columns专题

Oracle - ORA-01789: Query block has incorrect number of result columns
一、原因 这个错误一般是在执行表之间的相加(union),相减(minus)等SQL语句时,两个个查询块具有不一致的结果列数所导致的。 二、方案 只要将两段SQL语句的列数调整为一致就可以解决。使用union时,要注意数据库字段的格式要一致,如varchar和nvarchar是不一样的。

vben admin里面换行useTable里面的columns
{title: '标题',dataIndex: 'systemName',width: 300, minWidth: 300,customRender: ({ text }: { text: string }) => {return `${text}`;},}, customRender: ({ text }: { text: string }) => { retu
生成列(Generated Columns)概述
生成列(Generated Columns)是数据库表中的一种特殊列,它的值不是直接存储的,而是根据其他列的值计算得出的。生成列可以是虚拟列(Virtual Column)或存储列(Stored Column),根据实际需求来选择。生成列在某些场景下可以简化数据处理逻辑并提高查询效率,特别是当需要频繁计算某个值时。 生成列的类型 虚拟列(Virtual Column): 特点:虚拟列的值不会
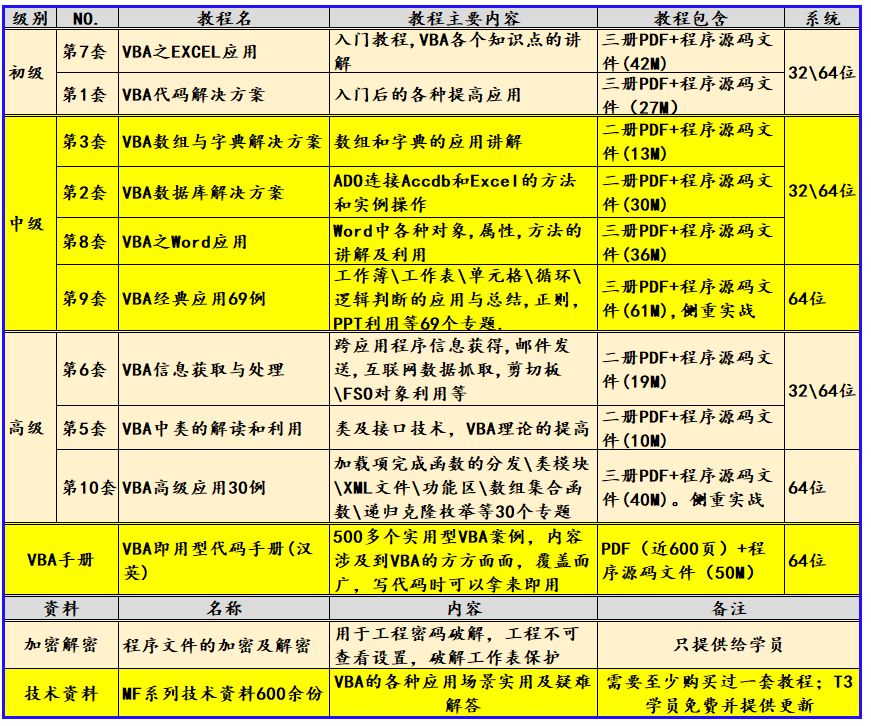
VBA即用型代码手册:删除空列Delete Empty Columns
我给VBA下的定义:VBA是个人小型自动化处理的有效工具。可以大大提高自己的劳动效率,而且可以提高数据的准确性。我这里专注VBA,将我多年的经验汇集在VBA系列九套教程中。 作为我的学员要利用我的积木编程思想,积木编程最重要的是积木如何搭建及拥有积木。在九套教程中我给出了大量的积木,同时讲解了如何搭建。为了让学员拥有更多的积木,我开始着手这部《VBA即用型代码手册(汉英)》的创作,这部手册约60
![[Pandas error]sys:1: DtypeWarning: Columns (0,1) have mixed types. Specify dtype option on import or](/front/images/it_default2.jpg)
[Pandas error]sys:1: DtypeWarning: Columns (0,1) have mixed types. Specify dtype option on import or
要把这个 low_memory 关掉df = pd.read_csv('somefile.csv', low_memory=False)

PowerDesign中设置Columns的default值
A:选中需要修改的表=》双击=》切换到Columns B:选这需要设置default的列=》双击 C:切换到Standard Checks D:到Default框中设置默认值

Hive ,At least 1 group must only depend on input columns. Also check for circular dependencies.
使用rank()排序报错: 2019-04-28 09:35:08,100 FAILED: SemanticException Failed to breakup Windowing invocations into Groups. At least 1 group must only depend on input columns. Also check for circular depend
Python报错You are trying to merge on object and int64 columns.
代码截取 result= pd.read_excel('D:/1日常工作内容/每日销售开发业绩(Python)/20200302/配置信息/ebay.xlsx')result_saleid = pd.read_csv('D:/1日常工作内容/每日销售开发业绩(Python)/20200302/配置信息/ID.csv',encoding='gbk')result_id=result
使用columns简单实现瀑布流、分栏、自适应布局和响应式布局、媒体查询、单位(px em rem)的区别、VW与VH介绍、vw/vh和百分比%的区别、怪异盒子模型——移动端入门知识点
目录 一、分栏 使用columns简单实现瀑布流 二、自适应布局和响应式布局 三、媒体查询 四、单位(px em rem) em与rem的区别 VW与VH介绍 vw/vh和百分比%的区别: 五、盒子模型 一、分栏 1、列宽度 语法:column-width column-width: 200px;/* 栏宽 列宽 */ 2、列数 语法:co

mysql分区遇到问题,A PRIMARY KEY must include all columns in the table's partitioning function
当使用MySql的分区时偶尔遇到问题, 当有主键的表时会出现, A PRIMARY KEY must include all columns in the table's partitioning function。 分区的字段必须是要包含在主键当中。这时候分区的字段要么是主键,要么把分区字段加入到主键中,从而形成复合主键。 不过现在的数据表大部分都有主键。当没有主键的时候不会出现。 C

CSS之Multi-columns的column-gap和column-rule
column-gap就相当于两列之间的空白处,而column-rule就相当于一条分隔线,换句话说呢?column-gap就像我们web页面中的margin一样,而column-rule就类似于border,不过他们只是存在相邻两列之间 另外column-gap和column-rule是有高度的,其高度和列等高,最大区别是,column-gap没有任何样式,而且他在列与列之间占有一定的空间,而c
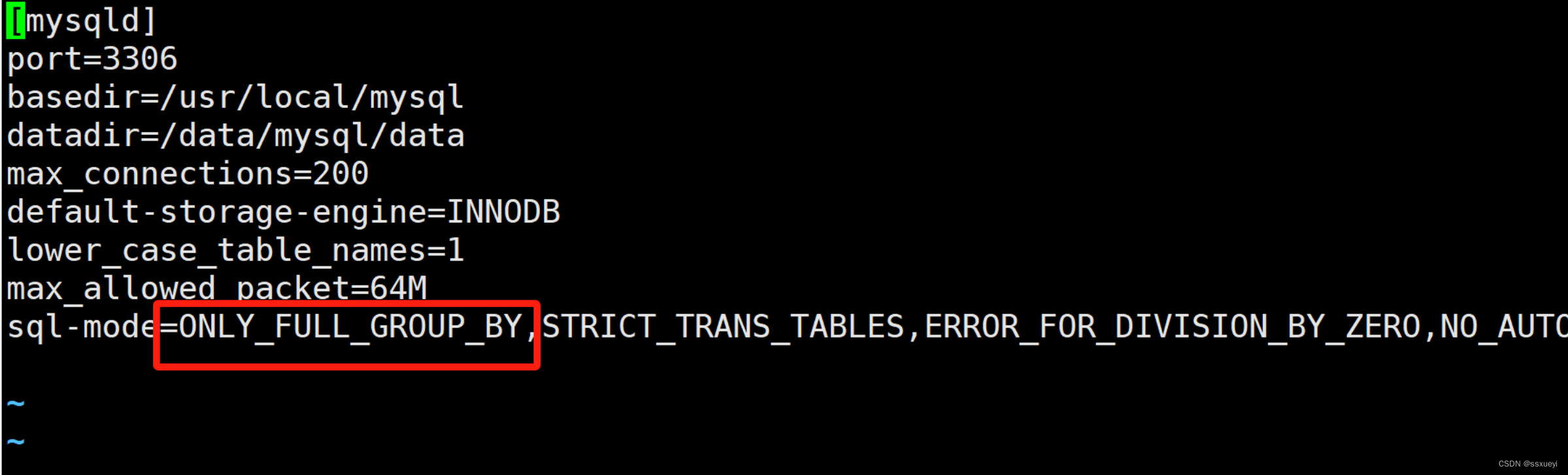
which is not functionally dependent on columns in GROUP BY clause 错误解决方法
今天遇到了which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by的错误,记录一下解决方法。 该错误是因为在SQL语句中用到了聚合函数,但是聚合函数之外的字段没有全部放到group by里面,解决办法有2种: 1
Oracle利用Sequence和触发器Trigger实现Columns的Default自动编号(标识)
Create SEQUENCE SEQUENCE名称 MINVALUE 1 MAXVALUE 1.0E28 Start With 1 INCREMENT By 1 CACHE 20; Create or Replace Trigger 触发器名 Before Insert On 表 For Each Row
MySQL INFORMATION_SCHEMA -- COLUMNS Table
INFORMATION_SCHEMA 库中,存储了与这个数据库server有关的信息,比如库中所有table的表信息、所有字段的表信息、访问权限等等。 所有字段的信息保存在 COLUMNS 这个表中: INFORMATION_SCHEMA Name SHOW Name Remarks TABLE_CATALOG def TABLE_SCHEMA TABLE_N

【跟着stackoverflow学Pandas】Renaming columns in pandas-列的重命名
最近做一个系列博客,跟着stackoverflow学Pandas。 专栏地址:http://blog.csdn.net/column/details/16726.html 以 pandas作为关键词,在stackoverflow中进行搜索,随后安照 votes 数目进行排序: https://stackoverflow.com/questions/tagged/pandas?sort=vote
升级版本彻底解决bootstrap-table-fixed-columns固定列后行对不齐问题
升级到bootstrap-table和bootstrap-table-fixed-columns版本都升级到v1.22.3版本以上,即可解决该问题 bootstrap-table:bootstrap-table/dist/bootstrap-table.min.css at develop · wenzhixin/bootstrap-table · GitHub bootstrap-table
C++、MFC中操作excel时,CRange中get_Rows()、get_Columns()及get_Count()函数的用法及区别是什么?
在C++、MFC中操作Excel时,CRange类中的get_Rows()、get_Columns()和get_Count()函数都是用于获取指定范围的行数、列数或单元格数量的函数,但它们的具体用法和区别如下: get_Rows() 用法:LPDISPATCH get_Rows();功能:返回一个 Range 对象,它表示指定区域中的行。示例代码:CRange range;LPDISPATC
如何在logstash的配置文件里边删除csv中columns中多余的field字段
当采集数据时生成的csv的文件,但是发现采集表数据有些在es中不需要,这时,可以在filter插件中的csv中,使用remove_field => [ "filed1","filed2" ]来删除多余字段 input { file { path => [ "/test/111.csv" ]
how-to-lock-columns-in-an-html-table
固定 table 列 scroll [url]http://www.disconova.com/open_source/files/freezepanes.htm[/url] [url]http://ajaxian.com/archives/freeze-pane-functionality[/url] [url]http://www.webmaster-talk.com/c
MySQL笔记-information_schema库中COLUMNS表的一些笔记
mysql建表中可以添加comment,也就是注释,这些注释会写到information_schema库的COLUMNS表中,可以使用如下SQL语句进行查询: SELECT COLUMN_NAME, COLUMN_COMMENTFROM information_schema.COLUMNSWHERE TABLE_SCHEMA = 'your_database_name'AND TABLE_N
R语言【cli】——ansi_columns():把字符向量格式化为多个列
Package cli version 3.6.0 Description 这个函数有助于ANSI样式字符串的多列输出。它可以很好地与boxx()一起工作。 Usage ansi_columns(text,width = console_width(),sep = " ",fill = c("rows", "cols"),max_cols = 4,align = c("lef
存储过程导出表中T-SQL数据语句[insert into table(columns) values(...)]
存储过程(不需修改,直接运行): CREATE PROCEDURE dbo.UspOutputData @tablename sysname AS declare @column varchar(1000) declare @columndata varchar(1000) declare @sql varcha
![ValueError: You are trying to merge on datetime64[ns] and object columns. If you wish to proceed you](https://img-blog.csdnimg.cn/92a89f24e6d44eafa59993e1ddf071f3.png)
ValueError: You are trying to merge on datetime64[ns] and object columns. If you wish to proceed you
问题 python读取的csv文件的某一列是时间,把datetime列转换为datetime类型。 问题示例 —情景:按时间索引ts,用merge横向合并两个dataframe,报错: ValueError: You are trying to merge on datetime64[ns] and object columns. If you wish to proceed you sh
[Err] 1222 - The used SELECT statements have a different number of columns
参考:https://blog.csdn.net/wu920604/article/details/82691563

【postgresql】ERROR: INSERT has more expressions than target columns
执行下面sql insert into apply_account_cancellation3 select * from pply_account_cancellation; 返回下面错误信息 insert into apply_account_cancellation3 select * from apply_account_cancellation > ERROR: INS
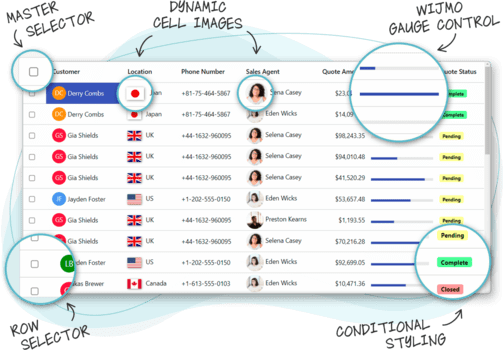
Keep Important Columns Visible in React Grids
Keep Important Columns Visible in React Grids November 27, 2023 Implement column freezing functionality to ensure visibility even when users scroll horizontally through large grids. Locked colu