本文主要是介绍数据抽取+dataworks的使用+ADB的应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一,大数据处理之数据抽取
1,什么是数据抽取
在大数据领域中,数据抽取是指从原始数据源中提取所需的数据子集或特定数据项的过程,
数据抽取是数据预处理的重要步骤,它为后续的数据分析和建模提供了基础。
2,为什么要进行数据抽取
1,大数据量中,频繁的大批量查询需要很大的计算资源和时间,会影响数据库的性能,从而影响应用业务逻辑的执行
2,业务与数据分离,可以在不影响业务的前提下,更好的实现数据处理、数据分析,进而产出数据报表
二,阿里大数据平台dataworks实现数据抽取
1,数据抽取方式
1,抽取方式-全量抽取:在数据量不大时可以选中按照类似创建时间字段进行每次全量抽取,实现简单
2,抽取方式-增量抽取:大数据量中全量抽取效率过低,应选择按照类似修改时间字段进行每次增量抽取
2,数据抽取工具阿里dataworks
1,dataworks简单介绍
阿里云产品文档地址:https://help.aliyun.com/zh/dataworks/product-overview/
DataWorks基于MaxCompute、Hologres、EMR、AnalyticDB、CDP等大数据引擎,为数据仓库、数据湖、湖仓一体等解决方案提供统一的全链路大数据开发治理平台。
2,dataworks使用流程图
dataworks使用总体流程
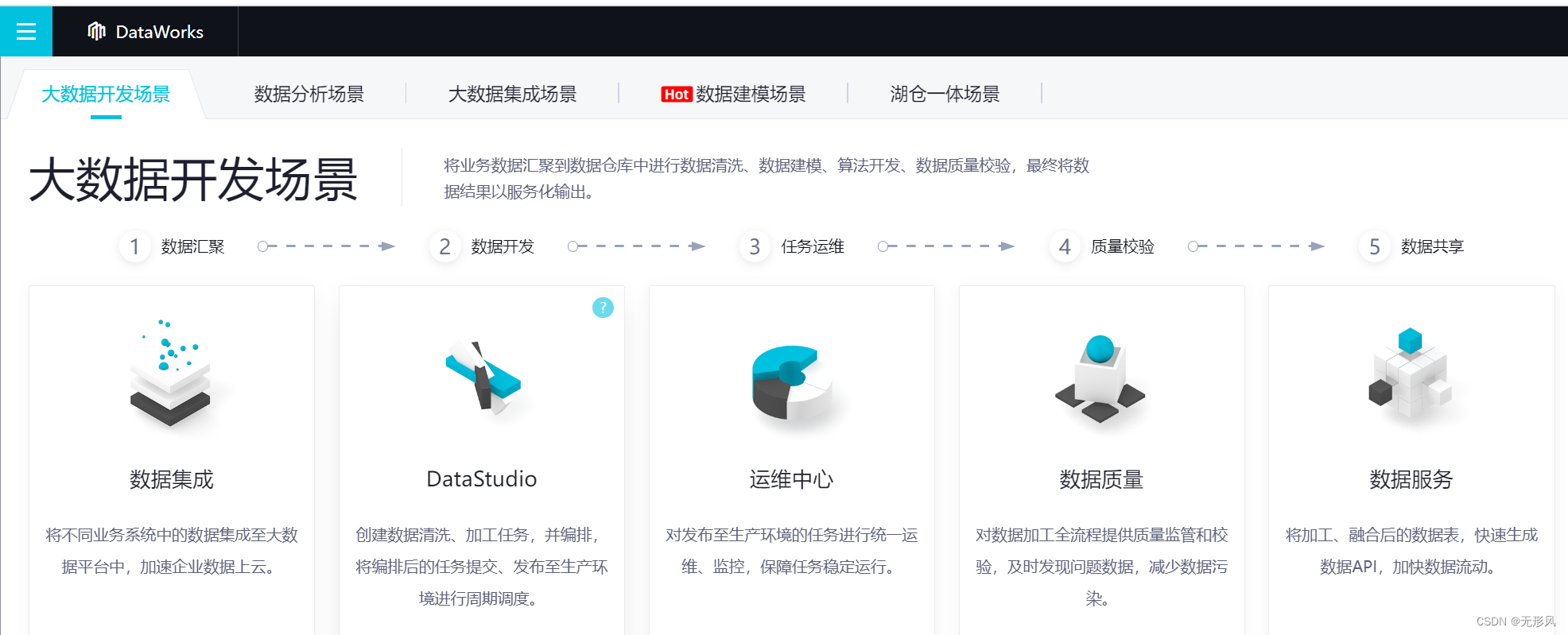
数据开发流程
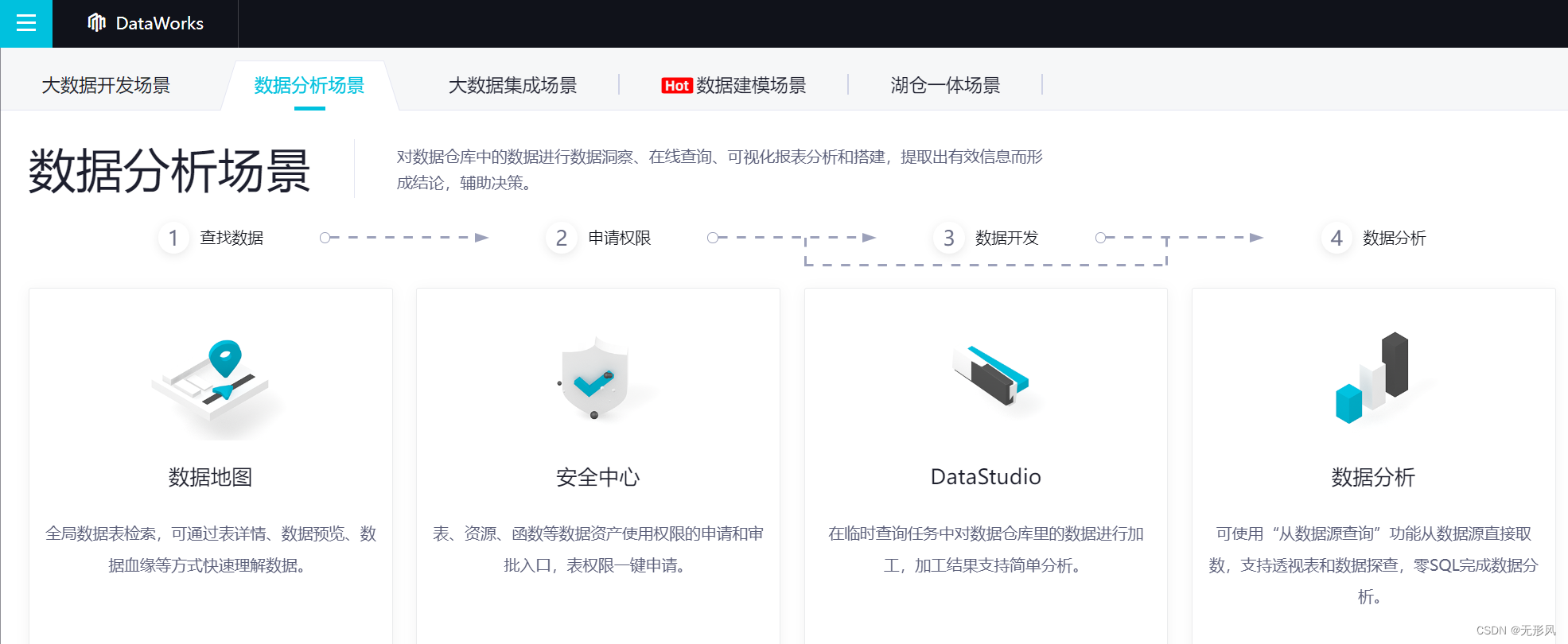
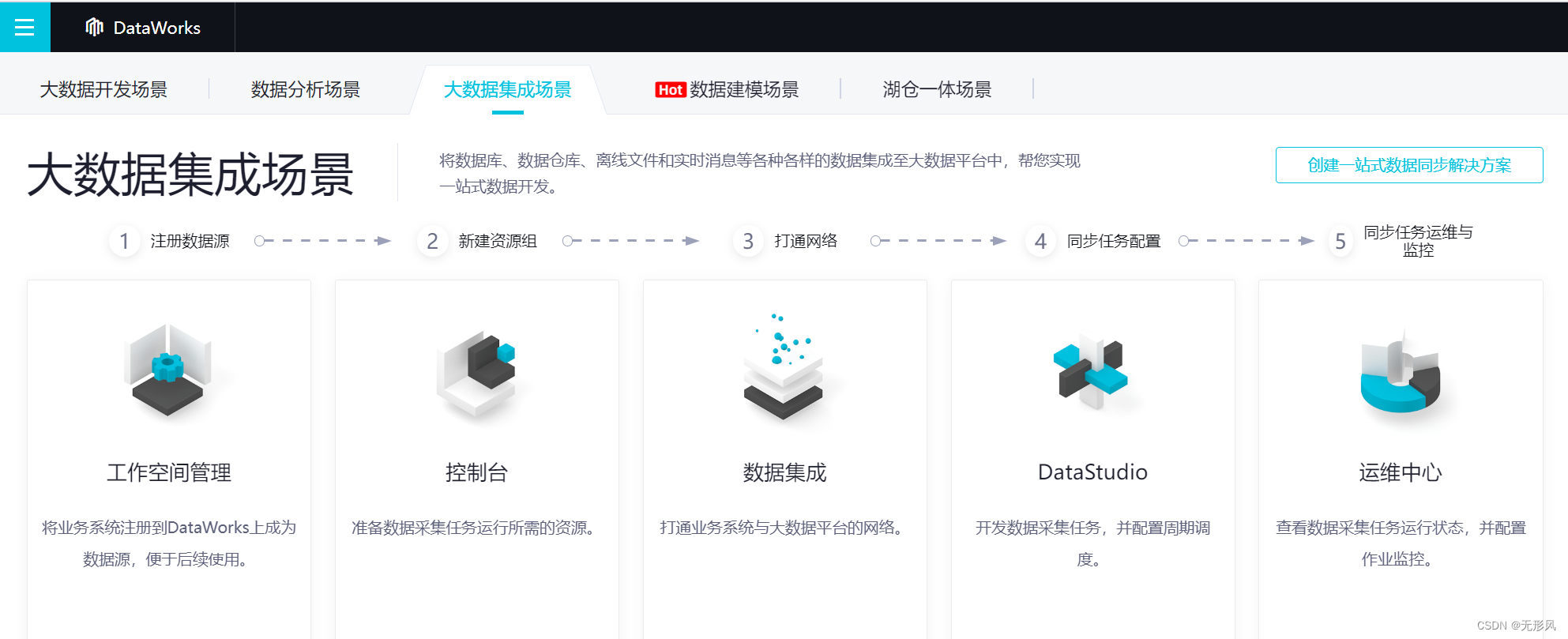
数据集成流程
3,数据地图
搜索需要使用的源数据表——>申请表权限
4,数据开发(DataStudio)
新建一个数据处理的业务流程
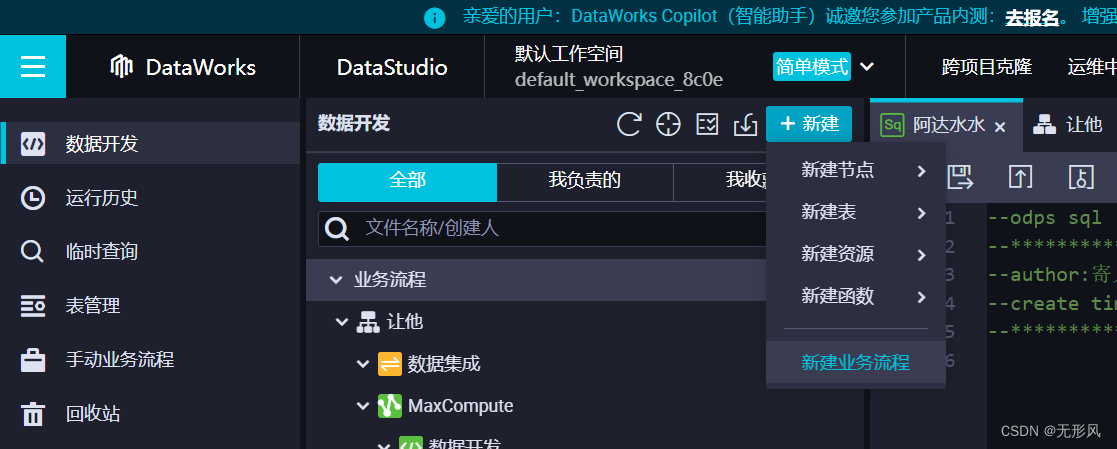
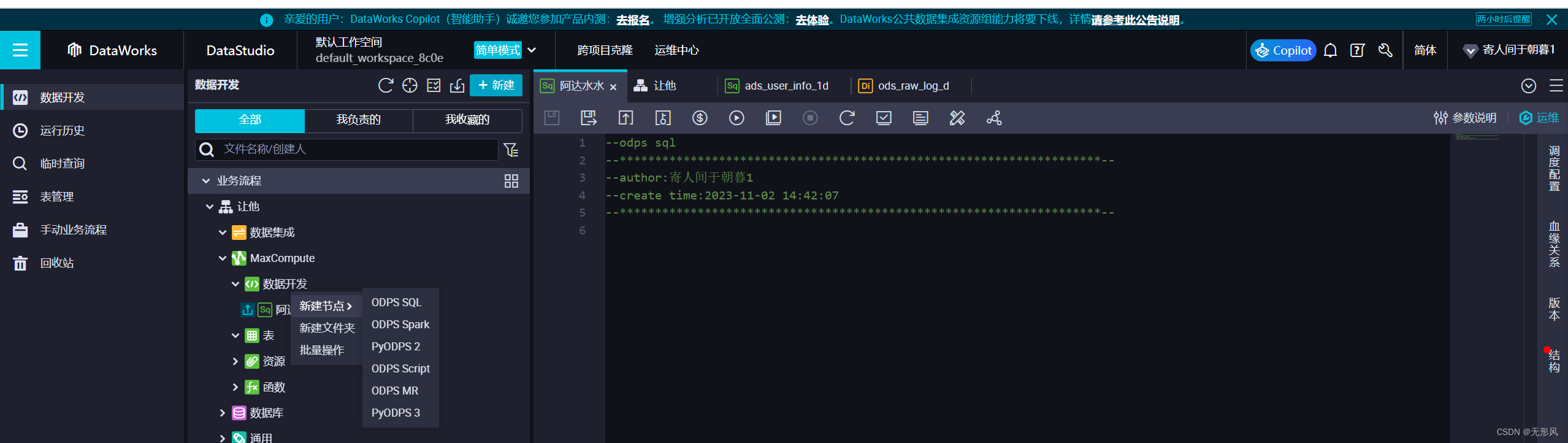
新建数据处理sql文件编写数据处理sql:业务流程下MaxCompute——>数据开发——>新建节点——>ODPS SQL——>编写数据处理汇集的查询sql并调试通过
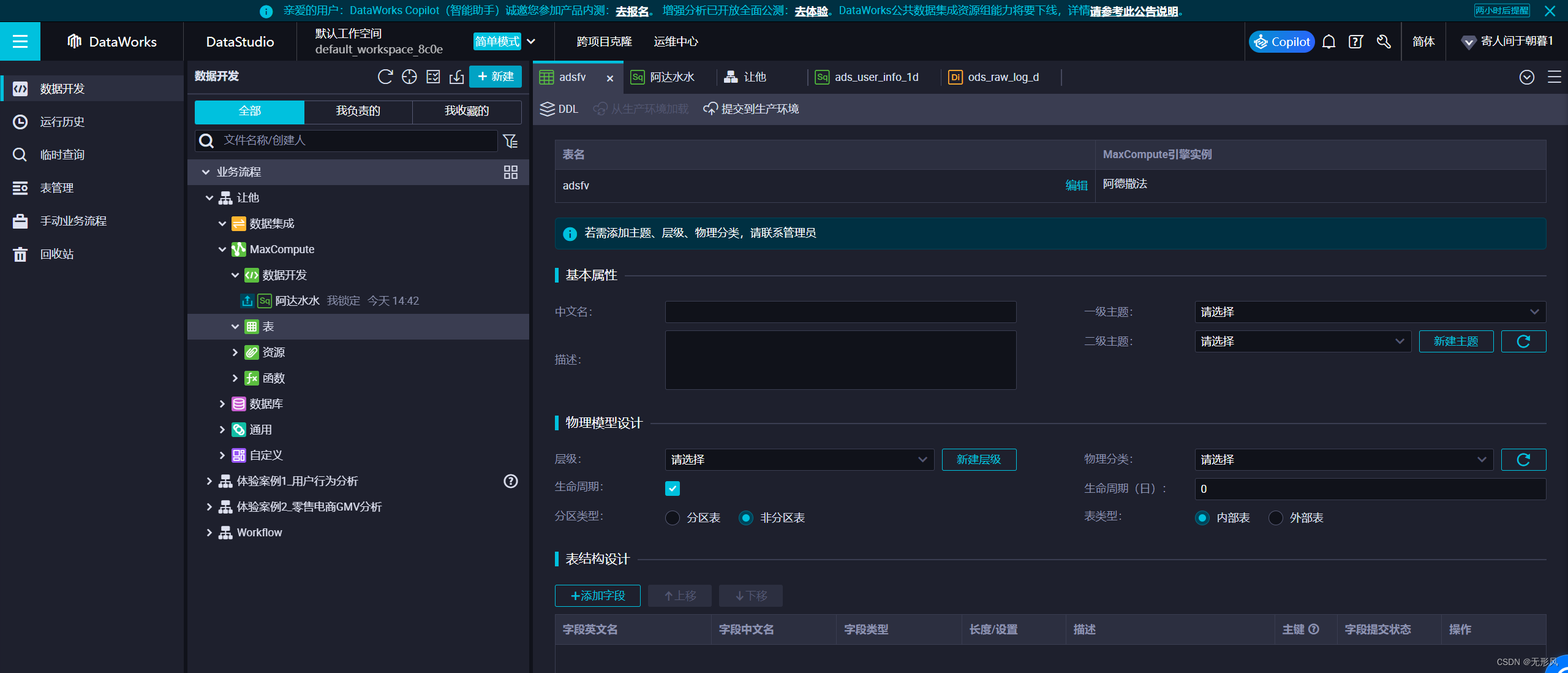
新建数据处理后的中间层表:业务流程下MaxCompute——>表——>新建表
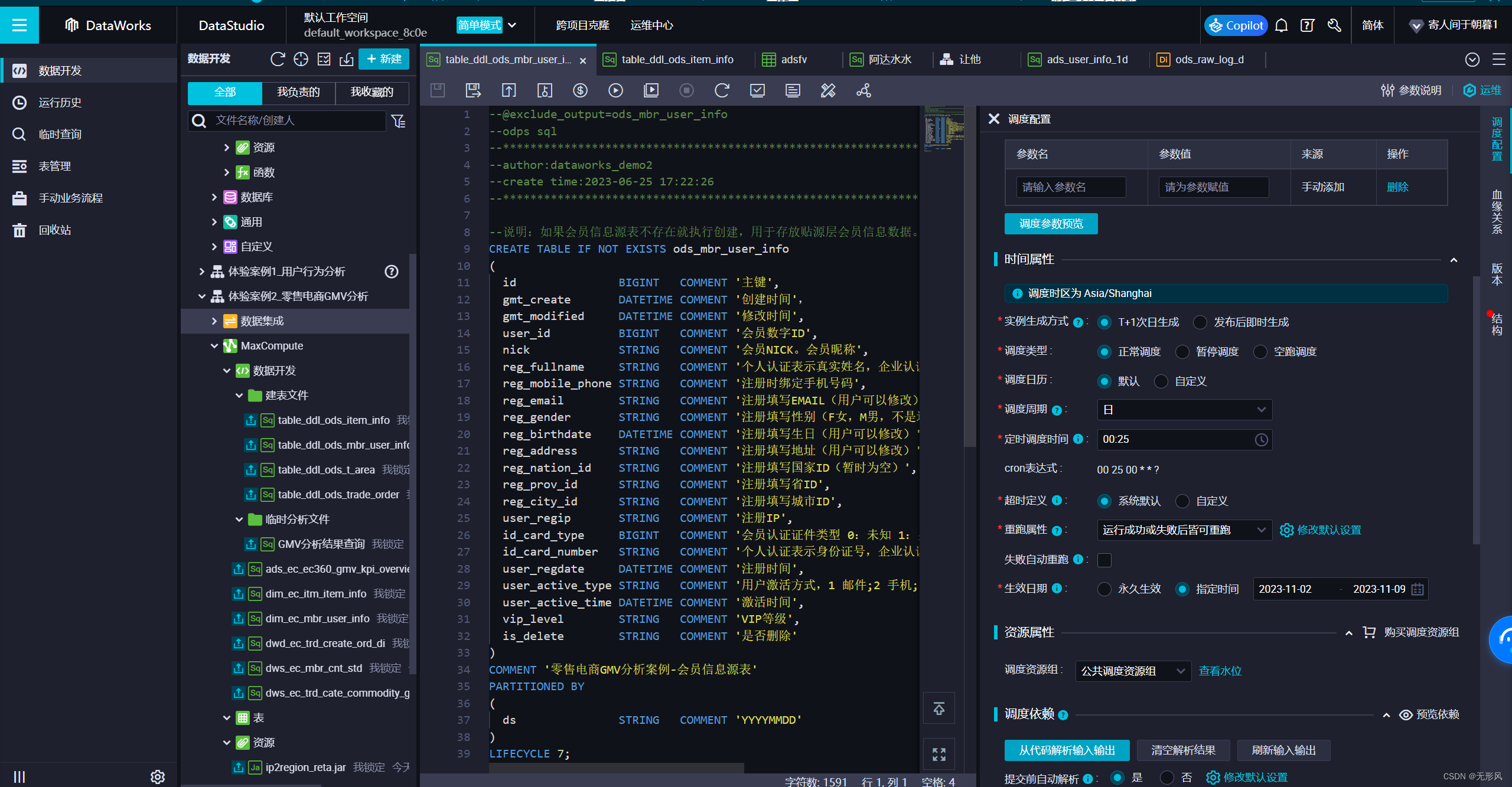
配置往数据处理后的中间层表同步的ODPS SQL的调度配置:重点为调度时间配置+调度依赖配置
注意:若所依赖的数据源表和数据处理后的中间层表不在同一工作空间下,则无法绑定依赖关系,则需观察数据源表的数据生成时间,手动设置ODPS SQL的调度时间延后
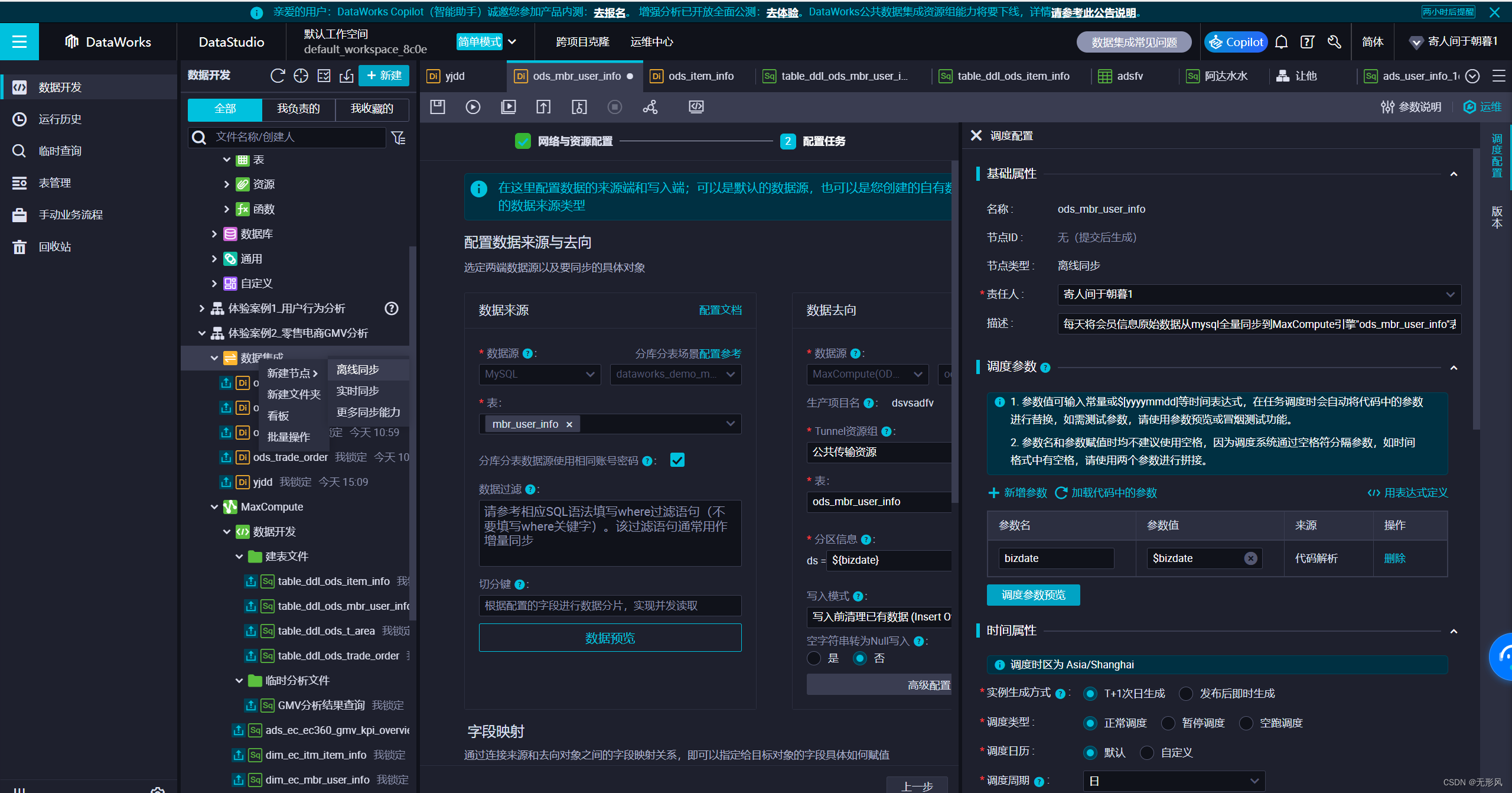
新建数据集成任务:数据集成——>新建节点——>离线同步——>选择数据来源(数据处理建立的ads层临时表)
——>选择数据去向——>调度配置配置时间属性等参数
4,ODPS SQL的开发规范+常用sql函数
1,sql语句全部大写,格式化操作
2,sql参考:https://help.aliyun.com/zh/maxcompute/user-guide/sql-3/
日期与时间函数:https://help.aliyun.com/zh/maxcompute/user-guide/date-functions
字符串函数:https://help.aliyun.com/zh/maxcompute/user-guide/string-functions
聚合函数:https://help.aliyun.com/zh/maxcompute/user-guide/aggregate-functions
三,ADB数据库的应用——数据抽取后的应用
1,ADB数据库注意点
1,adb表可以插入,可以带条件删除,不支持修改命令,不支持清空表表命令,不支持delete全量删除
2,adb表支持主键冲突——即主键冲突时不会多次插入数据
3,AnalyticDB MySQL版集群默认编码格式为utf-8,相当于MySQL中的utf8mb4编码,暂不支持其他编码格式。
4,AnalyticDB MySQL版不支持unsigned约束(指定当前列的数值为非负数)。
2,建表注意事项
1,AnalyticDB MySQL版的表分为分区表和维度表。
分区表:又称普通表,用于存储业务数据的度量值。AnalyticDB MySQL版根据分布键将数据打散在各个数据节点上。每个节点再根据分区键将数据文件拆分为不同的文件。
如果业务明确有增量数据导入需求,创建分区表时可以同时指定分布键和分区键,来实现数据的增量同步
维度表:维度表是业务特性描述的集合,每个节点冗余一份。通常数据量小,变化频率低。
2,主键中必须包含分布键和分区键,建议将分区键和分布键放在组合主键的前部
3,在普通表中定义表的分布键:DISTRIBUTED BY HASH(column_name,…),按照column_name的HASH值进行分片。
AnalyticDB MySQL版支持将多个字段作为分布键。
AnalyticDB MySQL版不支持修改分布键。
4,PARTITION BY VALUE(column_name)表示使用column_name的值来做分区
5,updateType:表数据更新方式:
realtime:实时更新,只支持实时写入数据。
batch:批量更新,只支持批量离线导入数据。不带此参数时,默认为批量更新。
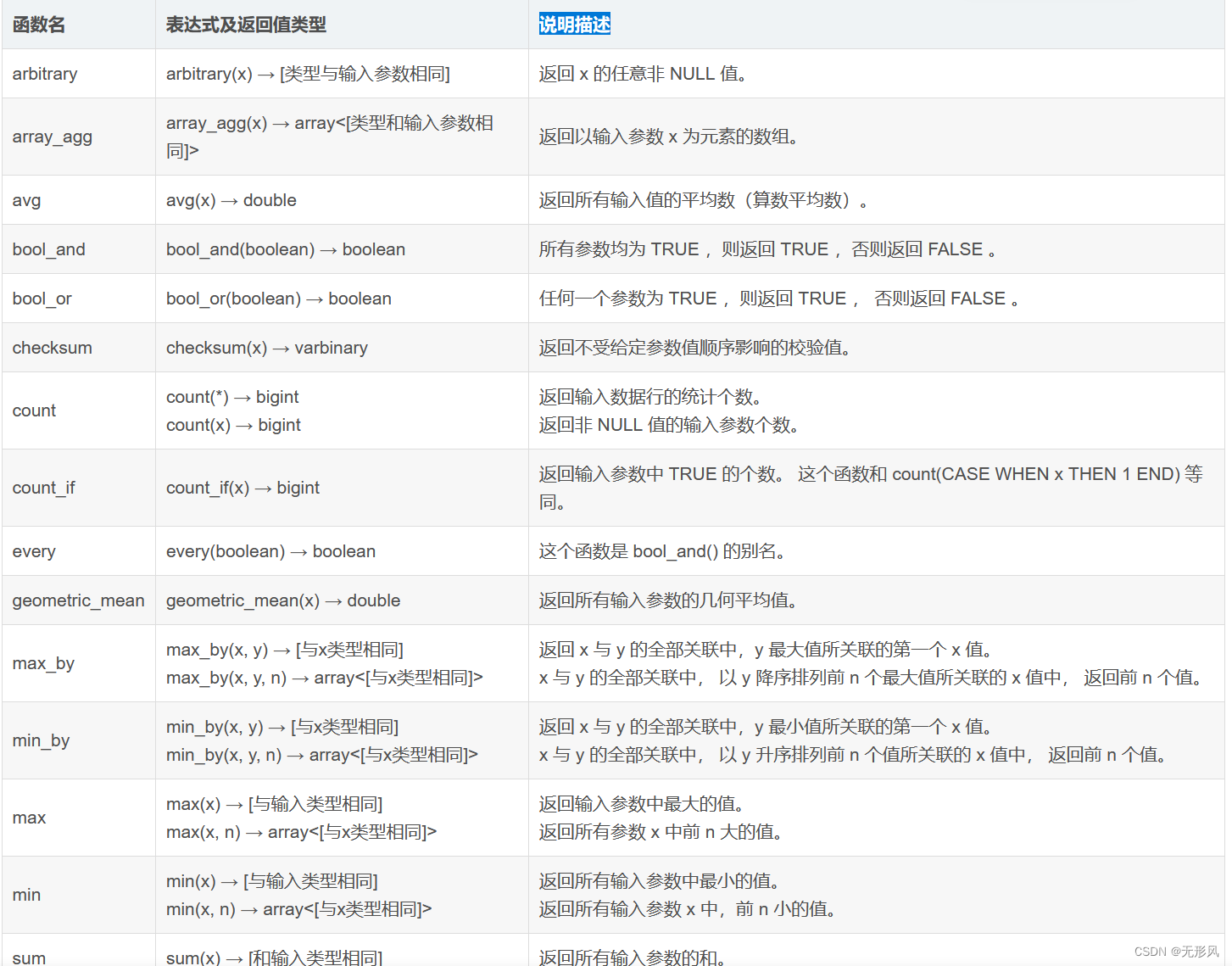
3,常规聚合函数
4,窗口函数
窗口函数是基于查询结果的行数据进行计算的函数,运行在 HAVING 子句之后 ORDER BY 子句之前。触发一个窗口函数需要特殊的关键字 OVER子句来指定窗口。
一个窗口包含三个组成部分:
分区规范:用于将输入行分裂到不同的分区中,与 GROUP BY 子句的分裂过程相似。
排序规范:用于决定输入数据行在窗口函数中执行的顺序。
窗口框架:用于指定一个滑动窗口的数据,以给窗口函数指定需要处理的行数据。如果这个框架没有指定,则默认是 RANGE UNBOUNDED PRECEDING (与 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW 相同),默认框架包含当前分区中所有从开始到目前行所有数据。
cume_dist() → bigint
返回一组数值中每个值的累计分布。结果返回的是按照窗口分区下窗口排序后的数据集下,
当前行前面包括当前行数据的行数。因此,排序中任何关联值均会计算成相同的分布值。dense_rank() → bigint
返回一组数值中每个数值的排名。这个函数与 rank() 相似,但该函数关联值不会产生顺序上的空隙。ntile(n) → bigint
将每个窗口分区的数据分裂到 n 个桶中(桶号从 1 到最大 n ,桶号值最多间隔是 1)。
如果窗口分区中的数据行数不能均匀的分到每一个桶中,则剩余值将每一个桶分一个,从第一个桶开始。percent_rank() → bigint
返回数据集中每个数据的排名百分比。结果是根据 (r - 1) / (n - 1) 计算的,
其中 r 是由 rank() 计算 的当前行排名, n 是当前窗口分区内总的行数。rank() → bigint
返回数据集中每个值的排名。排名值是根据当前行之前的行数加1,不包含当前行,
因此排序的关联值可能产生顺序上的空隙。 rank() 排名会对每个窗口分区进行计算。row_number() → bigint
根据行在窗口分区内的顺序,为每行数据返回一个唯一的顺序的行号,从1开始。值函数
first_value(x) → [与输入类型相同]
返回窗口内的第一个值。last_value(x) → [与输入类型相同]
返回窗口内的最后一个值。nth_value(x, offset) → [与输入类型相同]
返回窗口内指定偏移的值。偏移量从 1 开始。如果偏移量是null或者大于窗口内值的个数,返回null。
如果偏移量为0或者负数,则会报错。lead(x[, offset[, default_value]]) → [与输入类型相同]
返回窗口内当前行往后偏移 offset 的值。偏移量可以是标量表达式,起始值是0(即当前数据行),默认是1 。
如果偏移量的值是 null 或者大于窗口长度,则返回 default_value;如果没有指定偏移量,则会返回 null 。lag(x[, offset[, default_value]]) → [与输入类型相同]
返回窗口内当前行往前偏移 offset 的值。偏移量可以是标量表达式,起始值是0(即当前数据行),默认是1 。
如果偏移量的值是null或者大于窗口长度,则返回 default_value;如果没有指定偏移量,则返回 null 。
这篇关于数据抽取+dataworks的使用+ADB的应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





