本文主要是介绍DataWorks基本概念,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
什么是DataWorks
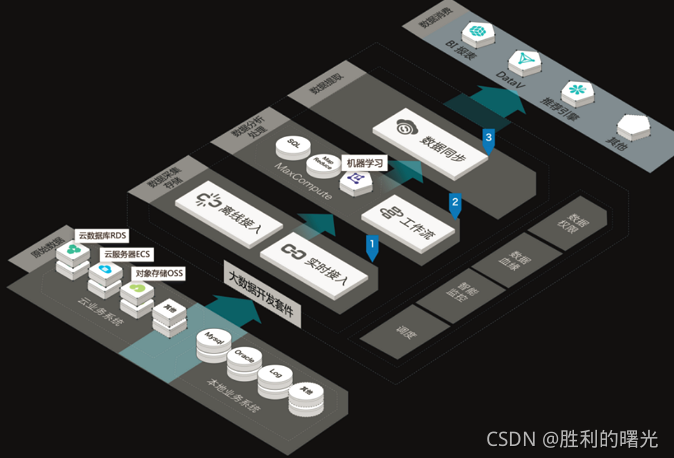
DataWorks是从工作室、车间到工具集都齐备的一站式大数据工场,助力您快速完成数据集成、开发、治理、服务、质量和安全等全套数据研发工作。
本文为您介绍什么是DataWorks,以及DataWorks的功能和使用限制。
DataWorks(数据工场,原大数据开发套件)是阿里云重要的PaaS(Platform-as-a-Service)平台产品,为您提供数据集成、数据开发、数据地图、数据质量和数据服务等全方位的产品服务,一站式开发管理的界面,帮助企业专注于数据价值的挖掘和探索。
DataWorks支持多种计算和存储引擎服务,包括离线计算MaxCompute、开源大数据引擎E-MapReduce、实时计算(基于Flink)、机器学习PAI、图计算服务Graph Compute和交互式分析服务等,并且支持用户自定义接入计算和存储服务。DataWorks为您提供全链路智能大数据及AI开发和治理服务。
您可以使用DataWorks,对数据进行传输、转换和集成等操作,从不同的数据存储引入数据,并进行转化和开发,最后将处理好的数据同步至其它数据系统。
基本概念
工作空间
工作空间是DataWorks管理任务、成员,分配角色和权限的基本单元。工作空间管理员可以加入成员至工作空间,并赋予工作空间管理员、开发、运维、部署、安全管理员或访客角色,以实现多角色协同工作。
说明 建议您根据部门或业务板块来划分工作空间。
一个工作空间支持绑定MaxCompute、E-MapReduce和实时计算等多种类型的计算引擎实例。绑定引擎实例后,即可在工作空间开发和调度引擎任务。
说明 业务流程可以被多个解决方案复用。
解决方案
您可以自定义组合部分业务流程为一个解决方案。
组件
您可以将SQL中的通用逻辑抽象为组件,提高代码的复用性。
SQL代码的处理过程通常是引入一到多个源数据表,通过过滤、连接和聚合等操作,加工出新的业务需要的目标表。组件是带有多个输入参数和输出参数的SQL代码过程模板。
任务(Task)
任务是对数据执行的操作的定义,示例如下:
- 通过数据同步节点任务,将数据从RDS同步至MaxCompute。
- 通过MaxCompute SQL节点任务,运行MaxCompute SQL来进行数据的转换。
每个任务使用0或0个以上的数据表(数据集)作为输入,生成一个或多个数据表(数据集)作为输出。
任务主要分为节点任务(Node Task)、工作流任务(Flow Task)和内部节点(inner Node)。

实例(Instance)
实例是某个任务在某时某刻执行的一个快照。调度系统中的任务,经过调度系统、手动触发运行后,会生成一个实例。实例中会有任务的运行时间、运行状态和运行日志等信息。
提交(Submit)
提交是指开发的节点任务、业务流程,从DataWorks开发环境发布至调度系统的过程。完成提交后,相应的代码、调度配置全部合并至调度系统中,调度系统根据相关配置进行调度操作。
说明 未提交的节点任务、业务流程不会进入调度系统。
脚本开发(Script)
脚本开发是提供给数据分析使用的一个代码存储空间。脚本开发的代码无法发布到调度系统,无法进行调度参数配置,仅可以进行部分数据查询分析的工作。
资源、函数
资源、函数均为MaxCompute的概念,详情请参见资源和函数。
输出名称
输出名称:每个任务(Task)输出点的名称。它是您在单个租户(阿里云账号)内设置依赖关系时,用于连接上下游两个任务(Task)的虚拟实体。
当您在设置某任务与其它任务形成上下游依赖关系时,必须根据输出名称(而不是节点名称或节点ID)来完成设置。设置完成后该任务的输出名也同时作为其下游节点的输入名称。

说明 输出名称可以作为某个Task在同租户内,区别于其它Task的唯一概念对象,每个节点的输出名称默认为工作空间名称.系统生成9位数字.out。您可以对Task增加自定义输出名,但需要注意输出节点名称在租户内不允许重复。
元数据
元数据是数据的描述数据,可以为数据说明其属性(名称、大小、数据类型等),或结构(字段、类型、长度等),或其相关数据(位于何处、拥有者、产出任务、访问权限等)。DataWorks中元数据主要指库、表相关的信息,元数据管理对应的主要应用是数据地图。
补数据
完成周期任务的开发,将任务提交发布之后,任务会按照调度配置定时运行。如果您希望对历史时间段内的数据进行计算,您可以使用补数据功能。补数据操作生成的补数据实例将按照指定的业务日期运行。
数据开发流程
通常数据开发的总体流程包括数据产生、数据收集与存储、数据分析与处理、数据提取和数据展现与分享。

数据开发的流程如下所示:
1.数据产生:业务系统每天会产生大量结构化的数据,存储在业务系统所对应的数据库中,包括MySQL、Oracle和RDS等类型。
2.数据收集与存储:您需要同步不同业务系统的数据至MaxCompute中,方可通过MaxCompute的海量数据存储与处理能力分析已有的数据。
DataWorks提供数据集成服务,可以支持多种数据源类型,根据预设的调度周期同步业务系统的数据至MaxCompute。
3.数据分析与处理:完成数据的同步后,可以对MaxCompute中的数据进行加工(MaxCompute SQL、MaxCompute MR)、分析与挖掘(数据分析、数据挖掘)等处理,从而发现其价值。
4.数据提取:分析与处理后的结果数据,需要同步导出至业务系统,以供业务人员使用其分析的价值。
5.数据展现与分享:数据提取成功后,可以通过报表、地理信息系统等多种展现方式,展示与分享大数据分析、处理后的成果。
简单模式和标准模式的区别
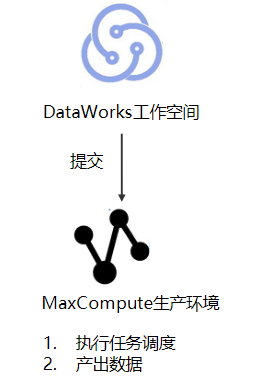
简单模式的工作空间
简单模式下,一个DataWorks工作空间对应一个计算引擎(项目、实例或数据库),无法设置开发环境和生产环境,只能进行简单的数据开发。简单模式的工作空间无法对数据开发流程和表权限进行强控制。
以MaxCompute为例,简单模式工作空间的流程如下。
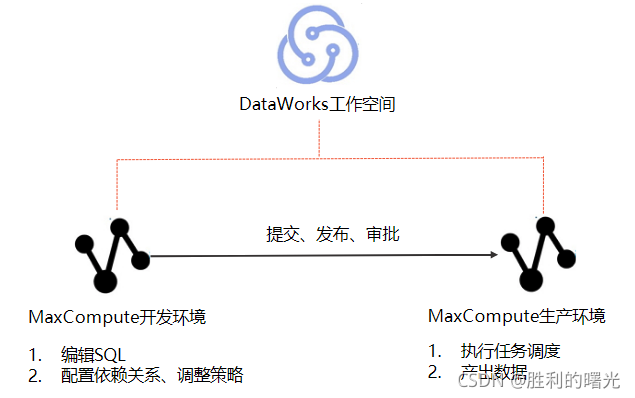
标准模式的工作空间
标准模式的工作空间下,一个DataWorks工作空间对应两个计算引擎(项目、实例或数据库)。与简单模式的工作空间相比,标准模式的工作空间有如下不同:
- 所有代码仅支持在开发环境编辑,您无法修改生产环境的代码。
- 提交任务后,任务会进入开发环境调度系统。但实际不会自动调度,仅作为冒烟测试使用。如果您需要自动调度运行任务,请发布任务至生产环境。发布任务前,需要项目管理员或运维角色的成员审批通过,才能发布成功。
以MaxCompute为例,标准模式工作空间的流程如下。
这篇关于DataWorks基本概念的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





