dataworks专题

dataworks学习--数据开发流程
数据开发流程 通常数据开发的总体流程包括数据产生、数据收集与存储、数据分析与处理、数据提取和数据展现与分享。 说明 上图中,虚线框内的开发流程均可基于阿里云大数据平台完成。 参考资料:1.MaxCompute studio FAQ
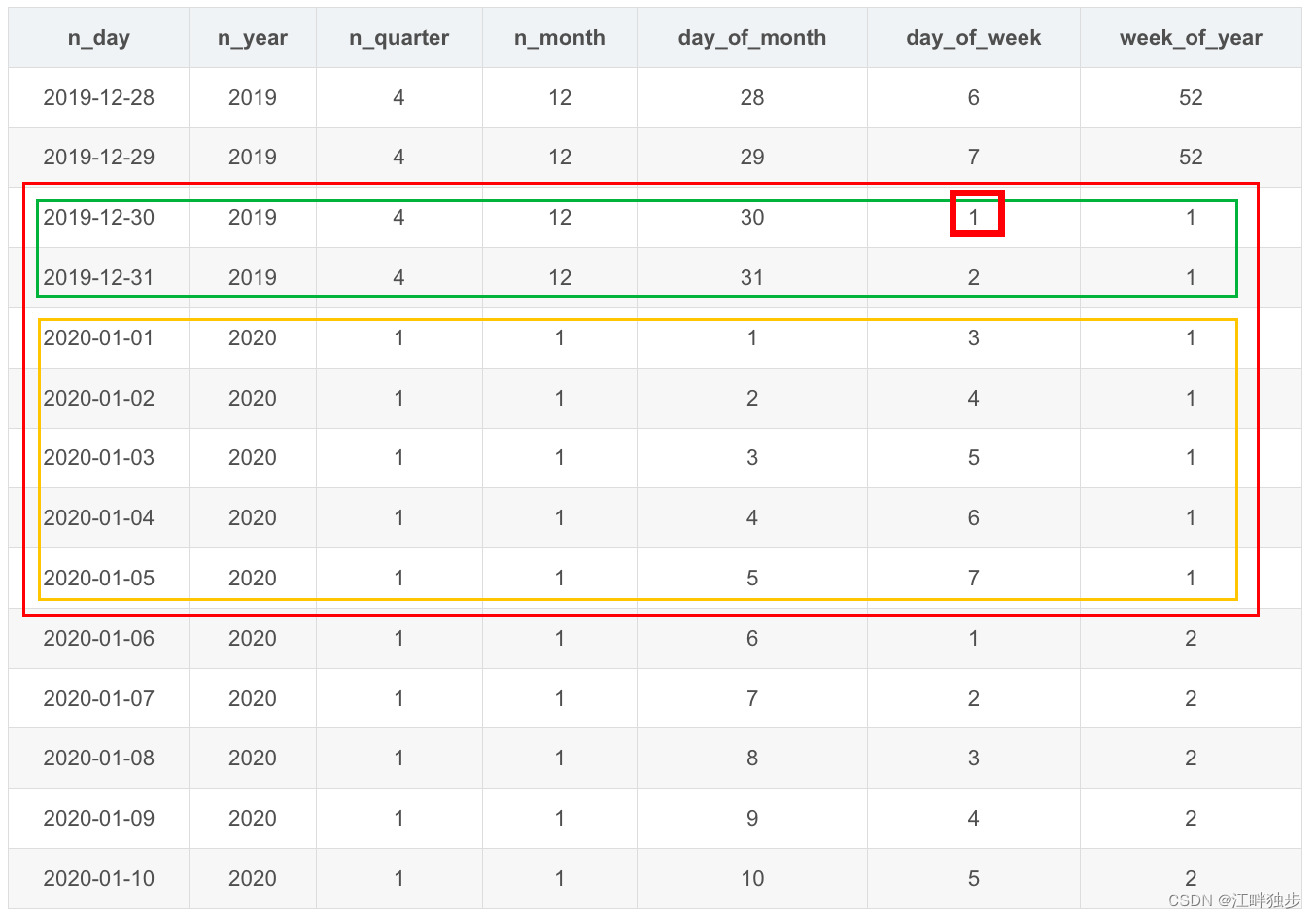
DataWorks+MaxCompute跨年取日期所在周的问题
一、背景 一些数据分析业务需求中,如订单金额、订单数量,时间粒度需要统计到周,如周同比,周环比。 一般我们都会事先创建一个类似如下的时间维度表。 实验SQL环境:DataWorks + MaxCompute dim_date表清单: n_dayn_yearn_quartern_monthday_of_monthday_of_weekweek_of_year2019-12-282019

阿里云DataWorks数据治理实践
DataWorks是阿里云提供的一站式大数据工场,它涵盖了数据集成、开发、治理、服务、质量和安全等全套数据研发工作。以下将详细阐述DataWorks在数据治理方面的实践。 首先,DataWorks的数据治理实践主要分为几个阶段。第一阶段是数据稳定性治理,这是首要保障的问题。DataWorks通过稳定可靠的调度服务,如阿里自研的天网调度系统,支撑每日千万级别的任务量,并解决复杂依赖问题。同时,规范

如何使用DataWorks的整库迁移给目标表名加上前缀
DataWorks的整库迁移的介绍本文不再细述,想了解的同学可以参考一下这个文档 整库迁移概览。下面主要给大家介绍一下如何使用整库迁移的时候,给目标表名加上前缀。 如何使用DataWorks的整库迁移给目标表名加上前缀 >>>阅读全文

【大数据】-- dataworks 创建odps 的 hudi 外表
文档:创建OSS外部表_云原生大数据计算服务 MaxCompute(MaxCompute)-阿里云帮助中心 举例:创建 odps 的 hudi 外表 CREATE EXTERNAL TABLE IF NOT EXISTS my_project.ods_hudi_mysql_words_h_all(id BIGINT COMMENT '主键id',`words`

DataWorks SQL代码编码原则和规范
编码原则 SQL代码的编码原则如下: 代码功能完善。代码行清晰、整齐,代码行的整体层次分明、结构化强。代码编写充分考虑执行速度最优的原则。代码中需要添加必要的注释,以增强代码的可读性。规范要求并非强制性约束开发人员的代码编写行为。实际应用中,在不违反常规要求的前提下,允许存在可以理解的偏差。SQL代码中应用到的所有SQL关键字、保留字都需使用全大写或小写,例如select/SELECT、fro

DataWorks快速入门
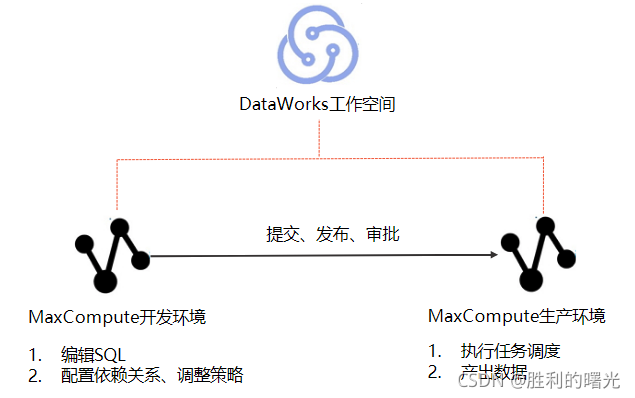
快速入门 入门概述 说明 如果您是第一次使用DataWorks,请确认已经根据准备工作模块的操作,准备好账号和工作空间角色等内容后,登录DataWorks控制台,单击相应工作空间后的进入数据开发,即可进行数据开发操作。本模块的操作在标准模式的工作空间下进行。如果您使用的是简单模式的工作空间,操作步骤同标准模式。但在提交任务时,不会区分开发环境和生产环境。 通常,通过DataWorks的

DataWorks产品架构
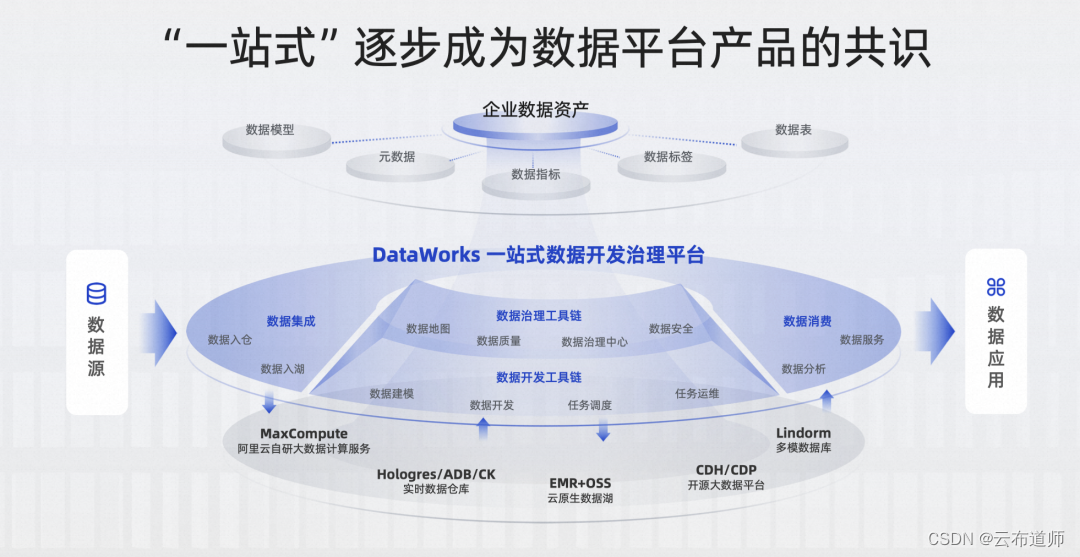
概述 DataWorks提供九个核心功能模块:以数据为基础,以全链路加工为核心,提供数据汇聚、研发、治理、服务等多种功能。既能满足平台用户的数据需求,又能为上层应用提供各种行业解决方案,整体功能架构如下图所示。 产品架构 数据集成:全领域数据汇聚 数据集成(Data Integration)是提供了可跨异构数据存储系统能力、可靠、安全、低成本、可弹性扩展的数据同步平台。 目前数据集成
DataWorks基本概念
什么是DataWorks DataWorks是从工作室、车间到工具集都齐备的一站式大数据工场,助力您快速完成数据集成、开发、治理、服务、质量和安全等全套数据研发工作。 本文为您介绍什么是DataWorks,以及DataWorks的功能和使用限制。 DataWorks(数据工场,原大数据开发套件)是阿里云重要的PaaS(Platform-as-a-Service)平台产品,为您提供数据集成、数
【2023 云栖】阿里云田奇铣:大模型驱动 DataWorks 数据开发治理平台智能化升级
云布道师 本文根据 2023 云栖大会演讲实录整理而成,演讲信息如下: 演讲人:田奇铣 | 阿里云 DataWorks 产品负责人 演讲主题:大模型驱动 DataWorks 数据开发治理平台智能化升级 随着大模型掀起 AI 技术革新浪潮,大数据也进入了与 AI 深度结合的创新时期。2023 年云栖大会上,阿里云 DataWorks 产品负责人田奇铣发布了 DataWorks Copilot
阿里云DataWorks提交脚本报错。当前节点依赖的父节点输出名: xxxx 不存在,不能提交本节点,请确保拥有该输出名的父节点:已被提交!
错误描述:在DataWorks里提交脚本一直报错,报错信息为: 当前节点依赖的父节点输出名:qzspace.ods_sku_info_df,qzspace.ods_base_category3_df,qzspace.ods_base_category2_df,qzspace.ods_base_category1_df,qzspace.ods_base_trademark_df不存在,不能提交本节点

阿里云DataWorks独享资源组
1、数据产出的企业级要求: 2、DataWorks任务常见问题 A、任务无产出且日志显示等待gateway资源 B、同步任务日志出现大量Speed为零的情况,导致大批量任务一直处于运行中状态 3、DataWorks任务资源使用机制、问题及解决 DataWorks以两次计算资源,按照用户预期(依赖关系、定时时间)运行用户 A、默认共享资源组使用机制 如下图,为2

【2023云栖】大模型驱动DataWorks数据开发治理平台智能化升级
随着大模型掀起AI技术革新浪潮,大数据也进入了与AI深度结合的创新时期。2023年云栖大会上,阿里云DataWorks产品负责人田奇铣发布了DataWorks Copilot、DataWorks AI增强分析、DataWorks湖仓融合数据管理等众多新产品能力,让DataWorks这款已经发展了14年的大数据开发治理平台产品,从一站式向智能化不断升级演进。 Data+AI双轮驱动 进入AIGC
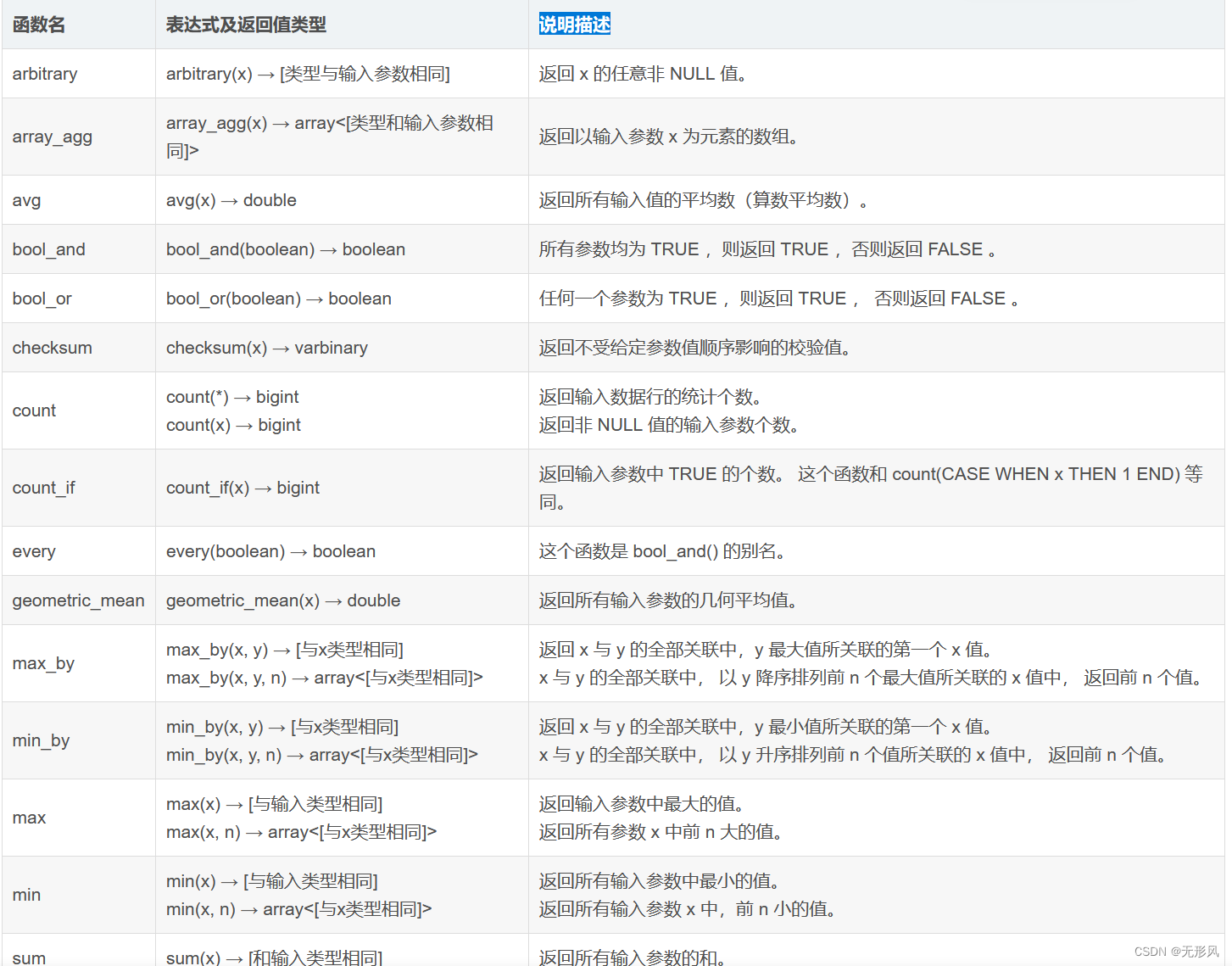
数据抽取+dataworks的使用+ADB的应用
一,大数据处理之数据抽取 1,什么是数据抽取 在大数据领域中,数据抽取是指从原始数据源中提取所需的数据子集或特定数据项的过程, 数据抽取是数据预处理的重要步骤,它为后续的数据分析和建模提供了基础。 2,为什么要进行数据抽取 1,大数据量中,频繁的大批量查询需要很大的计算资源和时间,会影响数据库的性能,从而影响应用业务逻辑的执行 2,业务与数据分离,可以在不影响业务的前提下,更好的实现数据处

阿里云 DataWorks v2.0 常见问题与难点解析整理
一、依赖关系配置 依赖关系原理概述三种依赖配置方式“自动解析”配置依赖关系:推荐使用手动配置依赖关系“自动推荐”配置依赖关系 1.1 依赖关系原理概述 可扩展性差,缺乏解耦重跑任务的成本太高 输出名称 每个节点(Task)输出点的名称。用于在单个租户(阿里云账号)内设置依赖关系时,连接上下游两个节点(Task)的虚拟实体。 【原则】 每个节点必须配置至少一个本节点输出名称、一个
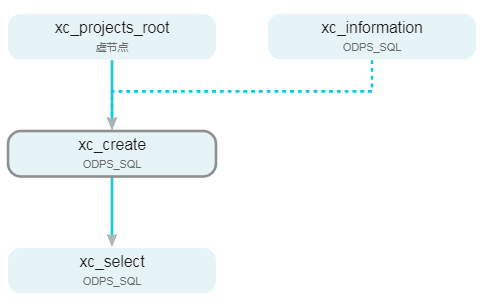
DataWorks:依赖上一周期(跨周期依赖)解析
本文档均以修改xc_create节点的配置为案例。 DataWorks的三种跨周期依赖形式: ①一层子节点: 节点依赖关系:依赖当前节点的下游,例如 节点A存在下游节点B、C、D三个节点,依赖一层子节点是节点A依赖B、C、D三个节点的上一周期。 业务场景:本次 任务运行依赖上一周期下游节点对本节点的结果表(本节点输出表)进行清洗的最终结果(是否正常产出)。 ②本节点: 节点依
灵活运用DataWorks参数配置
阅读全文请点击 数据工场DataWorks (原大数据开发套件Data IDE) 是基于MaxCompute作为计算和存储引擎的,并用于工作流可视化开发和托管调度运维的海量数据离线分析平台。DataWorks可以按照时间和依赖关系,实现任务的全面托管和调度。在这里,笔者跟大家探讨一下众多DataWorks用户经常遇到的一类问题,就是在DataWorks中如何灵活运用参数配置这个功能。 很多