28] 73,728BatchNorm2d-20 [-1, 128, 28, 28] 256ReLU-21 [-1, 128, 28, 28] 0Conv2d-22 [-1, 128, 28, 28] 147,456BatchNorm2d-23 [-1, 128, 28, 28] 256Conv2d-24 [-1, 128, 28, 28] 8,192BatchNorm2d-25 [-1, 128, 28, 28] 256ReLU-26 [-1, 128, 28, 28] 0BasicBlock-27 [-1, 128, 28, 28] 0Conv2d-28 [-1, 128, 28, 28] 147,456BatchNorm2d-29 [-1, 128, 28, 28] 256ReLU-30 [-1, 128, 28, 28] 0Conv2d-31 [-1, 128, 28, 28] 147,456BatchNorm2d-32 [-1, 128, 28, 28] 256ReLU-33 [-1, 128, 28, 28] 0BasicBlock-34 [-1, 128, 28, 28] 0Conv2d-35 [-1, 256, 14, 14] 294,912BatchNorm2d-36 [-1, 256, 14, 14] 512ReLU-37 [-1, 256, 14, 14] 0Conv2d-38 [-1, 256, 14, 14] 589,824BatchNorm2d-39 [-1, 256, 14, 14] 512Conv2d-40 [-1, 256, 14, 14] 32,768BatchNorm2d-41 [-1, 256, 14, 14] 512ReLU-42 [-1, 256, 14, 14] 0BasicBlock-43 [-1, 256, 14, 14] 0Conv2d-44 [-1, 256, 14, 14] 589,824BatchNorm2d-45 [-1, 256, 14, 14] 512ReLU-46 [-1, 256, 14, 14] 0Conv2d-47 [-1, 256, 14, 14] 589,824BatchNorm2d-48 [-1, 256, 14, 14] 512ReLU-49 [-1, 256, 14, 14] 0BasicBlock-50 [-1, 256, 14, 14] 0Conv2d-51 [-1, 512, 7, 7] 1,179,648BatchNorm2d-52 [-1, 512, 7, 7] 1,024ReLU-53 [-1, 512, 7, 7] 0Conv2d-54 [-1, 512, 7, 7] 2,359,296BatchNorm2d-55 [-1, 512, 7, 7] 1,024Conv2d-56 [-1, 512, 7, 7] 131,072BatchNorm2d-57 [-1, 512, 7, 7] 1,024ReLU-58 [-1, 512, 7, 7] 0BasicBlock-59 [-1, 512, 7, 7] 0Conv2d-60 [-1, 512, 7, 7] 2,359,296BatchNorm2d-61 [-1, 512, 7, 7] 1,024ReLU-62 [-1, 512, 7, 7] 0Conv2d-63 [-1, 512, 7, 7] 2,359,296BatchNorm2d-64 [-1, 512, 7, 7] 1,024ReLU-65 [-1, 512, 7, 7] 0BasicBlock-66 [-1, 512, 7, 7] 0
AdaptiveAvgPool2d-67 [-1, 512, 1, 1] 0Linear-68 [-1, 1000] 513,000
================================================================
Total params: 11,689,512
Trainable params: 11,689,512
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 62.79
Params size (MB): 44.59
Estimated Total Size (MB): 107.96
----------------------------------------------------------------
可以原始看到最后一层有1000个特征输出,对应1000分类。我们要做的,就是使用特征提取方法,修改最后一层(FC),实现一个30分类的特征输出。
修改全链接层,然后查看修改结果:
print('Original output layer:')
print(model.fc)#输入特征数(in_features)保持不变,输出特征数(out_features)设置为10
model.fc = torch.nn.Linear(model.fc.in_features, 30)
print('New output layer:')
print(model.fc)---以下为执行结果
Original output layer:
Linear(in_features=512, out_features=1000, bias=True)
New output layer:
Linear(in_features=512, out_features=30, bias=True)
配置优化器,只微调输出层(FC),然后执行训练:
# 只微调训练最后一层全连接层的参数,其它层冻结
optimizer = optim.Adam(model.fc.parameters())# 遍历每个 EPOCH
for epoch in tqdm(range(EPOCHS)):model.train()for images, labels in train_loader: # 获取训练集的一个 batch,包含数据和标注images = images.to(device)labels = labels.to(device)outputs = model(images) # 前向预测,获得当前 batch 的预测结果loss = criterion(outputs, labels) # 比较预测结果和标注,计算当前 batch 的交叉熵损失函数optimizer.zero_grad()loss.backward() # 损失函数对神经网络权重反向传播求梯度optimizer.step() # 优化更新神经网络权重---以下为执行结果
100%|██████████| 20/20 [03:04<00:00, 9.24s/it]
在测试集的准确度为:85.900 %
注:本文不详解如何构建数据集加载器,以及测试部分相关代码,只保留关键代码以演示使用迁移学习过程,需要读者自行补齐机器学习相关知识。
导出迁移学习后的结果模型:
torch.save(model, 'resnet18_out30.pth')
将在当前工作目录下,生成resnet18_out30.pth文件。
4. 量化配置文件
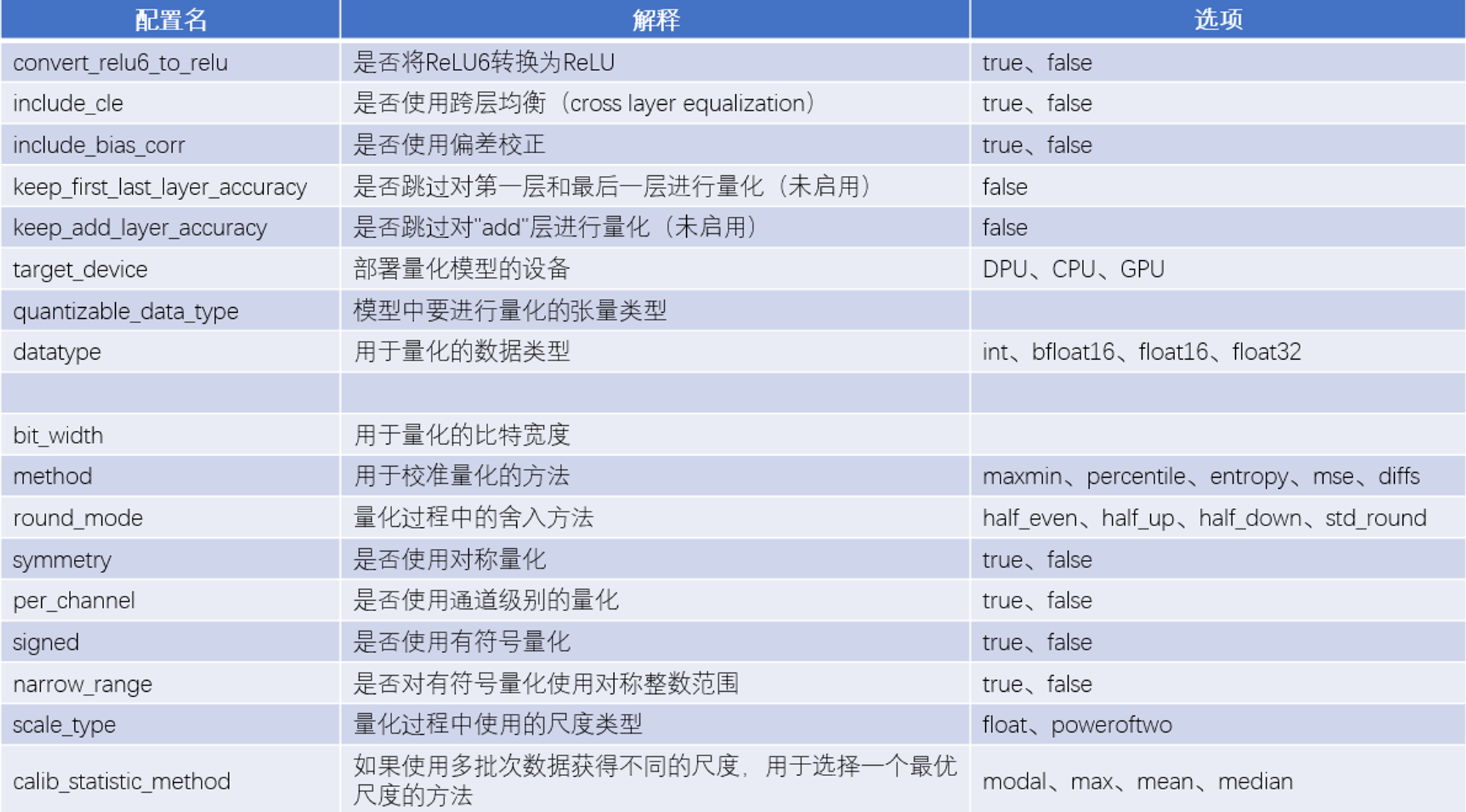
这些参数是量化配置文件的重点,下面作详细解释:
全局量化设置的部分:
- convert_relu6_to_relu: 这个配置是用来决定是否将relu6转换为relu。relu6是一种激活函数,它的输出范围是[0, 6],而relu的输出范围是[0, +∞)。在量化过程中,将relu6转换为relu可以减少量化误差,提高模型精度。
- include_cle: 这个配置是用来决定是否使用跨层均衡(cross layer equalization)。跨层均衡是一种优化方法,它可以在保持模型输出不变的情况下,调整相邻层之间的权重和偏置,使得量化后的模型更加稳定和鲁棒。
- include_bias_corr: 这个配置是用来决定是否使用偏置校正(bias correction),选项有true和false。偏置校正是一种优化方法,它可以在量化后的模型中,根据量化前后的权重和激活值的变化,对偏置进行微调,以减少量化误差,提高模型精度。
- keep_first_last_layer_accuracy: 这个配置是用来决定是否保持第一层和最后一层的精度。第一层和最后一层通常对模型性能影响较大,如果在量化过程中损失了精度,可能会导致模型输出质量下降。这个配置可以选择是否对第一层和最后一层使用更高的位宽或者更精细的量化方法,以保持它们的精度。
- keep_add_layer_accuracy: 这个配置是用来决定是否保持"add"层的精度。"add"层是指在残差网络(ResNet)等模型中,将两个分支相加的层。这些层通常对模型性能影响较大,如果在量化过程中损失了精度,可能会导致模型输出质量下降。这个配置可以选择是否对"add"层使用更高的位宽或者更精细的量化方法,以保持它们的精度。
- target_device: 这个配置是用来指定部署量化后模型的目标设备,选项有DPU, CPU, GPU。
- quantizable_data_type: 这个配置是用来指定需要被量化的张量类型。比如"input", "weights", "bias", "activation”。
量化参数的部分:
- bit_width: 这个参数是用来指定量化时使用的位宽,KV260中的DPU使用8bit量化。
- method: 这个参数是用来指定在校准过程中使用的方法,选项有maxmin, percentile, entropy, mse, diffs。校准过程是指通过一些样本数据,来确定量化时使用的最大值和最小值,从而确定量化的比例因子。不同的方法有不同的优缺点,例如maxmin是最简单的方法,但也最容易受到异常值的影响;percentile是一种基于分位数的方法,可以避免异常值的影响,但也可能损失一些信息;entropy是一种基于信息熵的方法,可以最大化保留信息,但也比较复杂和耗时;mse是一种基于均方误差的方法,可以最小化量化误差,但也比较复杂和耗时;diffs是一种基于差分的方法,可以最大化保留梯度信息,但也比较复杂和耗时。
- round_mode: 这个参数是用来指定在量化过程中使用的舍入方法,选项有half_even, half_up, half_down, std_round。舍入方法是指在将浮点数转换为整数时,如何处理小数部分。不同的舍入方法有不同的效果,例如half_even是一种四舍六入五取偶的方法,可以减少舍入误差的累积;half_up是一种向远离零的四舍五入的方法,可以保持数值的大小;half_down是一种五舍六入的方法,可以减少数值的大小;std_round是一种标准的四舍五入的方法,可以保持数值的大小。
- symmetry: 这个参数是用来决定是否使用对称量化。对称量化是指在量化过程中,使用相同的比例因子和零点来表示正负数值。对称量化可以简化计算过程,提高运算效率。DPU应当使用对称量化。
- per_channel: 这个参数是用来决定是否使用逐通道量化。对张量量化是指张量中的所有值采用相同的方式和相同的参数进行量化,而对每个通道量化是指对张量的每个维度(通常是通道维度)采用不同的参数进行量化。这可以减少将张量转换为量化值时的误差,因为异常值只会影响它所在的通道,而不是整个张量。
- signed: 这个参数是用来决定是否使用有符号量化。
- narrow_range: 这个参数是用来决定是否使用对称整数范围来表示有符号量化。对称整数范围是指在有符号量化中,使用相同数量的正负整数来表示数值。例如,在8位有符号量化中,如果使用对称整数范围,则表示范围为[-127, 127];如果不使用对称整数范围,则表示范围为[-128, 127]。
- scale_type: 这个参数是用来指定在量化过程中使用的比例因子类型,选项有float, power_of_two。比例因子类型是指在量化过程中,使用什么样的数值来表示比例因子。float类型表示使用浮点数来表示比例因子;power_of_two类型表示使用2的幂次方来表示比例因子。float类型可以更精确地表示比例因子,提高模型精度;power_of_two类型可以更简单地计算比例因子,提高运算效率。
- calib_statistic_method: 如果多批次数据的分布不一致,那么需要用一种统计方法来确定最优的比例。不同的比例会影响量化后的模型精度和性能。这里提供了四种方法:
- modal(模态):选择出现次数最多的比例作为最优比例。
- max(最大值):选择所有批次中最大的比例作为最优比例。
- mean(平均值):计算所有批次的比例的平均值作为最优比例。
- median(中值):排序所有批次的比例,选择中间位置的比例作为最优比例。
Vitis AI默认的量化配置:
"convert_relu6_to_relu": 关闭,
"include_cle": 启用,
"keep_first_last_layer_accuracy": 关闭,
"keep_add_layer_accuracy": 关闭,
"include_bias_corr": 开,
"target_device": "DPU",
"quantizable_data_type": ["input", "weights", "bias", "activation"],
"bit_width": 8,
"method": "diffs",
"round_mode": "std_round",
"symmetry": 启用,
"per_channel": 关闭,
"signed": 启用,
"narrow_range": 关闭,
"scale_type": "power_of_two",
"calib_statistic_method": "modal"
配置完毕后,需要按照上一讲的内容,进行校准和量化:
【KV260视觉入门套件试用体验】Vitis AI 进行模型校准和来量化
【KV260视觉入门套件试用体验】Vitis AI 进行模型校准和来量化 - 智能硬件论坛 - 电子技术论坛 - 广受欢迎的专业电子论坛!
config_file= "./int8_config.json"
quantizer= torch_quantizer(quant_mode=quant_mode,
module=model,
input_args=(input),
device=device,
quant_config_file=config_file)
唯一的不同,是以上代码部分需要引用新配置的json文件。
5. 模型编译:
vai_c_xir -x /PATH/TO/quantized.xmodel \\\\-a /PATH/TO/arch.json \\\\-o /OUTPUTPATH \\\\-n netname
编译模型,只需这一条指令。
附:查看支持的型号
!ls -l /opt/vitis_ai/compiler/arch/---
total 24
drwxr-xr-x 4 root root 4096 Jun 12 2022 DPUCADF8H
drwxr-xr-x 8 root root 4096 Jun 12 2022 DPUCAHX8H
drwxr-xr-x 5 root root 4096 Jun 12 2022 DPUCAHX8L
drwxr-xr-x 3 root root 4096 Jun 12 2022 DPUCVDX8G
drwxr-xr-x 6 root root 4096 Jun 12 2022 DPUCVDX8H
drwxr-xr-x 5 root root 4096 Jun 12 2022 DPUCZDX8G
附:查看DPUCZDX8G支持的板卡
!ls -l /opt/vitis_ai/compiler/arch/DPUCZDX8G---
total 12
drwxr-xr-x 2 root root 4096 Jun 12 2022 KV260
drwxr-xr-x 2 root root 4096 Jun 12 2022 ZCU102
drwxr-xr-x 2 root root 4096 Jun 12 2022 ZCU104
执行完毕编译过程,就可以在对应目录中得到*.xmodel文件了~
6. 总结
本文主要介绍使用Vitis AI工具创建自定义的Xmodol,难点并不在工具本身,而是需要了解很多机器学习的知识。一个很好的出发点是使用Vitis Model Zoo库,是一个包含了大量预训练模型的资源库,这些模型涵盖了多种AI应用领域,如图像分类、目标检测、语义分割、人脸识别、自然语言处理等。我们可以利用这些模型作为一个起点,快速入门并开发自己的应用。这些是由Xilinx官方提供的经过优化和验证的模型,可以直接在Xilinx硬件平台上部署和运行。在熟悉自己的业务的需求,并建立数据集后,我们可以定制的模型。
这篇关于Vitis AI 迁移学习并部署在DPU中的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








