cvpr2023专题

《Zero-Shot Object Counting》CVPR2023
摘要 论文提出了一种新的计数设置,称为零样本对象计数(Zero-Shot Object Counting, ZSC),旨在测试时对任意类别的对象实例进行计数,而只需在测试时提供类别名称。现有的类无关计数方法需要人类标注的示例作为输入,这在许多实际应用中是不切实际的。ZSC方法不依赖于人类标注者,可以自动操作。研究者们提出了一种方法,可以从类别名称开始,准确识别出最佳的图像块(patches),用

CVPR2023检测相关Detection论文速览上
Paper1 AUNet: Learning Relations Between Action Units for Face Forgery Detection 摘要原文: Face forgery detection becomes increasingly crucial due to the serious security issues caused by face manipulati
CVPR2023论文速览自监督Self-Supervised相关38篇
Paper1 Self-Supervised Video Forensics by Audio-Visual Anomaly Detection 摘要原文: Manipulated videos often contain subtle inconsistencies between their visual and audio signals. We propose a video foren
![Paper速读-[Visual Prompt Multi-Modal Tracking]-Dlut.edu-CVPR2023](https://img-blog.csdnimg.cn/direct/287ae89367ea4728ad458171b35915ee.png)
Paper速读-[Visual Prompt Multi-Modal Tracking]-Dlut.edu-CVPR2023
文章目录 简介关于具体的思路问题描述算法细节实验结果模型的潜力模型结果 论文链接:Visual Prompt Multi-Modal Tracking 开源代码:Official implementation of ViPT 简介 这篇文章说了个什么事情呢,来咱们先看简单的介绍图 简单来说,这篇文章主要干了这么一个事情: 以前的多模态呢,都是直接提取特征然后拼接

注意力机制篇 | YOLOv8改进之引入STA(Super Token Attention)超级令牌注意力机制 | CVPR2023
前言:Hello大家好,我是小哥谈。超级令牌注意力机制是一种基于Transformer的模型,用于处理长文本序列的任务。它通过引入超级令牌(Super Token)来减少输入序列中的填充标记,从而提高计算效率和模型性能。🌈 目录 🚀1.基础概念

Super Resolution in CVPR2023
标题链接Perception-Oriented Single Image Super-Resolution using Optimal Objective Estimationhttps://cvpr.thecvf.com/virtual/2023/poster/22477Super-Resolution Neural Operatorhttps://openaccess.thecvf.com/c
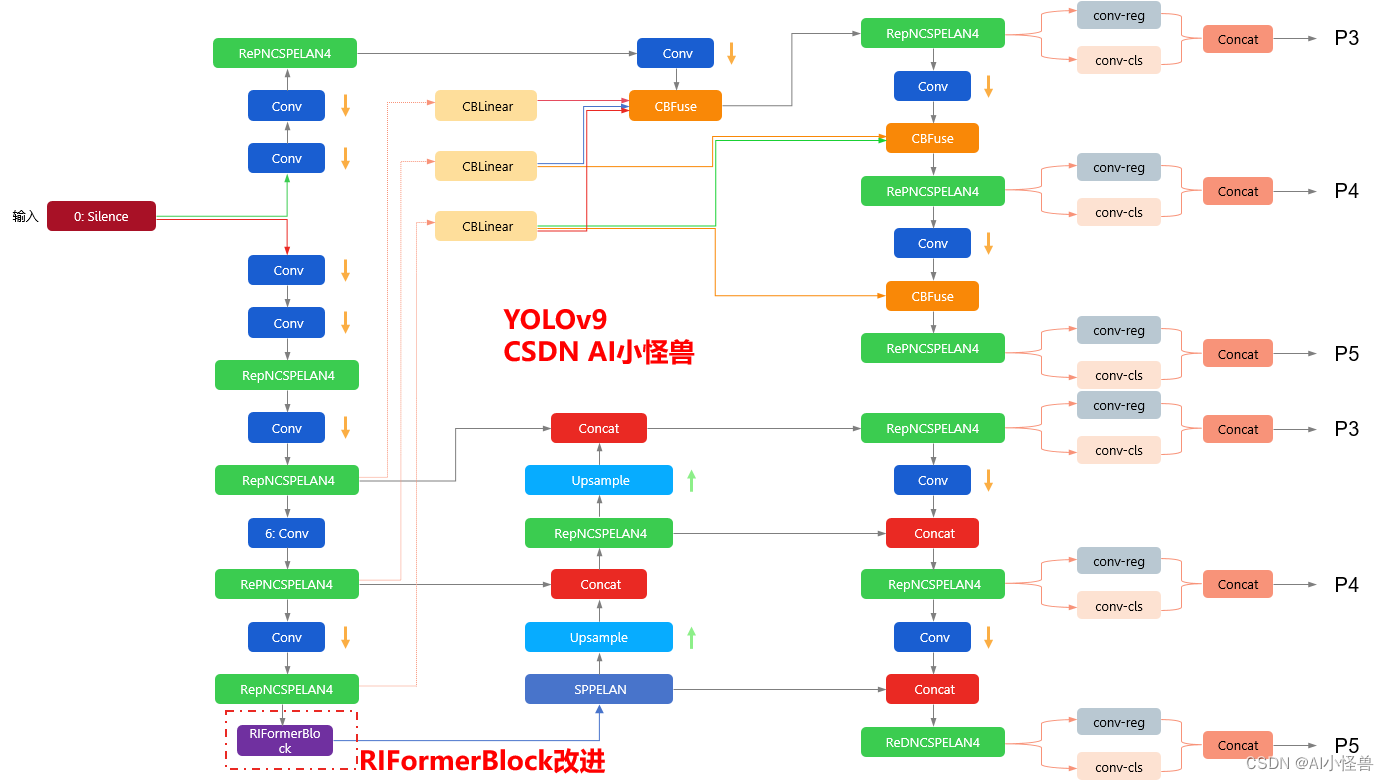
YOLOv9改进策略 :block优化 | 无需TokenMixer也能达成SOTA性能的极简ViT架构 | CVPR2023 RIFormer
💡💡💡本文改进内容: token mixer被验证能够大幅度提升性能,但典型的token mixer为自注意力机制,推理耗时长,计算代价大,而RIFormers是无需TokenMixer也能达成SOTA性能的极简ViT架构 ,在保证性能的同时足够轻量化。 💡💡💡RIFormerBlock引入到YOLOv9,多个数据集验证能够大幅度涨点 改进结构图如下:
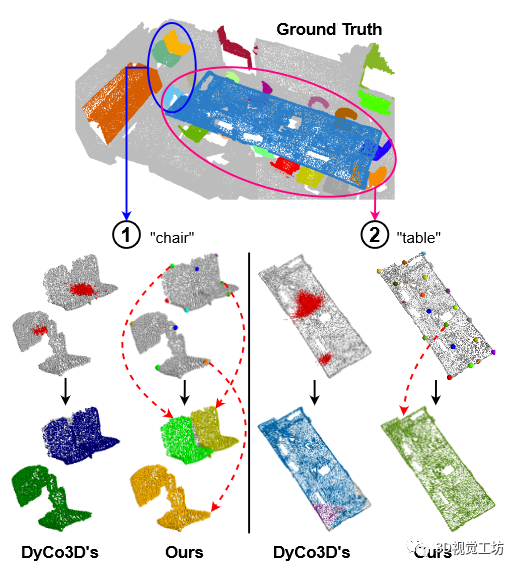
CVPR2023 | 一种不需要点聚类的新颖点云实例分割算法
作者:PCIPG-HAY | 来源:3D视觉工坊 在公众号「3D视觉工坊」后台,回复「原论文」可获取论文pdf和代码链接 添加微信:dddvisiona,备注:3D点云,拉你入群。文末附行业细分群 现有的 3D 实例分割方法以自下而上的设计为主——手动微调算法将点分组为簇,然后是细化网络。然而,由于依赖于聚类的质量,当(1)具有相同语义类的附近对象被打包在一起,或(2)具有松散连接区域的大型

CVPR2023 Highlight | ECON:最新单图穿衣人三维重建SOTA算法
作者:宁了个宁 | 来源:计算机视觉工坊 在公众号「3D视觉工坊」后台,回复「原论文」可获取论文pdf。 添加微信:dddvisiona,备注:三维重建,拉你入群。文末附行业细分群。 图1所示。从彩色图像进行人体数字化。ECON结合了自由形式隐式表示的最佳方面,以及明确的拟人化正则化,以推断高保真度的3D人类,即使是宽松的衣服或具有挑战性的姿势。 0.笔者个人体会 这篇文章讨论

论文阅读: (CVPR2023 SDT )基于书写者风格和字符风格解耦的手写文字生成及源码对应
目录 引言SDT整体结构介绍代码与论文对应搭建模型部分数据集部分 总结 引言 许久不认真看论文了,这不赶紧捡起来。这也是自己看的第一篇用到Transformer结构的CV论文。之所以选择这篇文章来看,是考虑到之前做过手写字体生成的项目。这个工作可以用来合成一些手写体数据集,用来辅助手写体识别模型的训练。本篇文章将从论文与代码一一对应解析的方式来撰写,这样便于找到论文重点地方
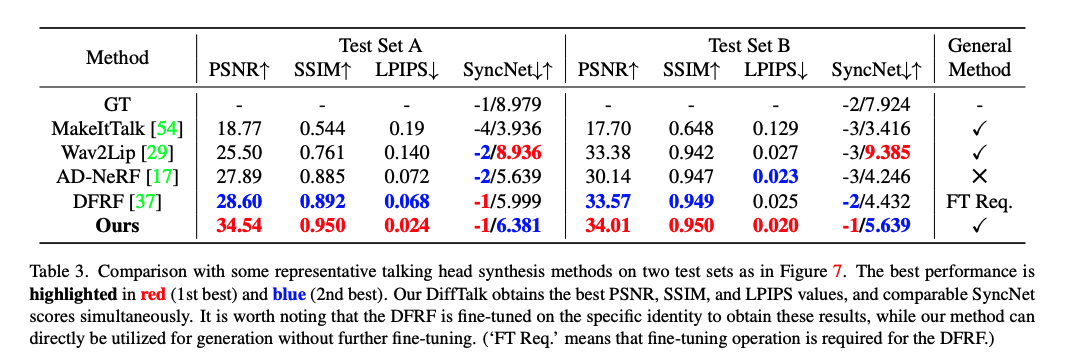
【数字人】9、DiffTalk | 使用扩散模型基于 audio-driven+对应人物视频 合成说话头(CVPR2023)
论文:DiffTalk: Crafting Diffusion Models for Generalized Audio-Driven Portraits Animation 代码:https://sstzal.github.io/DiffTalk/ 出处:CVPR2023 特点:需要音频+对应人物的视频来合成新的说话头视频,嘴部抖动严重 一、背景 talking head 合成任务
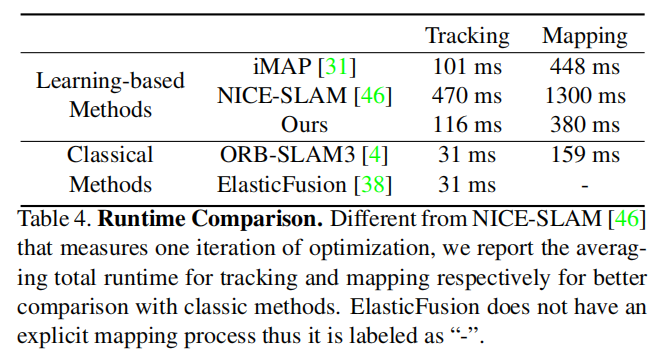
【CVPR2023】使用轻量 ToF 传感器的单目密集SLAM的多模态神经辐射场
目录 导读 本文贡献 本文方法 轻量级ToF传感器的感知原理 多模态隐式场景表示 时间滤波技术 实验 实验结果 消融实验 结论 未来工作 论文标题:Multi-Modal Neural Radiance Field for Monocular Dense SLAM with a Light-Weight ToF Sensor 论文链接:https://ope
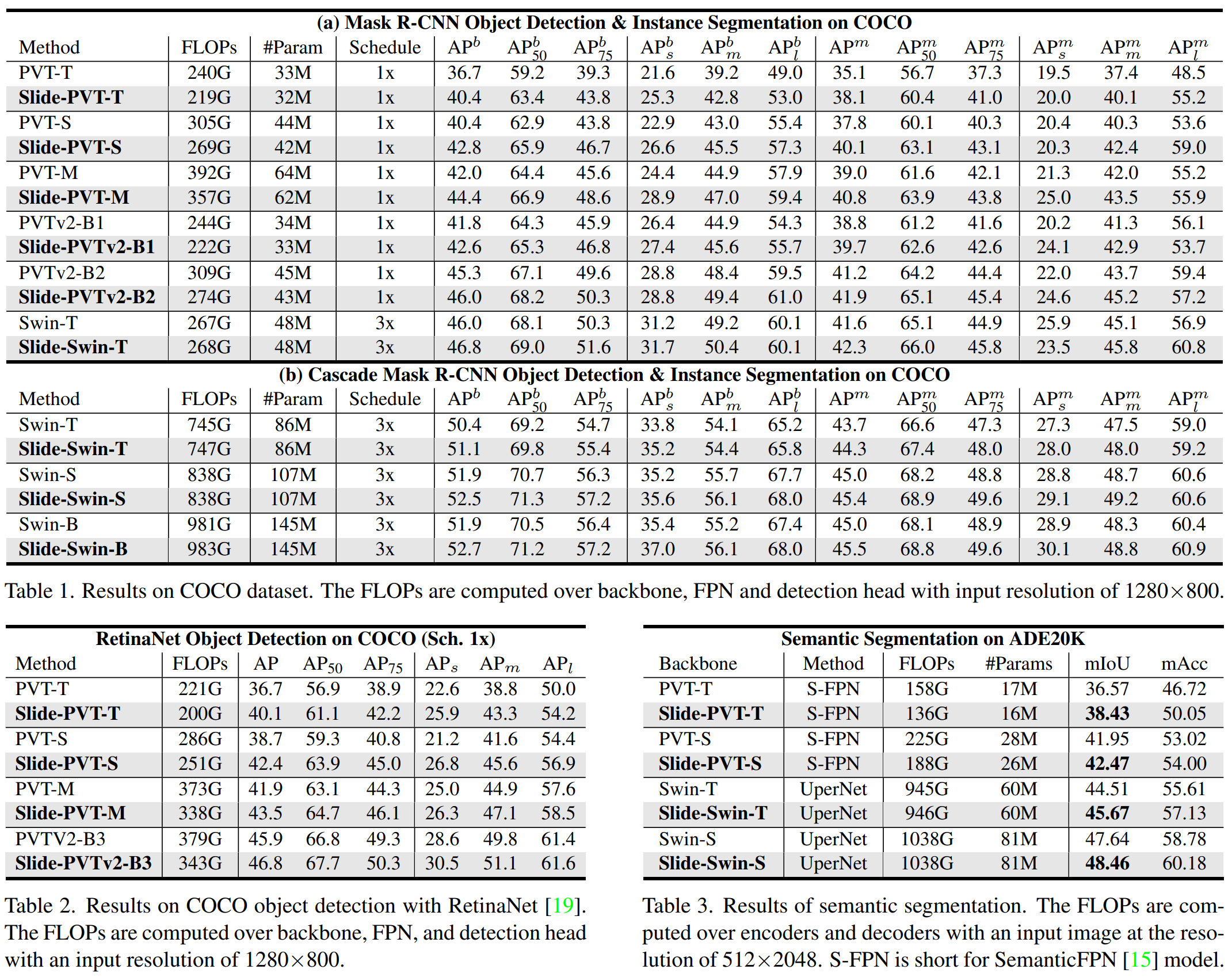
论文阅读——Slide-Transformer(cvpr2023)
Slide-Transformer: Hierarchical Vision Transformer with Local Self-Attention 一、分析 1、改进transformer的几个思路: (1)将全局感受野控制在较小区域,如:PVT,DAT,使用稀疏全局注意力来从特征图选择稀疏的键对值,并且在所有查询中共享它们。 (2)就是Swin Transformer这条窗口注
![[CVPR2023 | GrowSP:无监督3D点云语义分割]](https://img-blog.csdnimg.cn/direct/04b31e4f07f044f8b0497087c117e787.png)
[CVPR2023 | GrowSP:无监督3D点云语义分割]
文章目录 概要引言相关工作方法小结 概要 论文链接:https://arxiv.org/abs/2305.16404 代码链接:https://github.com/vLAR-group/GrowSP 本文的研究主要关注点云的三维语义分割问题。与目前主要依赖于人工注释数据训练神经网络的方法不同,本文提出了一种全新的无监督方法,名为GrowSP。该方法能够成功地识别3D场景中

论文阅读——Mask DINO(cvpr2023)
DINO是检测,Mask DINO是检测+分割。 几个模型对比: 传统的检测+分割中,检测头和分割头是平行的,Mask DINO使用二分图匹配bipartite matching提高匹配结果的准确性。 box对大的类别不计算损失,因为太大了,会带坏模型。模型一样预测,但是损失取其他类别的平均数。 Backbone:ResNet-50 and SwinL,SwinL SOTA
论文阅读——Mask DINO(cvpr2023)
DINO是检测,Mask DINO是检测+分割。 几个模型对比: 传统的检测+分割中,检测头和分割头是平行的,Mask DINO使用二分图匹配bipartite matching提高匹配结果的准确性。 box对大的类别不计算损失,因为太大了,会带坏模型。模型一样预测,但是损失取其他类别的平均数。 Backbone:ResNet-50 and SwinL,SwinL SOTA

论文阅读——Img2LLM(cvpr2023)
arxiv:[2212.10846] From Images to Textual Prompts: Zero-shot VQA with Frozen Large Language Models (arxiv.org) 一、介绍 使用大语言模解决VQA任务的方法大概两种:multi-modal pretraining and language-mediated VQA,即多模态预训练的方法和
论文阅读——Img2LLM(cvpr2023)
arxiv:[2212.10846] From Images to Textual Prompts: Zero-shot VQA with Frozen Large Language Models (arxiv.org) 一、介绍 使用大语言模解决VQA任务的方法大概两种:multi-modal pretraining and language-mediated VQA,即多模态预训练的方法和
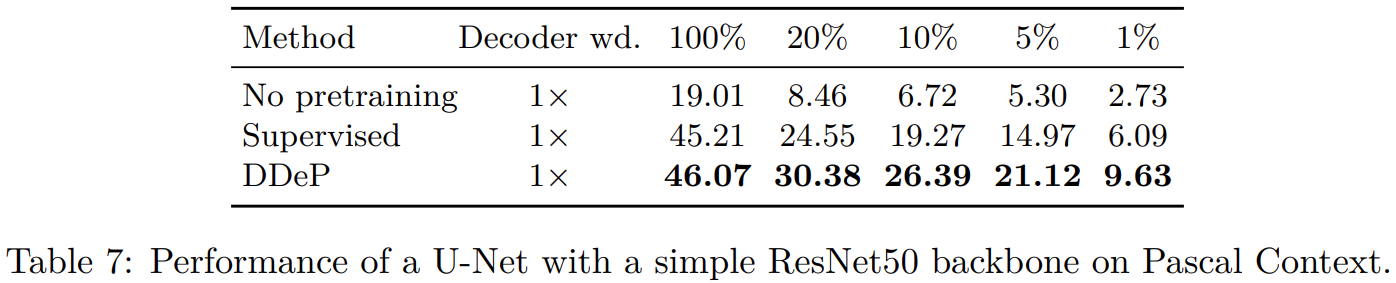
论文阅读——DDeP(cvpr2023)
分割标签耗时且贵,所以常常使用预训练提高分割模型标签有效性,反正就是,需要一个预训练分割模型。典型的分割模型encoder部分通过分类任务预训练,decoder部分参数随机初始化。作者认为这个方法次优,尤其标签比较少的情况。 于是提出可以和监督学习encoder结合的基于去噪denoising的decoder预训练方法。当标签少的时候这个方法表现很好,超过监督学习。 所以整个方法就是,

CVPR2023 I 一种实用的智能眼镜深度感知系统
论文题目:A Practical Stereo Depth System for Smart Glasses 作者:Jialiang Wang ;Daniel Scharstein; Akash Bapat等人 作者机构:Meta(美国扎克伯格的公司);adobe(photoshop等软件开发公司) 在公众号「3D视觉工坊」后台回复「原论文」,可获取对应论文pdf文件。 本文提出了一种生产
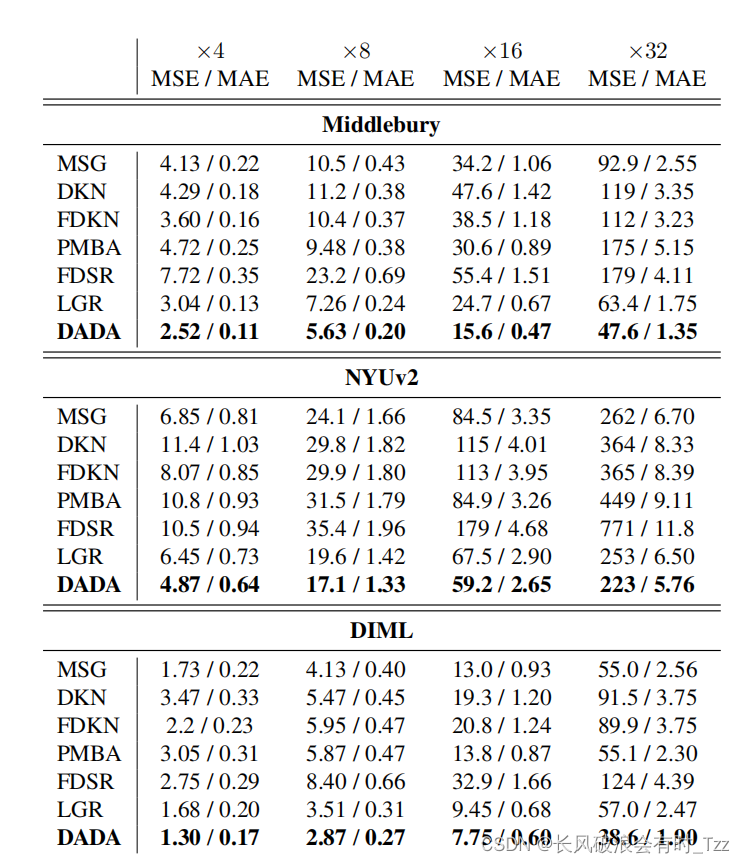
CVPR2023_Guided Depth Super-Resolution by Deep Anisotropic Diffusion 论文阅读记录_4
论文原文:https://arxiv.org/abs/2211.11592v2 摘要与引言 网络模型的上下文推理能力可以增强扩散模型的边缘增强特性。 调整步骤使得生成的图像与原始图像类似。 方法 整体网络框架如下图所示: 扩散权值是从引导图像上计算的,从而实现引导图像对原始图像的限制。 扩散模型可能会导致深度图像边界区分不明显,即生成的深度图较为平滑,本文提出的方法是想利用彩色信息限
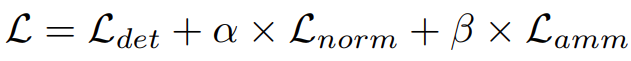
论文阅读—— CEASC(cvpr2023)
arxiv:https://arxiv.org/abs/2303.14488 github:https://github.com/Cuogeihong/CEASC 为了进一步减轻SC中的信息损失,使训练过程更加稳定,我们在训练过程中除了稀疏卷积之外,还保持了正常的密集卷积,生成了在全输入特征图上卷积的特征图。然后,我们使用来通过将MSE损失优化为来增强稀疏特征图
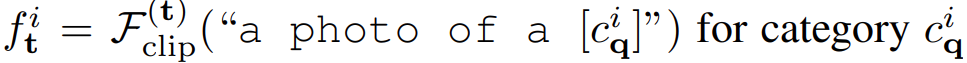
论文阅读——What Can Human Sketches Do for Object Detection?(cvpr2023)
论文:https://openaccess.thecvf.com/content/CVPR2023/papers/Chowdhury_What_Can_Human_Sketches_Do_for_Object_Detection_CVPR_2023_paper.pdf 代码:What Can Human Sketches Do for Object Detection? (pinakinathc
论文阅读—— CEASC(cvpr2023)
arxiv:https://arxiv.org/abs/2303.14488 github:https://github.com/Cuogeihong/CEASC 为了进一步减轻SC中的信息损失,使训练过程更加稳定,我们在训练过程中除了稀疏卷积之外,还保持了正常的密集卷积,生成了在全输入特征图上卷积的特征图。然后,我们使用来通过将MSE损失优化为来增强稀疏特征图

【论文阅读】CVPR2023 IGEV-Stereo
用于立体匹配的迭代几何编码代价体 【cvhub导读】【paper】【code_openi】 代码是启智社区的镜像仓库,不需要魔法,点击这里注册 🚀贡献 1️⃣现有主流方法 基于代价滤波的方法和基于迭代优化的方法: 基于代价滤波的方法可以在cost volume中编码足够的非局部几何和上下文信息,这对于具有挑战性的区域中的视差预测至关重要。 基于迭代优化的方法可以避免进行3D
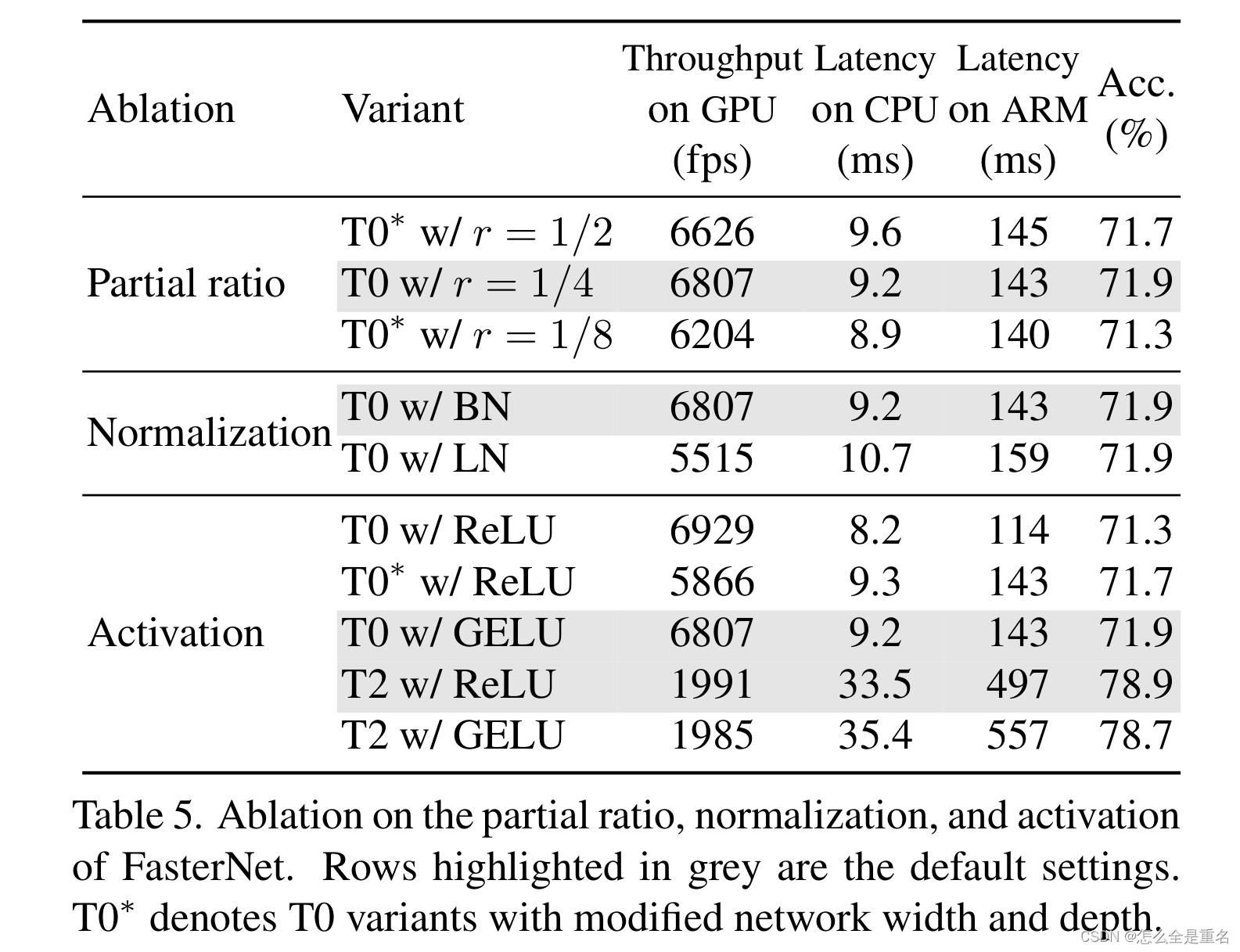
Run, Don‘t Walk: Chasing Higher FLOPS for Faster Neural Networks(CVPR2023)
文章目录 AbstractIntroduction过去工作存在的不足我们的工作主要贡献(待参考) Related workCNNViT, MLP, and variants Design of PConv and FasterNetPreliminaryPartial convolution as a basic operatorPConv followed by PWConvFaster